Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Text Recognition with Hybrid HMM Maxout Models
Paper and Code
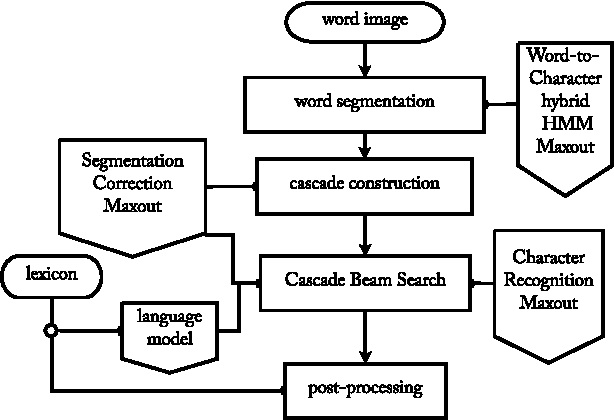
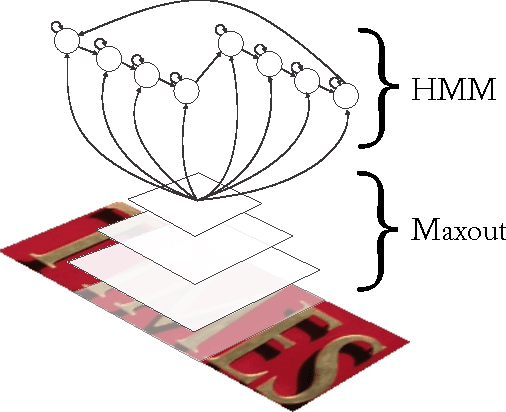
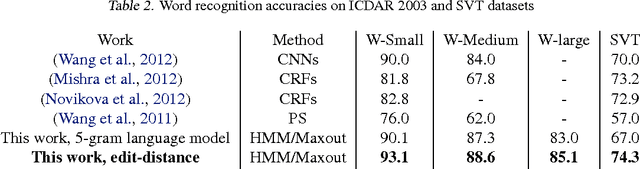

The problem of detecting and recognizing text in natural scenes has proved to be more challenging than its counterpart in documents, with most of the previous work focusing on a single part of the problem. In this work, we propose new solutions to the character and word recognition problems and then show how to combine these solutions in an end-to-end text-recognition system. We do so by leveraging the recently introduced Maxout networks along with hybrid HMM models that have proven useful for voice recognition. Using these elements, we build a tunable and highly accurate recognition system that beats state-of-the-art results on all the sub-problems for both the ICDAR 2003 and SVT benchmark datasets.
* 9 pages, 7 figures
View paper on