 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Realistic Simulation Framework for Learning with Label Noise
Jul 23, 2021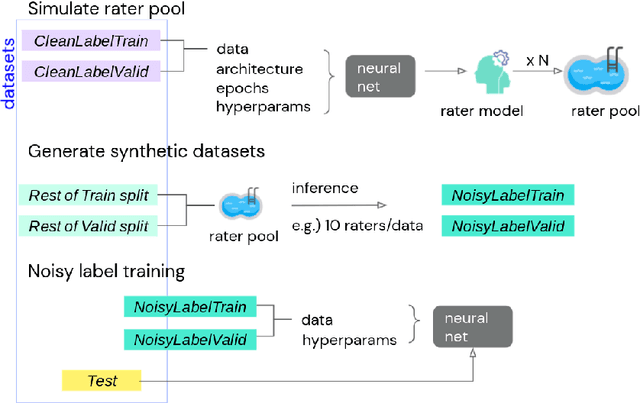
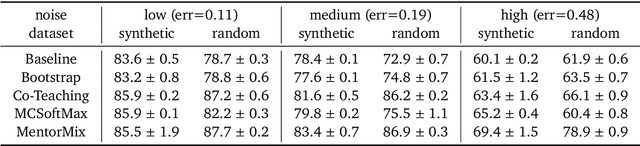
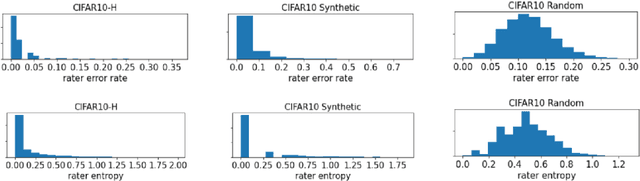
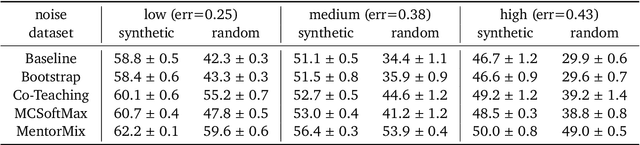
We propose a simulation framework for generating realistic instance-dependent noisy labels via a pseudo-labeling paradigm. We show that this framework generates synthetic noisy labels that exhibit important characteristics of the label noise in practical settings via comparison with the CIFAR10-H dataset. Equipped with controllable label noise, we study the negative impact of noisy labels across a few realistic settings to understand when label noise is more problematic. We also benchmark several existing algorithms for learning with noisy labels and compare their behavior on our synthetic datasets and on the datasets with independent random label noise. Additionally, with the availability of annotator information from our simulation framework, we propose a new technique, Label Quality Model (LQM), that leverages annotator features to predict and correct against noisy labels. We show that by adding LQM as a label correction step before applying existing noisy label techniques, we can further improve the models' performance.
Using Videos to Evaluate Image Model Robustness
Apr 24, 2019
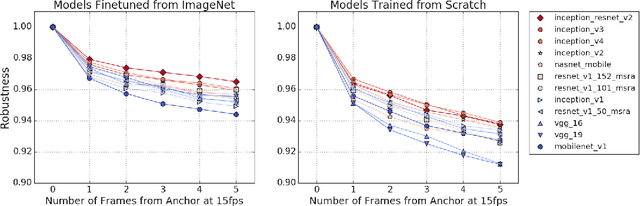
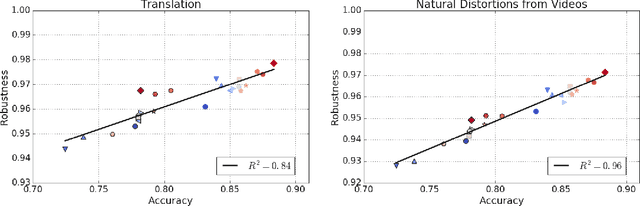
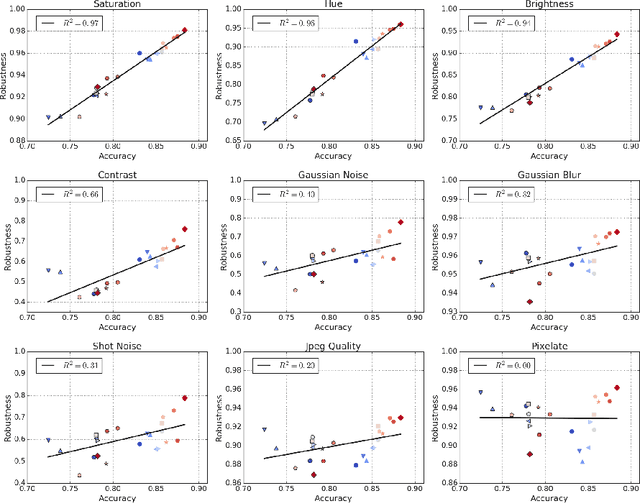
Human visual systems are robust to a wide range of image transformations that are challenging for artificial networks. We present the first study of image model robustness to the minute transformations found across video frames, which we term "natural robustness". Compared to previous studies on adversarial examples and synthetic distortions, natural robustness captures a more diverse set of common image transformations that occur in the natural environment. Our study across a dozen model architectures shows that more accurate models are more robust to natural transformations, and that robustness to synthetic color distortions is a good proxy for natural robustness. In examining brittleness in videos, we find that majority of the brittleness found in videos lies outside the typical definition of adversarial examples (99.9\%). Finally, we investigate training techniques to reduce brittleness and find that no single technique systematically improves natural robustness across twelve tested architectures.
Efficient Model Learning for Human-Robot Collaborative Tasks
May 24, 2014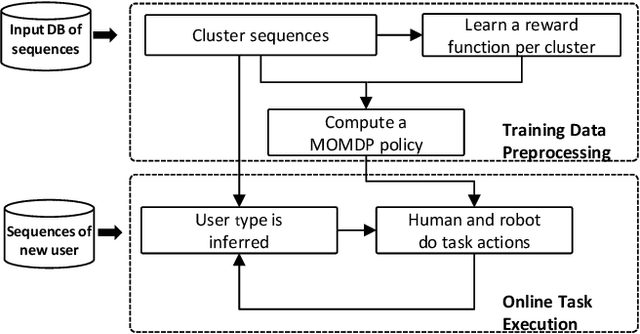



We present a framework for learning human user models from joint-action demonstrations that enables the robot to compute a robust policy for a collaborative task with a human. The learning takes place completely automatically, without any human intervention. First, we describe the clustering of demonstrated action sequences into different human types using an unsupervised learning algorithm. These demonstrated sequences are also used by the robot to learn a reward function that is representative for each type, through the employment of an inverse reinforcement learning algorithm. The learned model is then used as part of a Mixed Observability Markov Decision Process formulation, wherein the human type is a partially observable variable. With this framework, we can infer, either offline or online, the human type of a new user that was not included in the training set, and can compute a policy for the robot that will be aligned to the preference of this new user and will be robust to deviations of the human actions from prior demonstrations. Finally we validate the approach using data collected in human subject experiments, and conduct proof-of-concept demonstrations in which a person performs a collaborative task with a small industrial robot.