 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
PseudoAugment: Learning to Use Unlabeled Data for Data Augmentation in Point Clouds
Oct 24, 2022Data augmentation is an important technique to improve data efficiency and save labeling cost for 3D detection in point clouds. Yet, existing augmentation policies have so far been designed to only utilize labeled data, which limits the data diversity. In this paper, we recognize that pseudo labeling and data augmentation are complementary, thus propose to leverage unlabeled data for data augmentation to enrich the training data. In particular, we design three novel pseudo-label based data augmentation policies (PseudoAugments) to fuse both labeled and pseudo-labeled scenes, including frames (PseudoFrame), objecta (PseudoBBox), and background (PseudoBackground). PseudoAugments outperforms pseudo labeling by mitigating pseudo labeling errors and generating diverse fused training scenes. We demonstrate PseudoAugments generalize across point-based and voxel-based architectures, different model capacity and both KITTI and Waymo Open Dataset. To alleviate the cost of hyperparameter tuning and iterative pseudo labeling, we develop a population-based data augmentation framework for 3D detection, named AutoPseudoAugment. Unlike previous works that perform pseudo-labeling offline, our framework performs PseudoAugments and hyperparameter tuning in one shot to reduce computational cost. Experimental results on the large-scale Waymo Open Dataset show our method outperforms state-of-the-art auto data augmentation method (PPBA) and self-training method (pseudo labeling). In particular, AutoPseudoAugment is about 3X and 2X data efficient on vehicle and pedestrian tasks compared to prior arts. Notably, AutoPseudoAugment nearly matches the full dataset training results, with just 10% of the labeled run segments on the vehicle detection task.
G-Augment: Searching For The Meta-Structure Of Data Augmentation Policies For ASR
Oct 19, 2022
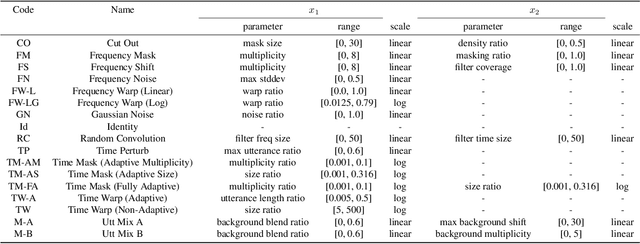
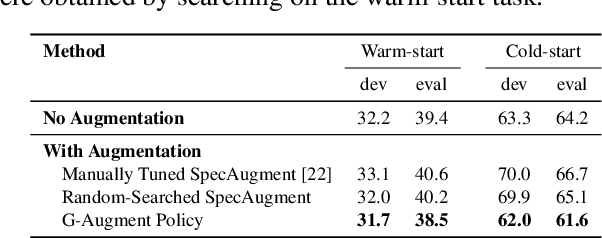
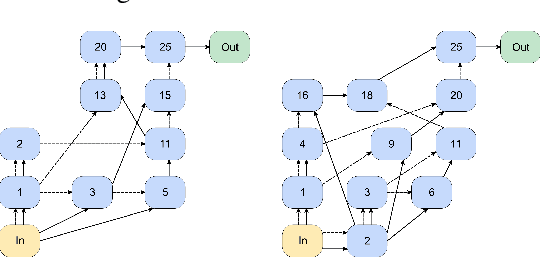
Data augmentation is a ubiquitous technique used to provide robustness to automatic speech recognition (ASR) training. However, even as so much of the ASR training process has become automated and more "end-to-end", the data augmentation policy (what augmentation functions to use, and how to apply them) remains hand-crafted. We present Graph-Augment, a technique to define the augmentation space as directed acyclic graphs (DAGs) and search over this space to optimize the augmentation policy itself. We show that given the same computational budget, policies produced by G-Augment are able to perform better than SpecAugment policies obtained by random search on fine-tuning tasks on CHiME-6 and AMI. G-Augment is also able to establish a new state-of-the-art ASR performance on the CHiME-6 evaluation set (30.7% WER). We further demonstrate that G-Augment policies show better transfer properties across warm-start to cold-start training and model size compared to random-searched SpecAugment policies.
