 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Reinforcement Learning with Probabilistic Control Barrier Functions for Ramp Merging
Dec 01, 2022



Prior work has looked at applying reinforcement learning and imitation learning approaches to autonomous driving scenarios, but either the safety or the efficiency of the algorithm is compromised. With the use of control barrier functions embedded into the reinforcement learning policy, we arrive at safe policies to optimize the performance of the autonomous driving vehicle. However, control barrier functions need a good approximation of the model of the car. We use probabilistic control barrier functions as an estimate of the model uncertainty. The algorithm is implemented as an online version in the CARLA (Dosovitskiy et al., 2017) Simulator and as an offline version on a dataset extracted from the NGSIM Database. The proposed algorithm is not just a safe ramp merging algorithm but a safe autonomous driving algorithm applied to address ramp merging on highways.
Imitating Past Successes can be Very Suboptimal
Jun 07, 2022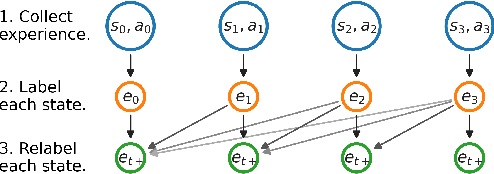
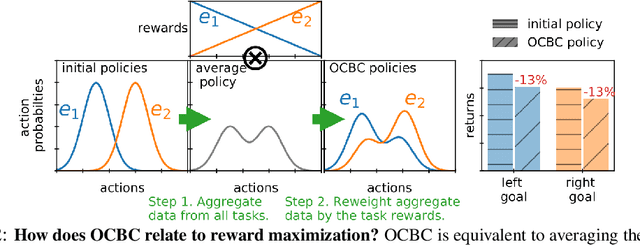
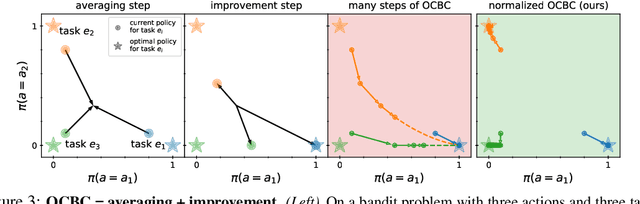
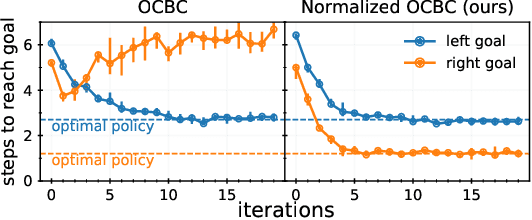
Prior work has proposed a simple strategy for reinforcement learning (RL): label experience with the outcomes achieved in that experience, and then imitate the relabeled experience. These outcome-conditioned imitation learning methods are appealing because of their simplicity, strong performance, and close ties with supervised learning. However, it remains unclear how these methods relate to the standard RL objective, reward maximization. In this paper, we prove that existing outcome-conditioned imitation learning methods do not necessarily improve the policy; rather, in some settings they can decrease the expected reward. Nonetheless, we show that a simple modification results in a method that does guarantee policy improvement, under some assumptions. Our aim is not to develop an entirely new method, but rather to explain how a variant of outcome-conditioned imitation learning can be used to maximize rewards.