 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Conformer-based Waveform-domain Neural Acoustic Echo Canceller Optimized for ASR Accuracy
May 06, 2022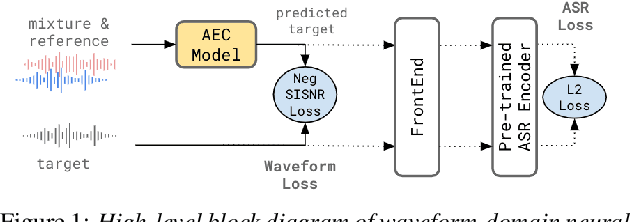
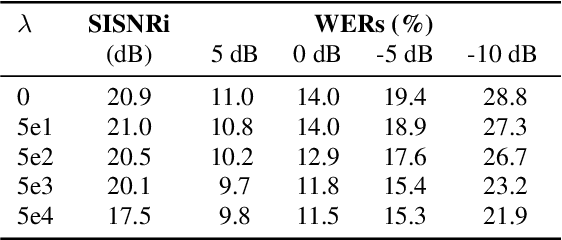
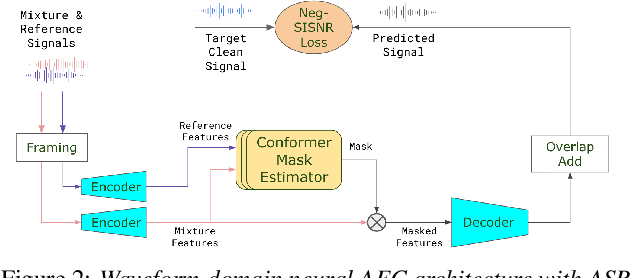
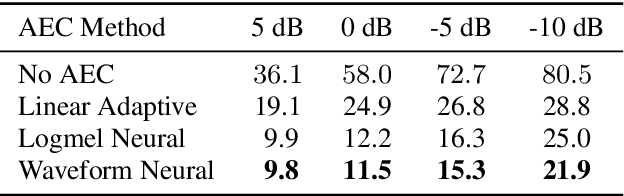
Acoustic Echo Cancellation (AEC) is essential for accurate recognition of queries spoken to a smart speaker that is playing out audio. Previous work has shown that a neural AEC model operating on log-mel spectral features (denoted "logmel" hereafter) can greatly improve Automatic Speech Recognition (ASR) accuracy when optimized with an auxiliary loss utilizing a pre-trained ASR model encoder. In this paper, we develop a conformer-based waveform-domain neural AEC model inspired by the "TasNet" architecture. The model is trained by jointly optimizing Negative Scale-Invariant SNR (SISNR) and ASR losses on a large speech dataset. On a realistic rerecorded test set, we find that cascading a linear adaptive AEC and a waveform-domain neural AEC is very effective, giving 56-59% word error rate (WER) reduction over the linear AEC alone. On this test set, the 1.6M parameter waveform-domain neural AEC also improves over a larger 6.5M parameter logmel-domain neural AEC model by 20-29% in easy to moderate conditions. By operating on smaller frames, the waveform neural model is able to perform better at smaller sizes and is better suited for applications where memory is limited.
