 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Pose Trajectory Completion
May 01, 2021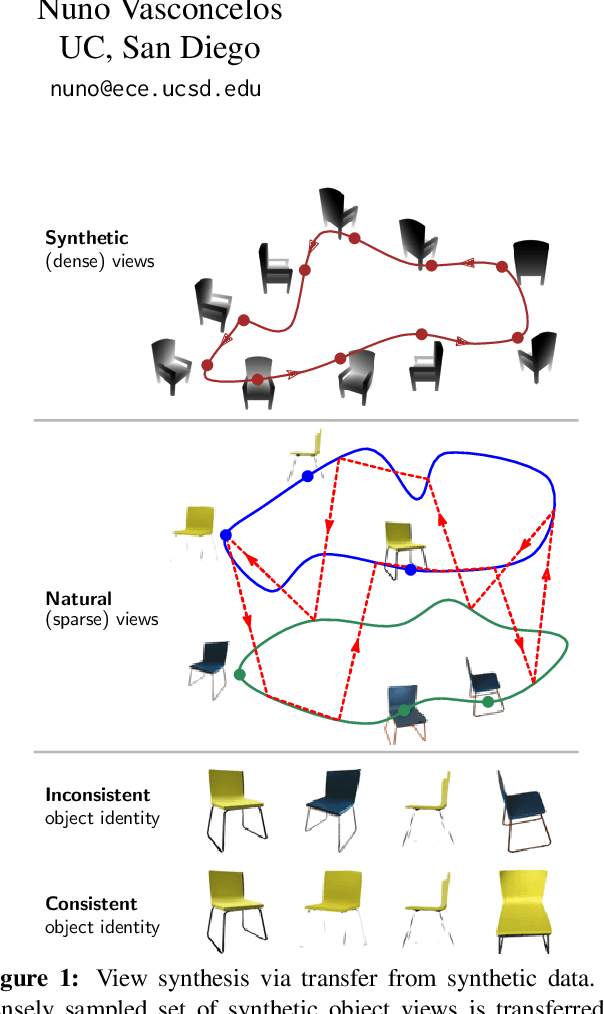
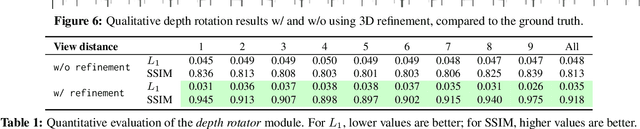
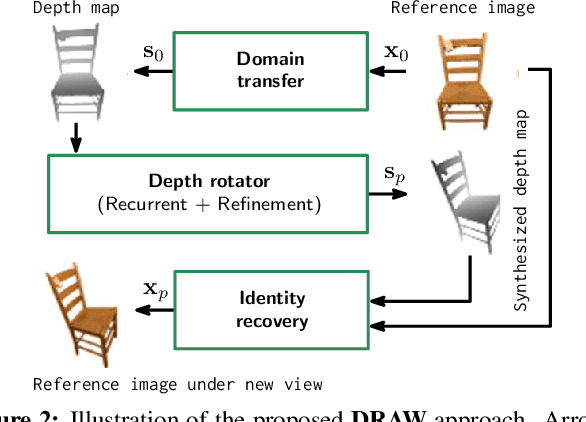
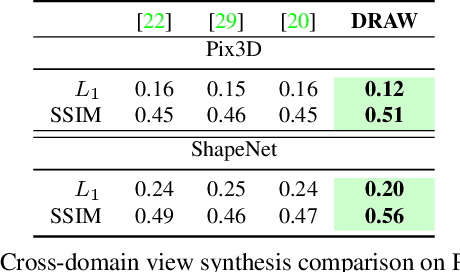
We propose a method to learn, even using a dataset where objects appear only in sparsely sampled views (e.g. Pix3D), the ability to synthesize a pose trajectory for an arbitrary reference image. This is achieved with a cross-modal pose trajectory transfer mechanism. First, a domain transfer function is trained to predict, from an RGB image of the object, its 2D depth map. Then, a set of image views is generated by learning to simulate object rotation in the depth space. Finally, the generated poses are mapped from this latent space into a set of corresponding RGB images using a learned identity preserving transform. This results in a dense pose trajectory of the object in image space. For each object type (e.g., a specific Ikea chair model), a 3D CAD model is used to render a full pose trajectory of 2D depth maps. In the absence of dense pose sampling in image space, these latent space trajectories provide cross-modal guidance for learning. The learned pose trajectories can be transferred to unseen examples, effectively synthesizing all object views in image space. Our method is evaluated on the Pix3D and ShapeNet datasets, in the setting of novel view synthesis under sparse pose supervision, demonstrating substantial improvements over recent art.
