 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Learned Sketches for Randomized Numerical Linear Algebra
Paper and Code
Jul 20, 2020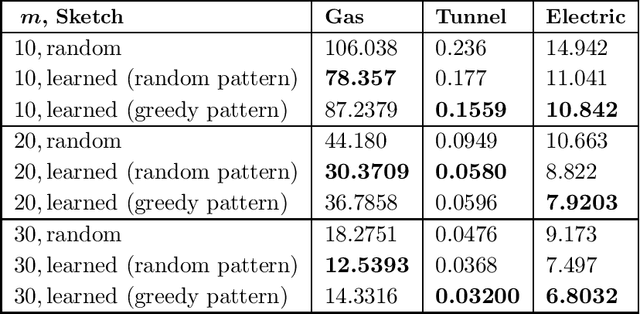

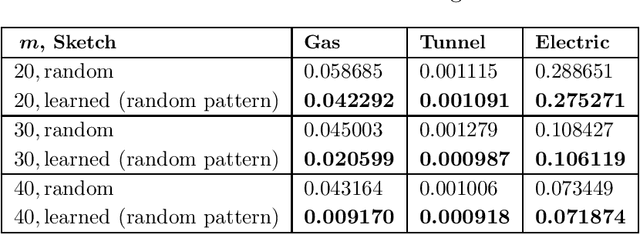

We study "learning-based" sketching approaches for diverse tasks in numerical linear algebra: least-squares regression, $\ell_p$ regression, Huber regression, low-rank approximation (LRA), and $k$-means clustering. Sketching methods are used to quickly and approximately compute properties of large matrices. Linear maps called "sketches" are applied to compress data, and these concise representations are used to compute the desired properties. Specifically, we consider sparse sketches (such as CountSketch). Recent works have dealt with optimizing sketches for data distributions to perform better than their random counterparts. We extend this theme to several important and ubiquitous tasks, each of which requires a new analysis and novel practical methods. Specifically, our contributions are: 1) For all tasks, we introduce fast algorithms using learned sketches with worst-case guarantees. We give a simple task-agnostic method for retaining the worst-case guarantees of randomized sketching, which yields time-optimal algorithms for LRA and least-squares regression. Also, for $k$-means clustering, we give a faster alternative for retaining worst-case guarantees. 2) We show empirically that learned sketches are reliable in improving approximation accuracy, with comparison against "non-learned" sketching baselines. 3) We introduce a greedy algorithm for optimizing the location of the nonzero entries of a sparse sketch and prove guarantees for certain distributions on the LRA task. Previous work only looked at optimizing the values rather than the locations. Also, we show empirically that it further improves learned sketch performance.