A Neural Acoustic Echo Canceller Optimized Using An Automatic Speech Recognizer And Large Scale Synthetic Data
Jun 01, 2021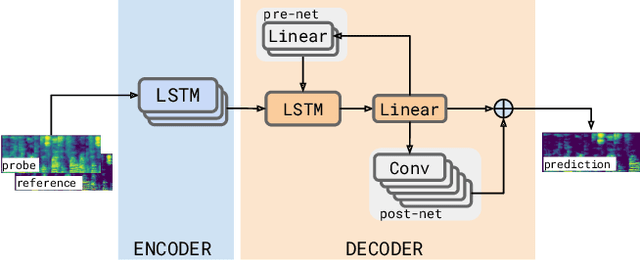
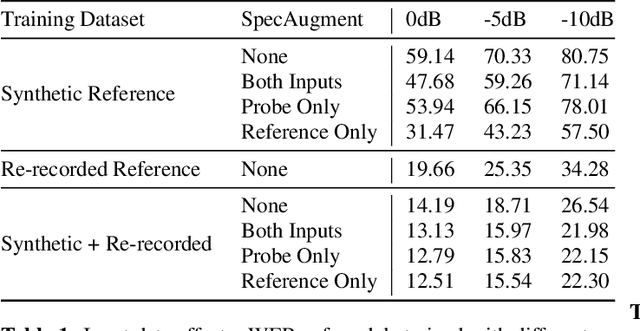

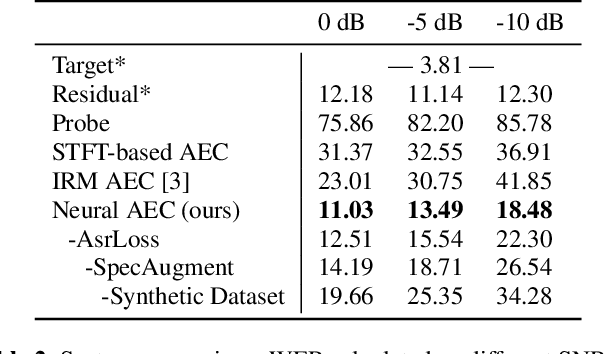
We consider the problem of recognizing speech utterances spoken to a device which is generating a known sound waveform; for example, recognizing queries issued to a digital assistant which is generating responses to previous user inputs. Previous work has proposed building acoustic echo cancellation (AEC) models for this task that optimize speech enhancement metrics using both neural network as well as signal processing approaches. Since our goal is to recognize the input speech, we consider enhancements which improve word error rates (WERs) when the predicted speech signal is passed to an automatic speech recognition (ASR) model. First, we augment the loss function with a term that produces outputs useful to a pre-trained ASR model and show that this augmented loss function improves WER metrics. Second, we demonstrate that augmenting our training dataset of real world examples with a large synthetic dataset improves performance. Crucially, applying SpecAugment style masks to the reference channel during training aids the model in adapting from synthetic to real domains. In experimental evaluations, we find the proposed approaches improve performance, on average, by 57% over a signal processing baseline and 45% over the neural AEC model without the proposed changes.
VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition
Sep 09, 2020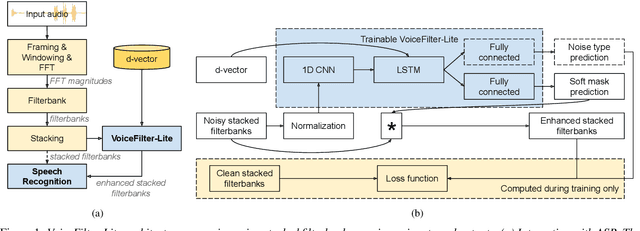

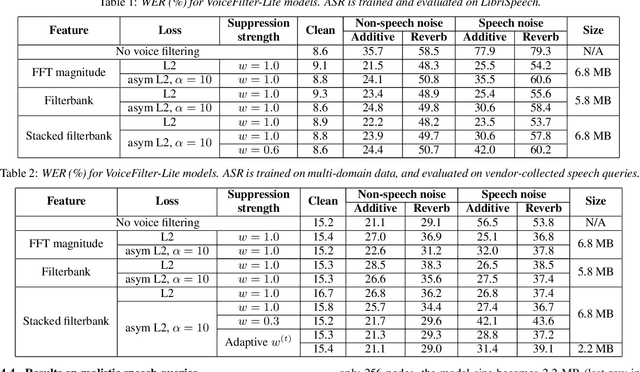
We introduce VoiceFilter-Lite, a single-channel source separation model that runs on the device to preserve only the speech signals from a target user, as part of a streaming speech recognition system. Delivering such a model presents numerous challenges: It should improve the performance when the input signal consists of overlapped speech, and must not hurt the speech recognition performance under all other acoustic conditions. Besides, this model must be tiny, fast, and perform inference in a streaming fashion, in order to have minimal impact on CPU, memory, battery and latency. We propose novel techniques to meet these multi-faceted requirements, including using a new asymmetric loss, and adopting adaptive runtime suppression strength. We also show that such a model can be quantized as a 8-bit integer model and run in realtime.