Connectivity-Optimized Representation Learning via Persistent Homology
Jun 21, 2019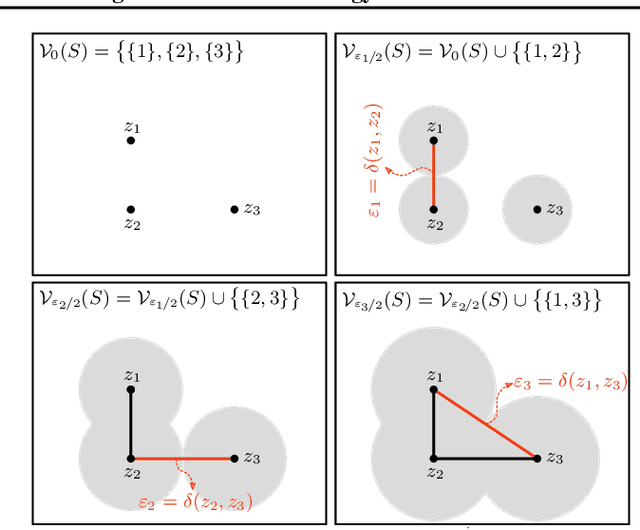
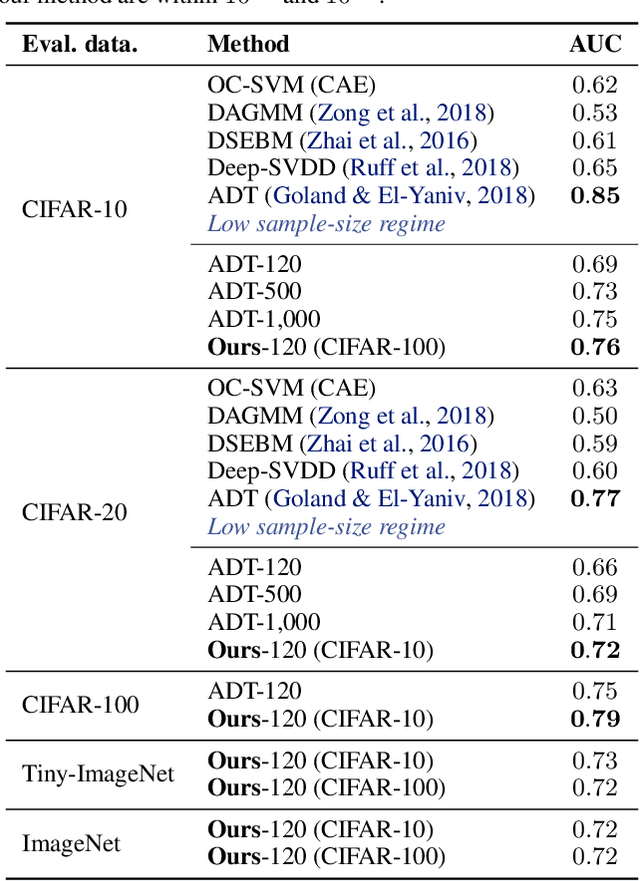
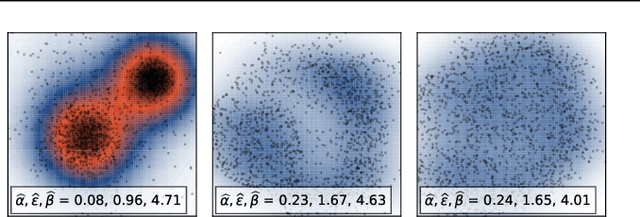
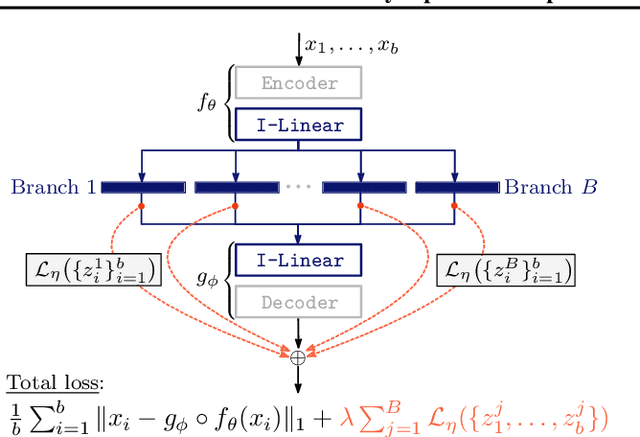
We study the problem of learning representations with controllable connectivity properties. This is beneficial in situations when the imposed structure can be leveraged upstream. In particular, we control the connectivity of an autoencoder's latent space via a novel type of loss, operating on information from persistent homology. Under mild conditions, this loss is differentiable and we present a theoretical analysis of the properties induced by the loss. We choose one-class learning as our upstream task and demonstrate that the imposed structure enables informed parameter selection for modeling the in-class distribution via kernel density estimators. Evaluated on computer vision data, these one-class models exhibit competitive performance and, in a low sample size regime, outperform other methods by a large margin. Notably, our results indicate that a single autoencoder, trained on auxiliary (unlabeled) data, yields a mapping into latent space that can be reused across datasets for one-class learning.
Semantic Fisher Scores for Task Transfer: Using Objects to Classify Scenes
May 27, 2019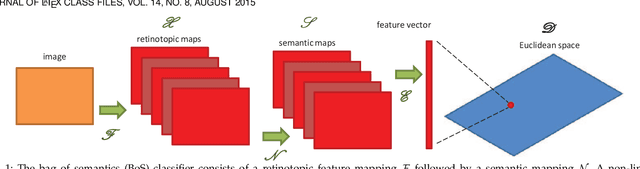

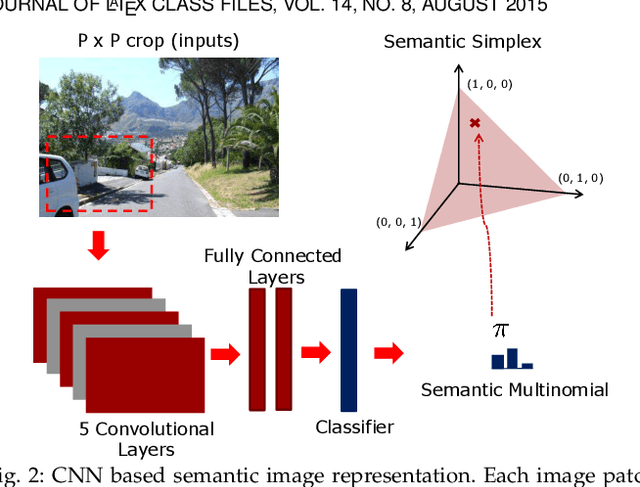