LidarNAS: Unifying and Searching Neural Architectures for 3D Point Clouds
Oct 10, 2022
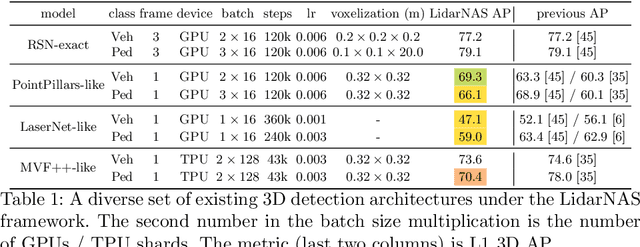

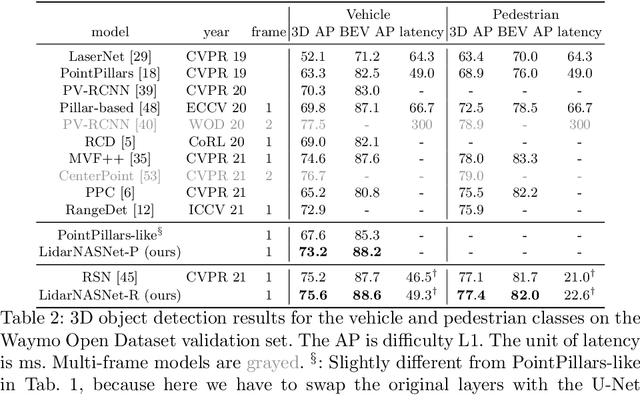
Developing neural models that accurately understand objects in 3D point clouds is essential for the success of robotics and autonomous driving. However, arguably due to the higher-dimensional nature of the data (as compared to images), existing neural architectures exhibit a large variety in their designs, including but not limited to the views considered, the format of the neural features, and the neural operations used. Lack of a unified framework and interpretation makes it hard to put these designs in perspective, as well as systematically explore new ones. In this paper, we begin by proposing a unified framework of such, with the key idea being factorizing the neural networks into a series of view transforms and neural layers. We demonstrate that this modular framework can reproduce a variety of existing works while allowing a fair comparison of backbone designs. Then, we show how this framework can easily materialize into a concrete neural architecture search (NAS) space, allowing a principled NAS-for-3D exploration. In performing evolutionary NAS on the 3D object detection task on the Waymo Open Dataset, not only do we outperform the state-of-the-art models, but also report the interesting finding that NAS tends to discover the same macro-level architecture concept for both the vehicle and pedestrian classes.
PolyLoss: A Polynomial Expansion Perspective of Classification Loss Functions
Apr 26, 2022
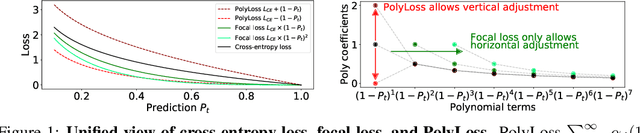

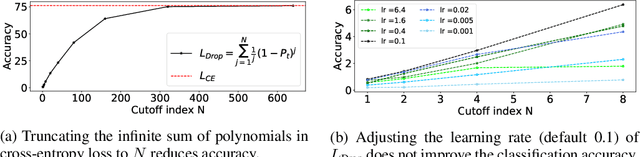
Cross-entropy loss and focal loss are the most common choices when training deep neural networks for classification problems. Generally speaking, however, a good loss function can take on much more flexible forms, and should be tailored for different tasks and datasets. Motivated by how functions can be approximated via Taylor expansion, we propose a simple framework, named PolyLoss, to view and design loss functions as a linear combination of polynomial functions. Our PolyLoss allows the importance of different polynomial bases to be easily adjusted depending on the targeting tasks and datasets, while naturally subsuming the aforementioned cross-entropy loss and focal loss as special cases. Extensive experimental results show that the optimal choice within the PolyLoss is indeed dependent on the task and dataset. Simply by introducing one extra hyperparameter and adding one line of code, our Poly-1 formulation outperforms the cross-entropy loss and focal loss on 2D image classification, instance segmentation, object detection, and 3D object detection tasks, sometimes by a large margin.
