 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation of Networks for Camera Pose Estimation: Learning Camera Pose Estimation Without Pose Labels
Nov 29, 2021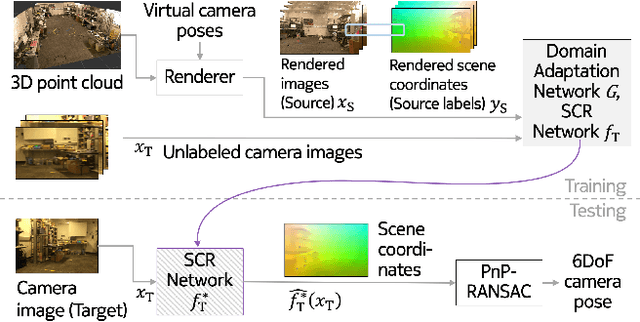
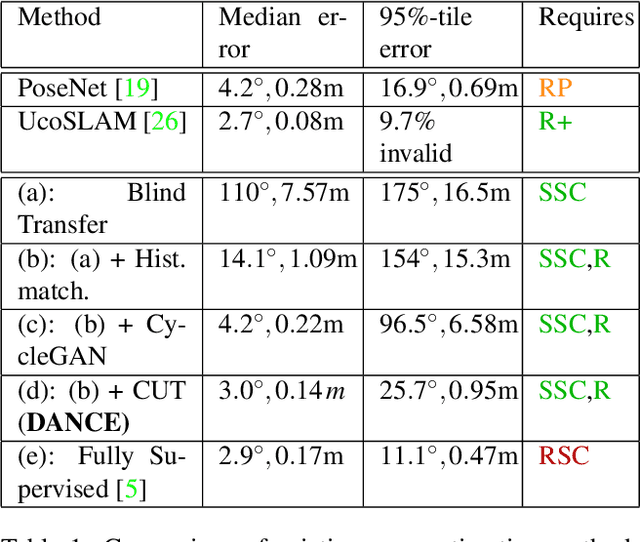
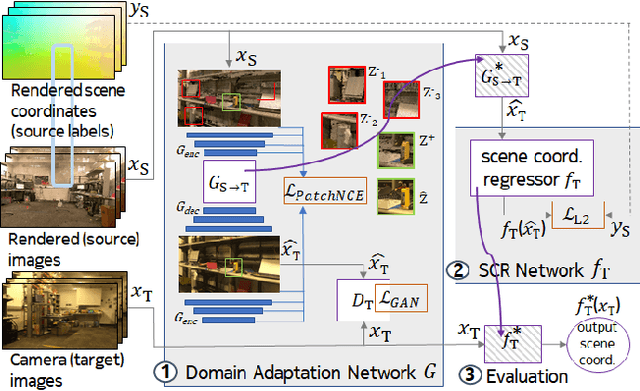

One of the key criticisms of deep learning is that large amounts of expensive and difficult-to-acquire training data are required in order to train models with high performance and good generalization capabilities. Focusing on the task of monocular camera pose estimation via scene coordinate regression (SCR), we describe a novel method, Domain Adaptation of Networks for Camera pose Estimation (DANCE), which enables the training of models without access to any labels on the target task. DANCE requires unlabeled images (without known poses, ordering, or scene coordinate labels) and a 3D representation of the space (e.g., a scanned point cloud), both of which can be captured with minimal effort using off-the-shelf commodity hardware. DANCE renders labeled synthetic images from the 3D model, and bridges the inevitable domain gap between synthetic and real images by applying unsupervised image-level domain adaptation techniques (unpaired image-to-image translation). When tested on real images, the SCR model trained with DANCE achieved comparable performance to its fully supervised counterpart (in both cases using PnP-RANSAC for final pose estimation) at a fraction of the cost. Our code and dataset are available at https://github.com/JackLangerman/dance
Fine-Grained Product Class Recognition for Assisted Shopping
Oct 14, 2015


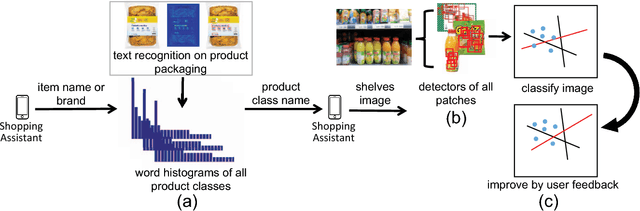
Assistive solutions for a better shopping experience can improve the quality of life of people, in particular also of visually impaired shoppers. We present a system that visually recognizes the fine-grained product classes of items on a shopping list, in shelves images taken with a smartphone in a grocery store. Our system consists of three components: (a) We automatically recognize useful text on product packaging, e.g., product name and brand, and build a mapping of words to product classes based on the large-scale GroceryProducts dataset. When the user populates the shopping list, we automatically infer the product class of each entered word. (b) We perform fine-grained product class recognition when the user is facing a shelf. We discover discriminative patches on product packaging to differentiate between visually similar product classes and to increase the robustness against continuous changes in product design. (c) We continuously improve the recognition accuracy through active learning. Our experiments show the robustness of the proposed method against cross-domain challenges, and the scalability to an increasing number of products with minimal re-training.