 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Network Training with Frank-Wolfe
Paper and Code
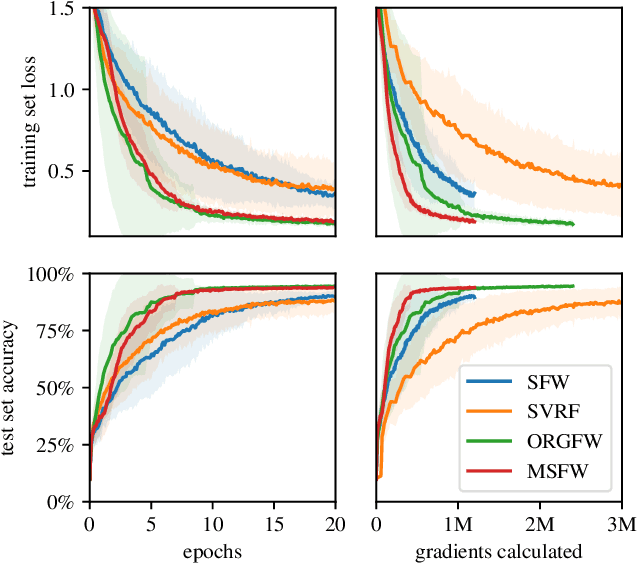

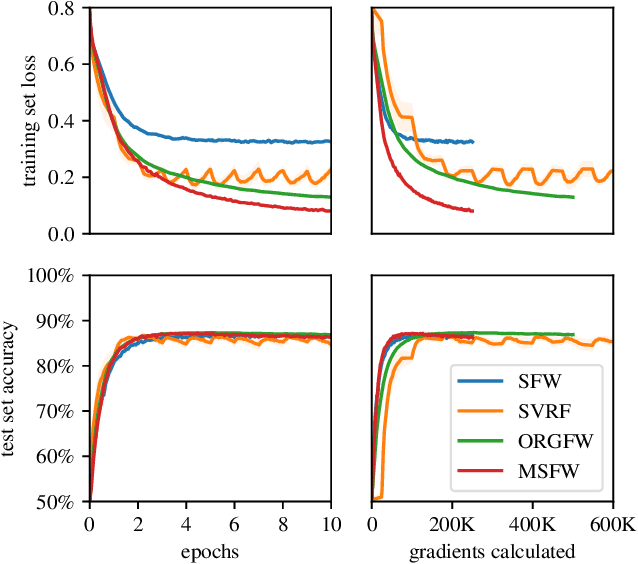

This paper studies the empirical efficacy and benefits of using projection-free first-order methods in the form of Conditional Gradients, a.k.a. Frank-Wolfe methods, for training Neural Networks with constrained parameters. We draw comparisons both to current state-of-the-art stochastic Gradient Descent methods as well as across different variants of stochastic Conditional Gradients. In particular, we show the general feasibility of training Neural Networks whose parameters are constrained by a convex feasible region using Frank-Wolfe algorithms and compare different stochastic variants. We then show that, by choosing an appropriate region, one can achieve performance exceeding that of unconstrained stochastic Gradient Descent and matching state-of-the-art results relying on $L^2$-regularization. Lastly, we also demonstrate that, besides impacting performance, the particular choice of constraints can have a drastic impact on the learned representations.