 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrans-defense: Transformer-based Denoiser for Adversarial Defense with Spatial-Frequency Domain Representation
Oct 31, 2025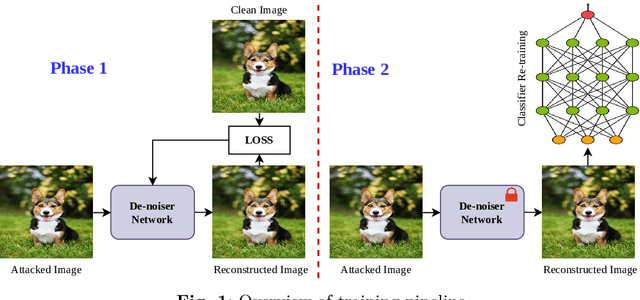
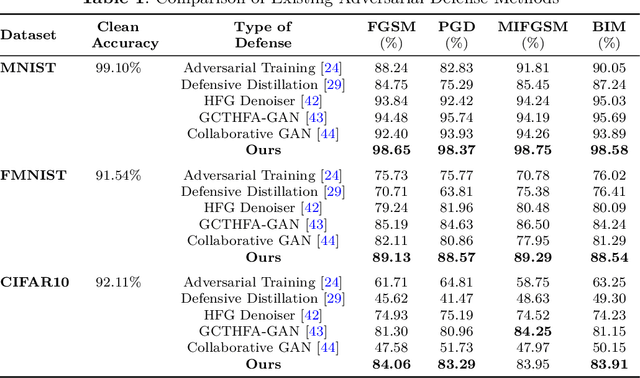
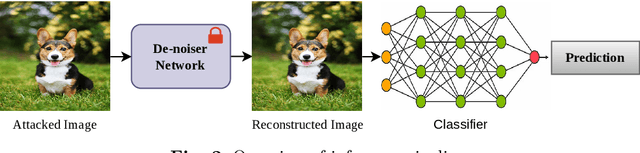

In recent times, deep neural networks (DNNs) have been successfully adopted for various applications. Despite their notable achievements, it has become evident that DNNs are vulnerable to sophisticated adversarial attacks, restricting their applications in security-critical systems. In this paper, we present two-phase training methods to tackle the attack: first, training the denoising network, and second, the deep classifier model. We propose a novel denoising strategy that integrates both spatial and frequency domain approaches to defend against adversarial attacks on images. Our analysis reveals that high-frequency components of attacked images are more severely corrupted compared to their lower-frequency counterparts. To address this, we leverage Discrete Wavelet Transform (DWT) for frequency analysis and develop a denoising network that combines spatial image features with wavelets through a transformer layer. Next, we retrain the classifier using the denoised images, which enhances the classifier's robustness against adversarial attacks. Experimental results across the MNIST, CIFAR-10, and Fashion-MNIST datasets reveal that the proposed method remarkably elevates classification accuracy, substantially exceeding the performance by utilizing a denoising network and adversarial training approaches. The code is available at https://github.com/Mayank94/Trans-Defense.
MV2MAE: Multi-View Video Masked Autoencoders
Jan 29, 2024Videos captured from multiple viewpoints can help in perceiving the 3D structure of the world and benefit computer vision tasks such as action recognition, tracking, etc. In this paper, we present a method for self-supervised learning from synchronized multi-view videos. We use a cross-view reconstruction task to inject geometry information in the model. Our approach is based on the masked autoencoder (MAE) framework. In addition to the same-view decoder, we introduce a separate cross-view decoder which leverages cross-attention mechanism to reconstruct a target viewpoint video using a video from source viewpoint, to help representations robust to viewpoint changes. For videos, static regions can be reconstructed trivially which hinders learning meaningful representations. To tackle this, we introduce a motion-weighted reconstruction loss which improves temporal modeling. We report state-of-the-art results on the NTU-60, NTU-120 and ETRI datasets, as well as in the transfer learning setting on NUCLA, PKU-MMD-II and ROCOG-v2 datasets, demonstrating the robustness of our approach. Code will be made available.
