 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV2MAE: Multi-View Video Masked Autoencoders
Jan 29, 2024Videos captured from multiple viewpoints can help in perceiving the 3D structure of the world and benefit computer vision tasks such as action recognition, tracking, etc. In this paper, we present a method for self-supervised learning from synchronized multi-view videos. We use a cross-view reconstruction task to inject geometry information in the model. Our approach is based on the masked autoencoder (MAE) framework. In addition to the same-view decoder, we introduce a separate cross-view decoder which leverages cross-attention mechanism to reconstruct a target viewpoint video using a video from source viewpoint, to help representations robust to viewpoint changes. For videos, static regions can be reconstructed trivially which hinders learning meaningful representations. To tackle this, we introduce a motion-weighted reconstruction loss which improves temporal modeling. We report state-of-the-art results on the NTU-60, NTU-120 and ETRI datasets, as well as in the transfer learning setting on NUCLA, PKU-MMD-II and ROCOG-v2 datasets, demonstrating the robustness of our approach. Code will be made available.
Semantic Clustering for Robust Fine-Grained Scene Recognition
Jul 26, 2016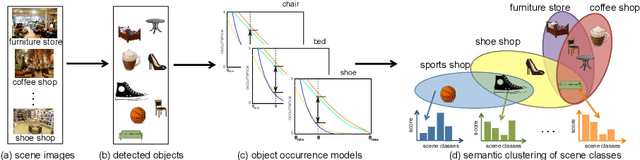


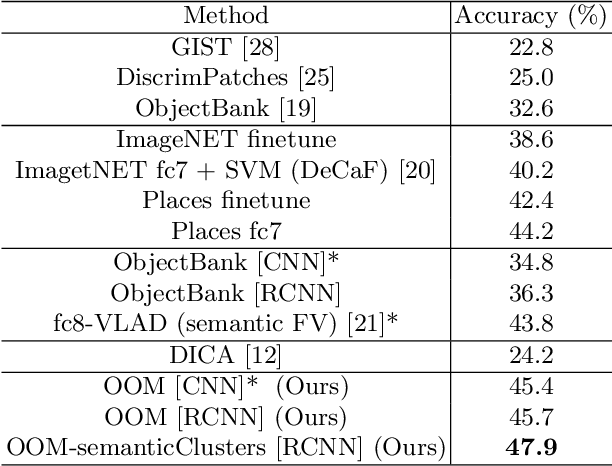
In domain generalization, the knowledge learnt from one or multiple source domains is transferred to an unseen target domain. In this work, we propose a novel domain generalization approach for fine-grained scene recognition. We first propose a semantic scene descriptor that jointly captures the subtle differences between fine-grained scenes, while being robust to varying object configurations across domains. We model the occurrence patterns of objects in scenes, capturing the informativeness and discriminability of each object for each scene. We then transform such occurrences into scene probabilities for each scene image. Second, we argue that scene images belong to hidden semantic topics that can be discovered by clustering our semantic descriptors. To evaluate the proposed method, we propose a new fine-grained scene dataset in cross-domain settings. Extensive experiments on the proposed dataset and three benchmark scene datasets show the effectiveness of the proposed approach for fine-grained scene transfer, where we outperform state-of-the-art scene recognition and domain generalization methods.
Image Parsing with a Wide Range of Classes and Scene-Level Context
Oct 24, 2015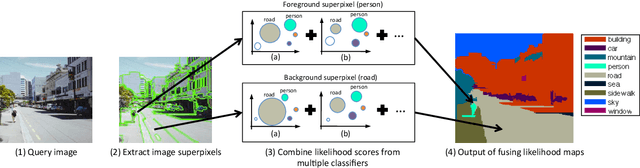

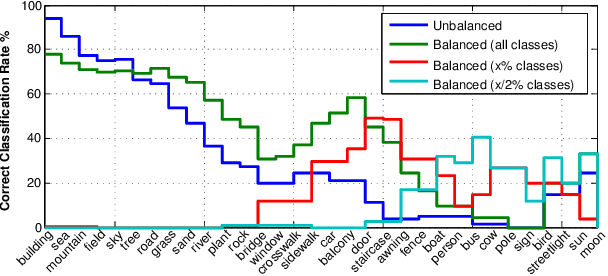
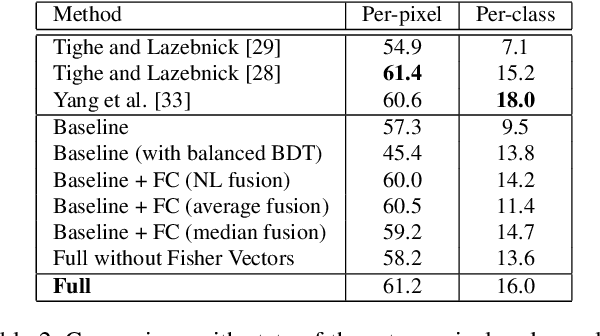
This paper presents a nonparametric scene parsing approach that improves the overall accuracy, as well as the coverage of foreground classes in scene images. We first improve the label likelihood estimates at superpixels by merging likelihood scores from different probabilistic classifiers. This boosts the classification performance and enriches the representation of less-represented classes. Our second contribution consists of incorporating semantic context in the parsing process through global label costs. Our method does not rely on image retrieval sets but rather assigns a global likelihood estimate to each label, which is plugged into the overall energy function. We evaluate our system on two large-scale datasets, SIFTflow and LMSun. We achieve state-of-the-art performance on the SIFTflow dataset and near-record results on LMSun.
Fine-Grained Product Class Recognition for Assisted Shopping
Oct 14, 2015