The transfer of a neural network (CNN) trained to recognize objects to the task of scene classification is considered. A Bag-of-Semantics (BoS) representation is first induced, by feeding scene image patches to the object CNN, and representing the scene image by the ensuing bag of posterior class probability vectors (semantic posteriors). The encoding of the BoS with a Fisher vector(FV) is then studied. A link is established between the FV of any probabilistic model and the Q-function of the expectation-maximization(EM) algorithm used to estimate its parameters by maximum likelihood. A network implementation of the MFA Fisher Score (MFA-FS), denoted as the MFAFSNet, is finally proposed to enable end-to-end training. Experiments with various object CNNs and datasets show that the approach has state-of-the-art transfer performance. Somewhat surprisingly, the scene classification results are superior to those of a CNN explicitly trained for scene classification, using a large scene dataset (Places). This suggests that holistic analysis is insufficient for scene classification. The modeling of local object semantics appears to be at least equally important. The two approaches are also shown to be strongly complementary, leading to very large scene classification gains when combined, and outperforming all previous scene classification approaches by a sizeable margin
Feature Space Transfer for Data Augmentation
Feb 01, 2018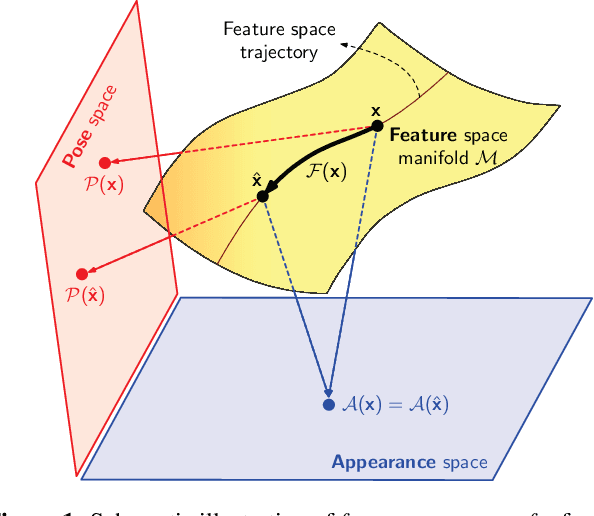
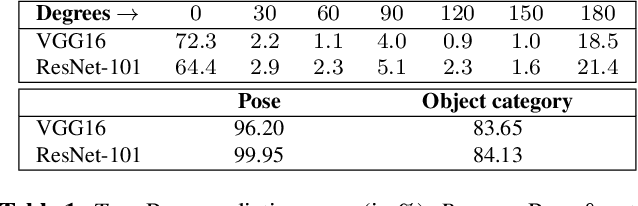