Large Scale Interactive Motion Forecasting for Autonomous Driving : The Waymo Open Motion Dataset
Apr 20, 2021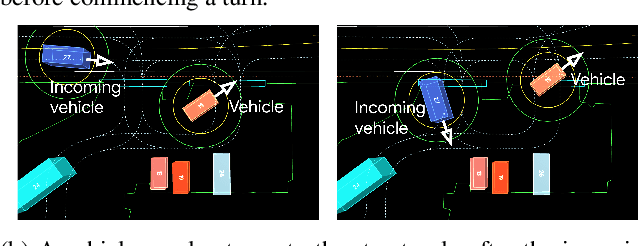
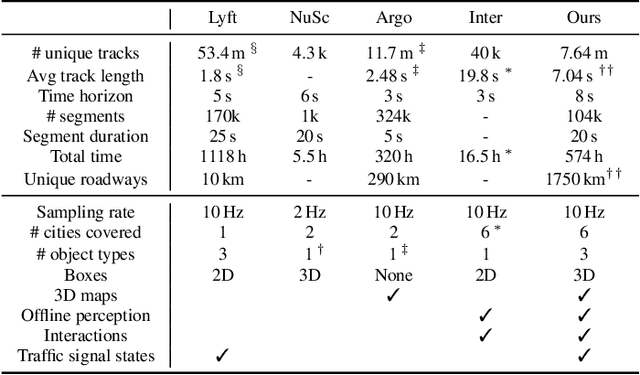
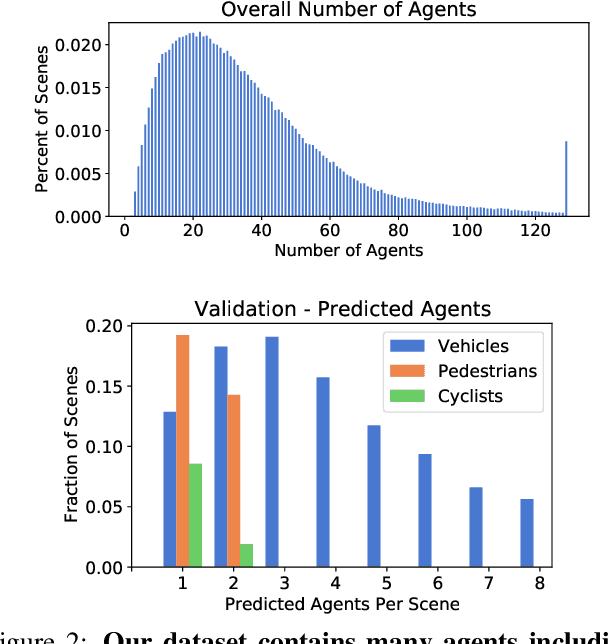
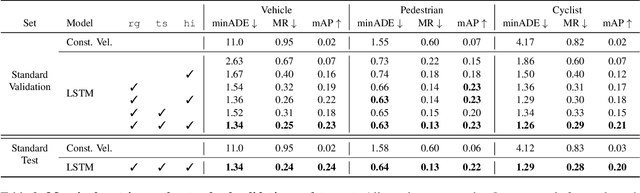
As autonomous driving systems mature, motion forecasting has received increasing attention as a critical requirement for planning. Of particular importance are interactive situations such as merges, unprotected turns, etc., where predicting individual object motion is not sufficient. Joint predictions of multiple objects are required for effective route planning. There has been a critical need for high-quality motion data that is rich in both interactions and annotation to develop motion planning models. In this work, we introduce the most diverse interactive motion dataset to our knowledge, and provide specific labels for interacting objects suitable for developing joint prediction models. With over 100,000 scenes, each 20 seconds long at 10 Hz, our new dataset contains more than 570 hours of unique data over 1750 km of roadways. It was collected by mining for interesting interactions between vehicles, pedestrians, and cyclists across six cities within the United States. We use a high-accuracy 3D auto-labeling system to generate high quality 3D bounding boxes for each road agent, and provide corresponding high definition 3D maps for each scene. Furthermore, we introduce a new set of metrics that provides a comprehensive evaluation of both single agent and joint agent interaction motion forecasting models. Finally, we provide strong baseline models for individual-agent prediction and joint-prediction. We hope that this new large-scale interactive motion dataset will provide new opportunities for advancing motion forecasting models.