StopNet: Scalable Trajectory and Occupancy Prediction for Urban Autonomous Driving
Jun 02, 2022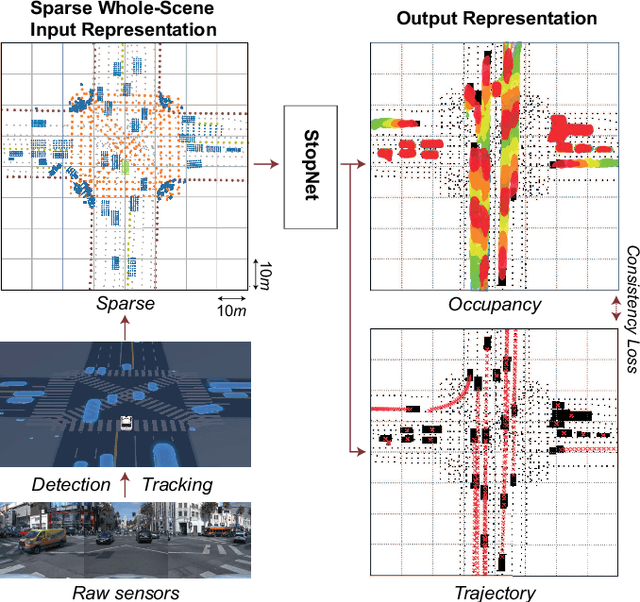
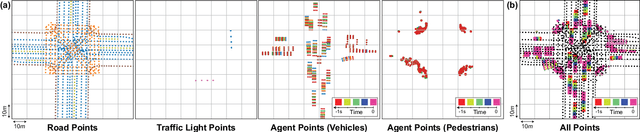
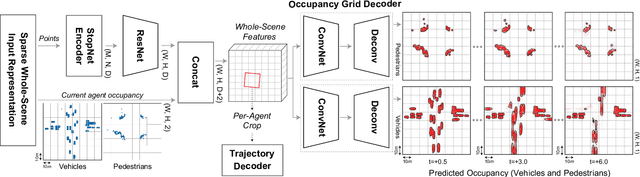
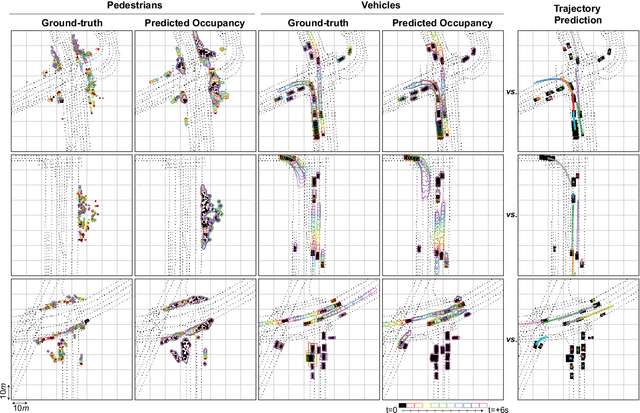
We introduce a motion forecasting (behavior prediction) method that meets the latency requirements for autonomous driving in dense urban environments without sacrificing accuracy. A whole-scene sparse input representation allows StopNet to scale to predicting trajectories for hundreds of road agents with reliable latency. In addition to predicting trajectories, our scene encoder lends itself to predicting whole-scene probabilistic occupancy grids, a complementary output representation suitable for busy urban environments. Occupancy grids allow the AV to reason collectively about the behavior of groups of agents without processing their individual trajectories. We demonstrate the effectiveness of our sparse input representation and our model in terms of computation and accuracy over three datasets. We further show that co-training consistent trajectory and occupancy predictions improves upon state-of-the-art performance under standard metrics.