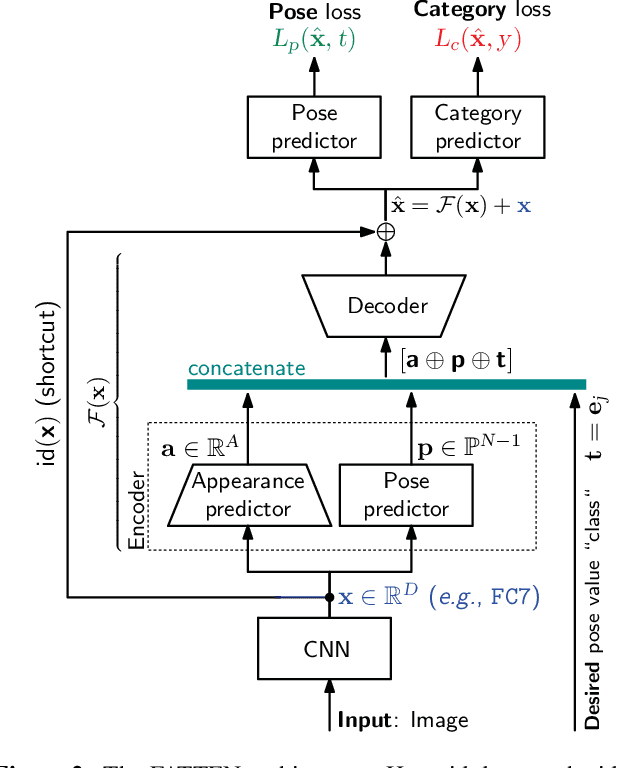

The problem of data augmentation in feature space is considered. A new architecture, denoted the FeATure TransfEr Network (FATTEN), is proposed for the modeling of feature trajectories induced by variations of object pose. This architecture exploits a parametrization of the pose manifold in terms of pose and appearance. This leads to a deep encoder/decoder network architecture, where the encoder factors into an appearance and a pose predictor. Unlike previous attempts at trajectory transfer, FATTEN can be efficiently trained end-to-end, with no need to train separate feature transfer functions. This is realized by supplying the decoder with information about a target pose and the use of a multi-task loss that penalizes category- and pose-mismatches. In result, FATTEN discourages discontinuous or non-smooth trajectories that fail to capture the structure of the pose manifold, and generalizes well on object recognition tasks involving large pose variation. Experimental results on the artificial ModelNet database show that it can successfully learn to map source features to target features of a desired pose, while preserving class identity. Most notably, by using feature space transfer for data augmentation (w.r.t. pose and depth) on SUN-RGBD objects, we demonstrate considerable performance improvements on one/few-shot object recognition in a transfer learning setup, compared to current state-of-the-art methods.