Can weight sharing outperform random architecture search? An investigation with TuNAS
Aug 13, 2020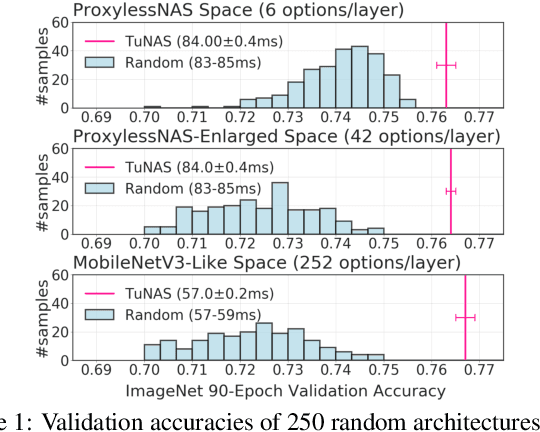


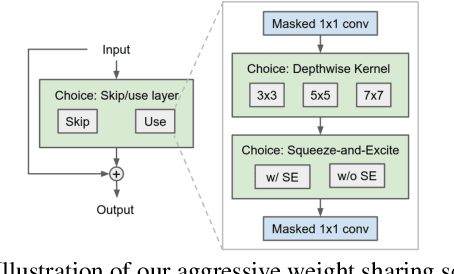
Efficient Neural Architecture Search methods based on weight sharing have shown good promise in democratizing Neural Architecture Search for computer vision models. There is, however, an ongoing debate whether these efficient methods are significantly better than random search. Here we perform a thorough comparison between efficient and random search methods on a family of progressively larger and more challenging search spaces for image classification and detection on ImageNet and COCO. While the efficacies of both methods are problem-dependent, our experiments demonstrate that there are large, realistic tasks where efficient search methods can provide substantial gains over random search. In addition, we propose and evaluate techniques which improve the quality of searched architectures and reduce the need for manual hyper-parameter tuning. Source code and experiment data are available at https://github.com/google-research/google-research/tree/master/tunas
* Published at CVPR 2020
Improving 3D Object Detection through Progressive Population Based Augmentation
Apr 02, 2020
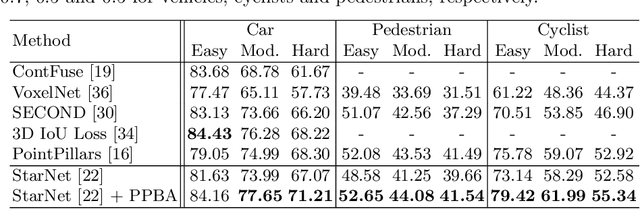


Data augmentation has been widely adopted for object detection in 3D point clouds. All previous efforts have focused on manually designing specific data augmentation methods for individual architectures, however no work has attempted to automate the design of data augmentation in 3D detection problems -- as is common in 2D image-based computer vision. In this work, we present the first attempt to automate the design of data augmentation policies for 3D object detection. We present an algorithm, termed Progressive Population Based Augmentation (PPBA). PPBA learns to optimize augmentation strategies by narrowing down the search space and adopting the best parameters discovered in previous iterations. On the KITTI test set, PPBA improves the StarNet detector by substantial margins on the moderate difficulty category of cars, pedestrians, and cyclists, outperforming all current state-of-the-art single-stage detection models. Additional experiments on the Waymo Open Dataset indicate that PPBA continues to effectively improve 3D object detection on a 20x larger dataset compared to KITTI. The magnitude of the improvements may be comparable to advances in 3D perception architectures and the gains come without an incurred cost at inference time. In subsequent experiments, we find that PPBA may be up to 10x more data efficient than baseline 3D detection models without augmentation, highlighting that 3D detection models may achieve competitive accuracy with far fewer labeled examples.