Attentional Bottleneck: Towards an Interpretable Deep Driving Network
May 08, 2020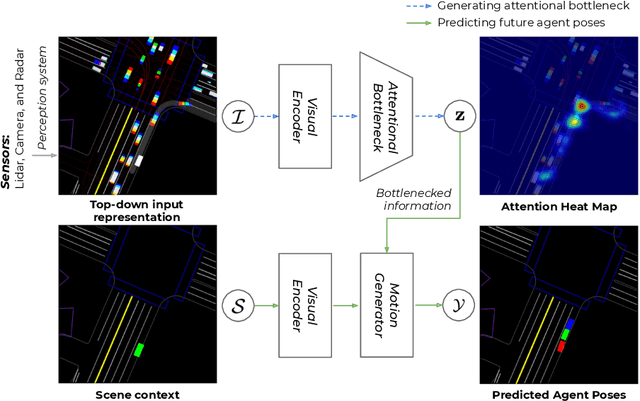
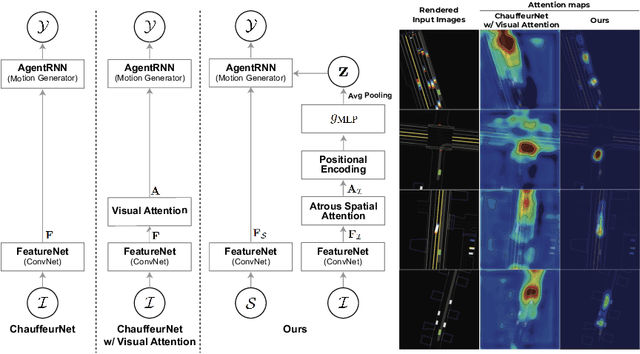

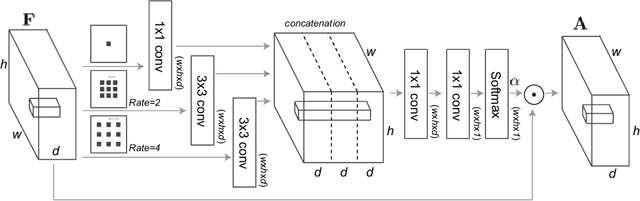
Deep neural networks are a key component of behavior prediction and motion generation for self-driving cars. One of their main drawbacks is a lack of transparency: they should provide easy to interpret rationales for what triggers certain behaviors. We propose an architecture called Attentional Bottleneck with the goal of improving transparency. Our key idea is to combine visual attention, which identifies what aspects of the input the model is using, with an information bottleneck that enables the model to only use aspects of the input which are important. This not only provides sparse and interpretable attention maps (e.g. focusing only on specific vehicles in the scene), but it adds this transparency at no cost to model accuracy. In fact, we find slight improvements in accuracy when applying Attentional Bottleneck to the ChauffeurNet model, whereas we find that the accuracy deteriorates with a traditional visual attention model.
MultiPath: Multiple Probabilistic Anchor Trajectory Hypotheses for Behavior Prediction
Oct 12, 2019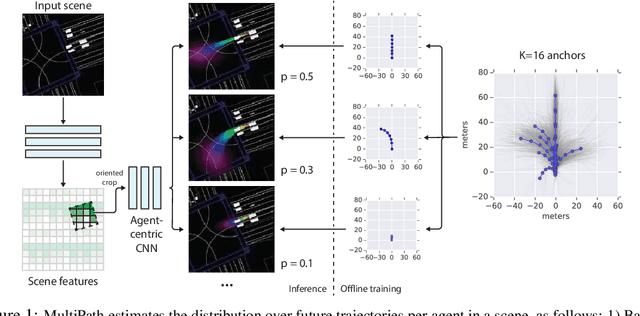
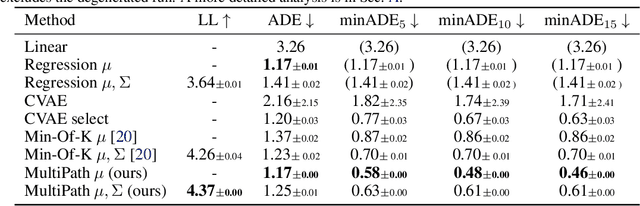
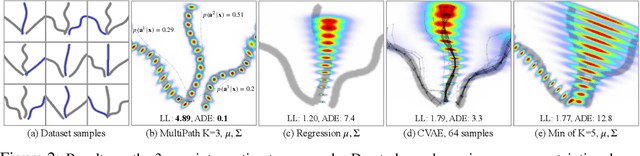
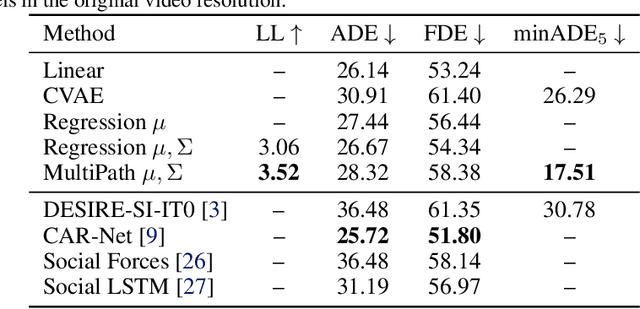
Predicting human behavior is a difficult and crucial task required for motion planning. It is challenging in large part due to the highly uncertain and multi-modal set of possible outcomes in real-world domains such as autonomous driving. Beyond single MAP trajectory prediction, obtaining an accurate probability distribution of the future is an area of active interest. We present MultiPath, which leverages a fixed set of future state-sequence anchors that correspond to modes of the trajectory distribution. At inference, our model predicts a discrete distribution over the anchors and, for each anchor, regresses offsets from anchor waypoints along with uncertainties, yielding a Gaussian mixture at each time step. Our model is efficient, requiring only one forward inference pass to obtain multi-modal future distributions, and the output is parametric, allowing compact communication and analytical probabilistic queries. We show on several datasets that our model achieves more accurate predictions, and compared to sampling baselines, does so with an order of magnitude fewer trajectories.
ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst
Dec 07, 2018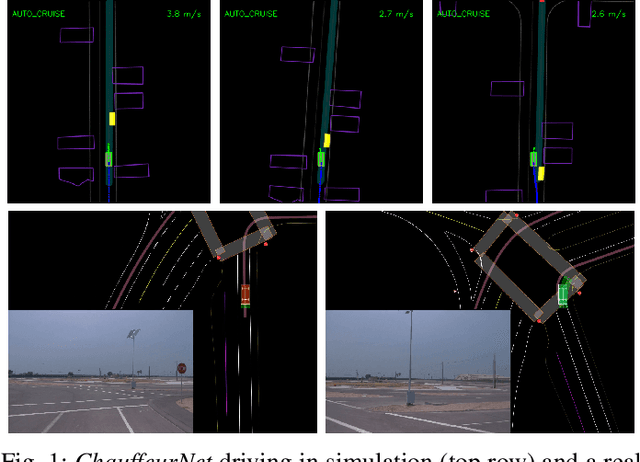

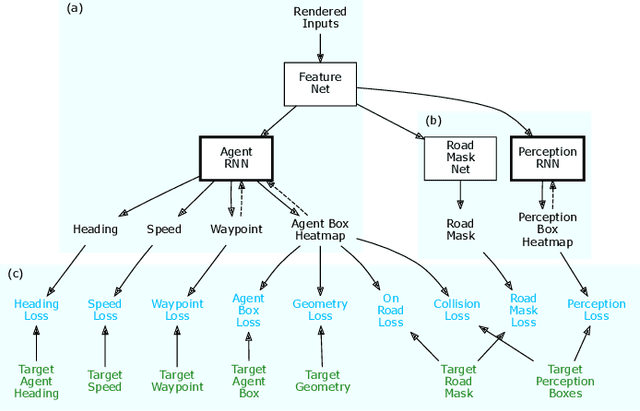
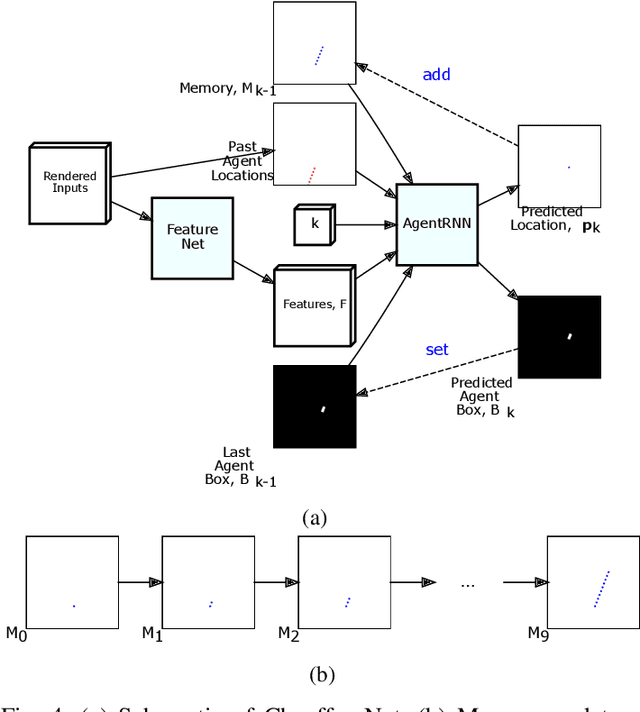
Our goal is to train a policy for autonomous driving via imitation learning that is robust enough to drive a real vehicle. We find that standard behavior cloning is insufficient for handling complex driving scenarios, even when we leverage a perception system for preprocessing the input and a controller for executing the output on the car: 30 million examples are still not enough. We propose exposing the learner to synthesized data in the form of perturbations to the expert's driving, which creates interesting situations such as collisions and/or going off the road. Rather than purely imitating all data, we augment the imitation loss with additional losses that penalize undesirable events and encourage progress -- the perturbations then provide an important signal for these losses and lead to robustness of the learned model. We show that the ChauffeurNet model can handle complex situations in simulation, and present ablation experiments that emphasize the importance of each of our proposed changes and show that the model is responding to the appropriate causal factors. Finally, we demonstrate the model driving a car in the real world.