AGA: Attribute Guided Augmentation
Aug 26, 2017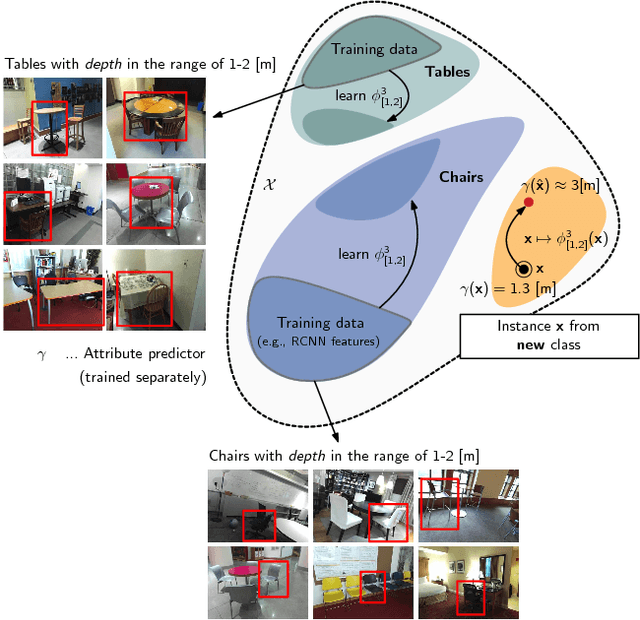
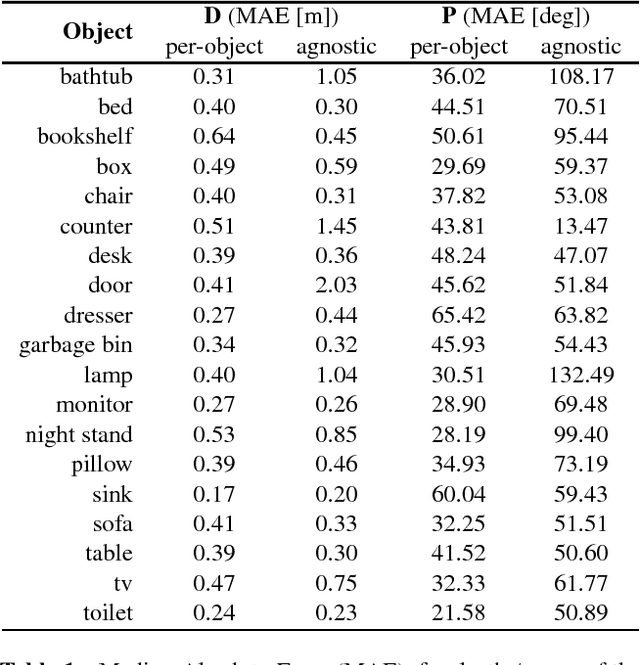
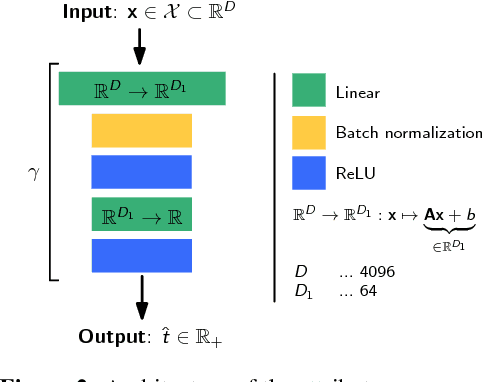
We consider the problem of data augmentation, i.e., generating artificial samples to extend a given corpus of training data. Specifically, we propose attributed-guided augmentation (AGA) which learns a mapping that allows to synthesize data such that an attribute of a synthesized sample is at a desired value or strength. This is particularly interesting in situations where little data with no attribute annotation is available for learning, but we have access to a large external corpus of heavily annotated samples. While prior works primarily augment in the space of images, we propose to perform augmentation in feature space instead. We implement our approach as a deep encoder-decoder architecture that learns the synthesis function in an end-to-end manner. We demonstrate the utility of our approach on the problems of (1) one-shot object recognition in a transfer-learning setting where we have no prior knowledge of the new classes, as well as (2) object-based one-shot scene recognition. As external data, we leverage 3D depth and pose information from the SUN RGB-D dataset. Our experiments show that attribute-guided augmentation of high-level CNN features considerably improves one-shot recognition performance on both problems.