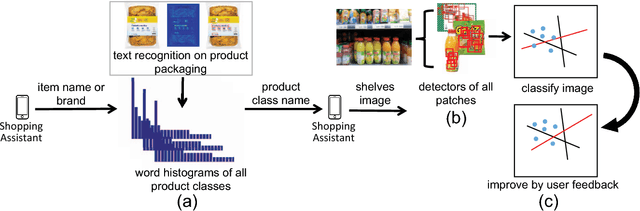
Assistive solutions for a better shopping experience can improve the quality of life of people, in particular also of visually impaired shoppers. We present a system that visually recognizes the fine-grained product classes of items on a shopping list, in shelves images taken with a smartphone in a grocery store. Our system consists of three components: (a) We automatically recognize useful text on product packaging, e.g., product name and brand, and build a mapping of words to product classes based on the large-scale GroceryProducts dataset. When the user populates the shopping list, we automatically infer the product class of each entered word. (b) We perform fine-grained product class recognition when the user is facing a shelf. We discover discriminative patches on product packaging to differentiate between visually similar product classes and to increase the robustness against continuous changes in product design. (c) We continuously improve the recognition accuracy through active learning. Our experiments show the robustness of the proposed method against cross-domain challenges, and the scalability to an increasing number of products with minimal re-training.
Acoustical Quality Assessment of the Classroom Environment
Jan 13, 2012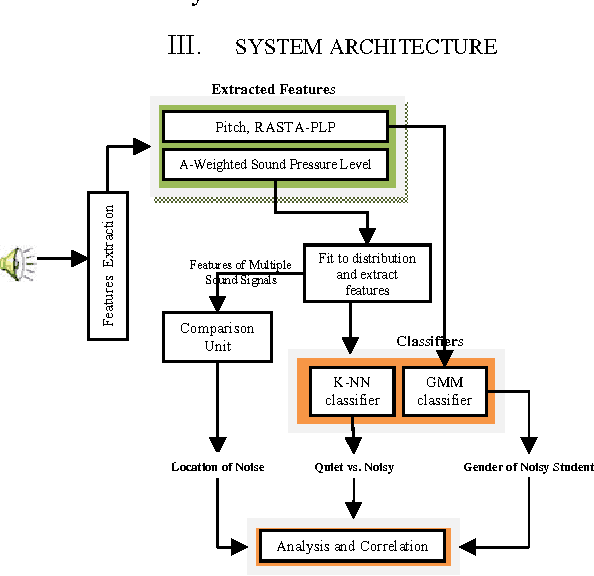

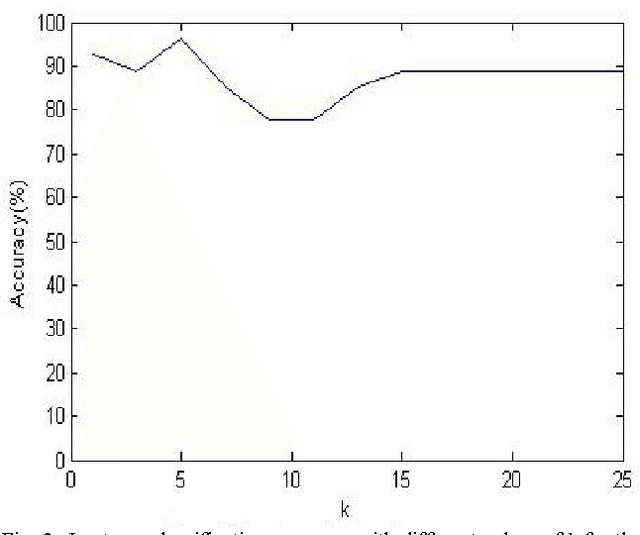

Teaching is one of the most important factors affecting any education system. Many research efforts have been conducted to facilitate the presentation modes used by instructors in classrooms as well as provide means for students to review lectures through web browsers. Other studies have been made to provide acoustical design recommendations for classrooms like room size and reverberation times. However, using acoustical features of classrooms as a way to provide education systems with feedback about the learning process was not thoroughly investigated in any of these studies. We propose a system that extracts different sound features of students and instructors, and then uses machine learning techniques to evaluate the acoustical quality of any learning environment. We infer conclusions about the students' satisfaction with the quality of lectures. Using classifiers instead of surveys and other subjective ways of measures can facilitate and speed such experiments which enables us to perform them continuously. We believe our system enables education systems to continuously review and improve their teaching strategies and acoustical quality of classrooms.