 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression-aware Training of Neural Networks using Frank-Wolfe
Paper and Code
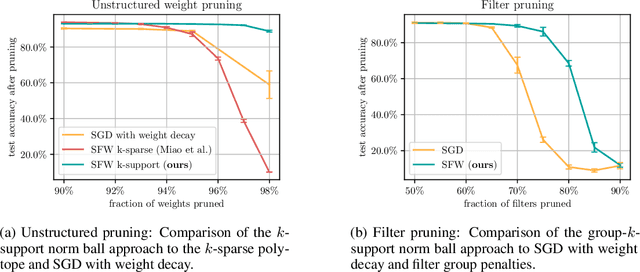

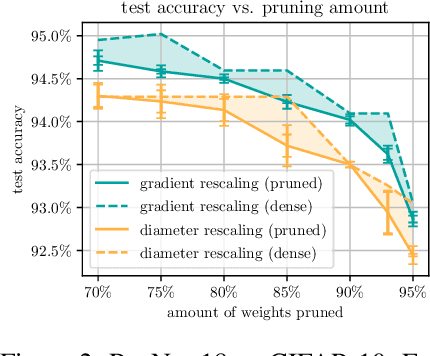

Many existing Neural Network pruning approaches either rely on retraining to compensate for pruning-caused performance degradation or they induce strong biases to converge to a specific sparse solution throughout training. A third paradigm obtains a wide range of compression ratios from a single dense training run while also avoiding retraining. Recent work of Pokutta et al. (2020) and Miao et al. (2022) suggests that the Stochastic Frank-Wolfe (SFW) algorithm is particularly suited for training state-of-the-art models that are robust to compression. We propose leveraging $k$-support norm ball constraints and demonstrate significant improvements over the results of Miao et al. (2022) in the case of unstructured pruning. We also extend these ideas to the structured pruning domain and propose novel approaches to both ensure robustness to the pruning of convolutional filters as well as to low-rank tensor decompositions of convolutional layers. In the latter case, our approach performs on-par with nuclear-norm regularization baselines while requiring only half of the computational resources. Our findings also indicate that the robustness of SFW-trained models largely depends on the gradient rescaling of the learning rate and we establish a theoretical foundation for that practice.