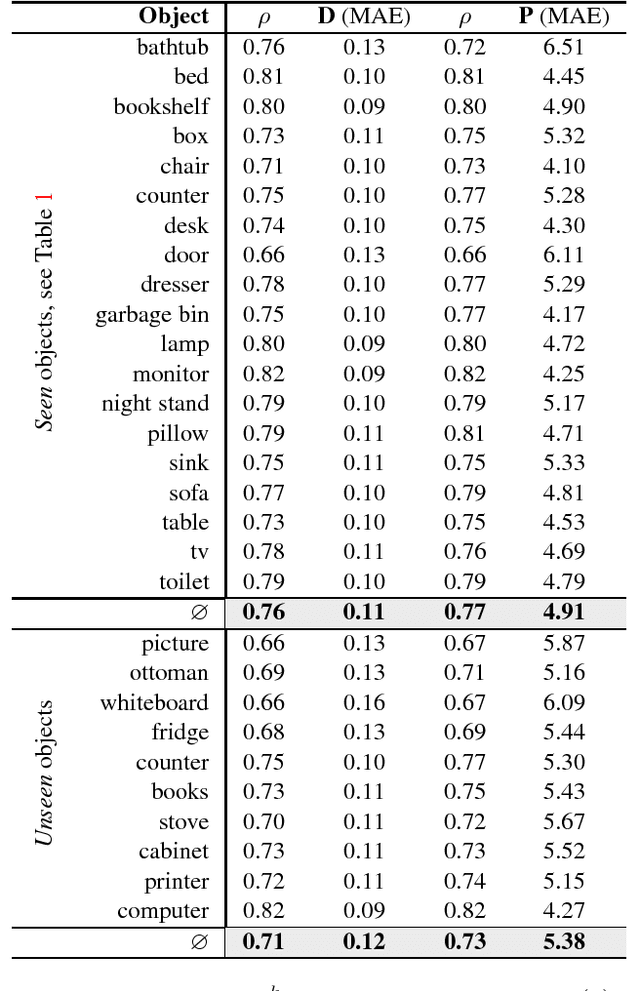
Semantic Clustering for Robust Fine-Grained Scene Recognition
Jul 26, 2016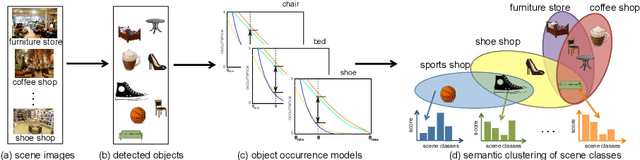


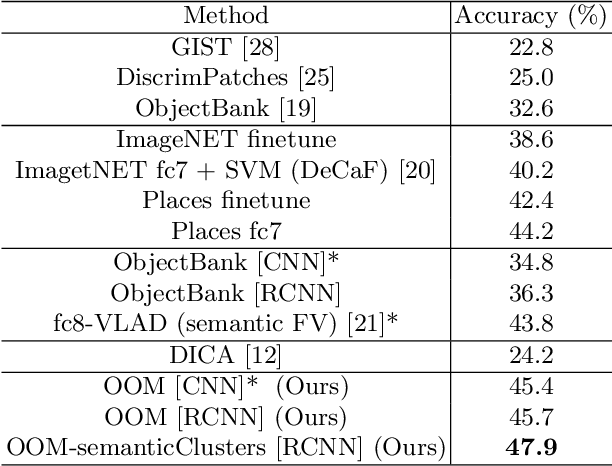
In domain generalization, the knowledge learnt from one or multiple source domains is transferred to an unseen target domain. In this work, we propose a novel domain generalization approach for fine-grained scene recognition. We first propose a semantic scene descriptor that jointly captures the subtle differences between fine-grained scenes, while being robust to varying object configurations across domains. We model the occurrence patterns of objects in scenes, capturing the informativeness and discriminability of each object for each scene. We then transform such occurrences into scene probabilities for each scene image. Second, we argue that scene images belong to hidden semantic topics that can be discovered by clustering our semantic descriptors. To evaluate the proposed method, we propose a new fine-grained scene dataset in cross-domain settings. Extensive experiments on the proposed dataset and three benchmark scene datasets show the effectiveness of the proposed approach for fine-grained scene transfer, where we outperform state-of-the-art scene recognition and domain generalization methods.