Geometric Polynomial Constraints in Higher-Order Graph Matching
May 24, 2014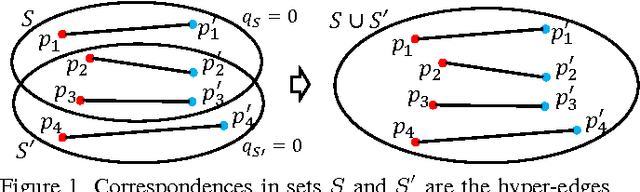
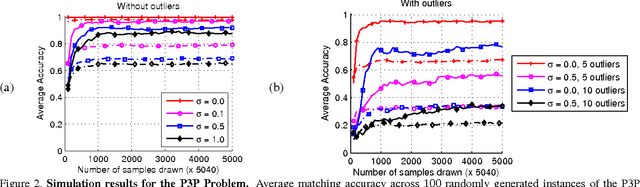
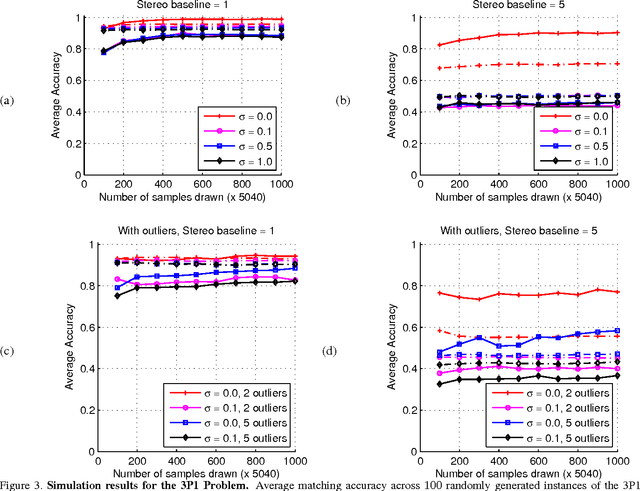
Correspondence is a ubiquitous problem in computer vision and graph matching has been a natural way to formalize correspondence as an optimization problem. Recently, graph matching solvers have included higher-order terms representing affinities beyond the unary and pairwise level. Such higher-order terms have a particular appeal for geometric constraints that include three or more correspondences like the PnP 2D-3D pose problems. In this paper, we address the problem of finding correspondences in the absence of unary or pairwise constraints as it emerges in problems where unary appearance similarity like SIFT matches is not available. Current higher order matching approaches have targeted problems where higher order affinity can simply be formulated as a difference of invariances such as lengths, angles, or cross-ratios. In this paper, we present a method of how to apply geometric constraints modeled as polynomial equation systems. As opposed to RANSAC where such systems have to be solved and then tested for inlier hypotheses, our constraints are derived as a single affinity weight based on $n>2$ hypothesized correspondences without solving the polynomial system. Since the result is directly a correspondence without a transformation model, our approach supports correspondence matching in the presence of multiple geometric transforms like articulated motions.