Streaming End-to-end Speech Recognition For Mobile Devices
Nov 15, 2018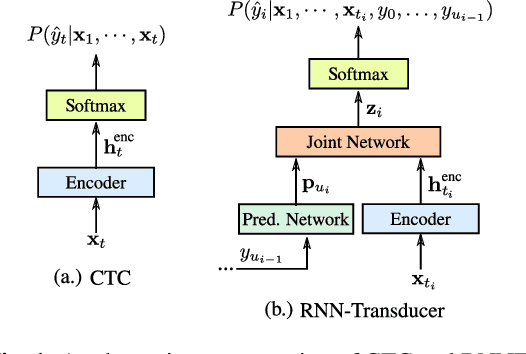
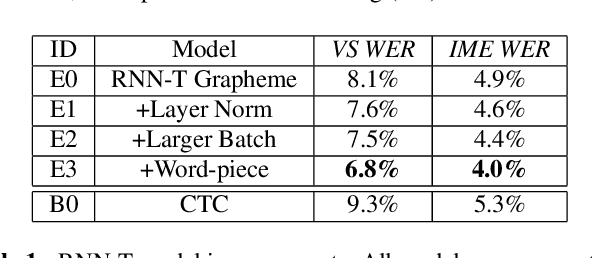
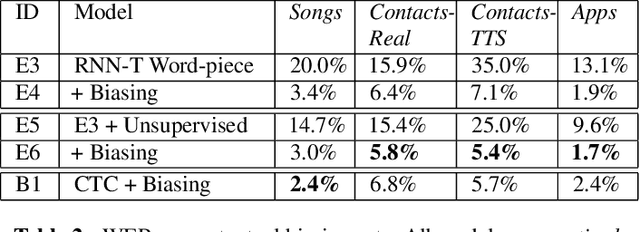
End-to-end (E2E) models, which directly predict output character sequences given input speech, are good candidates for on-device speech recognition. E2E models, however, present numerous challenges: In order to be truly useful, such models must decode speech utterances in a streaming fashion, in real time; they must be robust to the long tail of use cases; they must be able to leverage user-specific context (e.g., contact lists); and above all, they must be extremely accurate. In this work, we describe our efforts at building an E2E speech recognizer using a recurrent neural network transducer. In experimental evaluations, we find that the proposed approach can outperform a conventional CTC-based model in terms of both latency and accuracy in a number of evaluation categories.
Personalized Speech recognition on mobile devices
Mar 11, 2016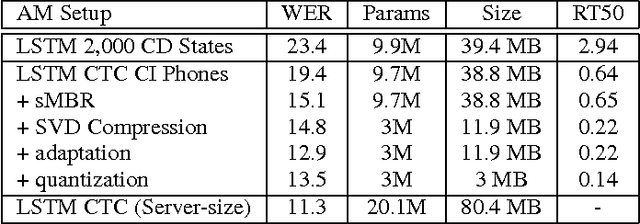
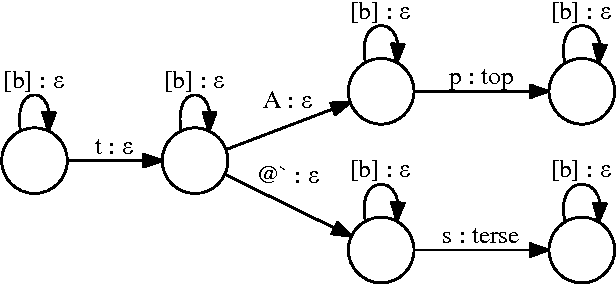

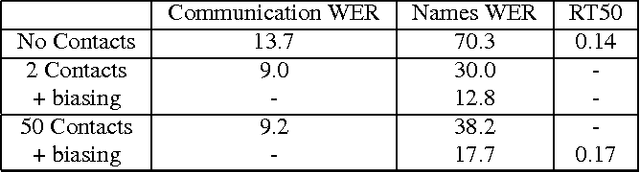
We describe a large vocabulary speech recognition system that is accurate, has low latency, and yet has a small enough memory and computational footprint to run faster than real-time on a Nexus 5 Android smartphone. We employ a quantized Long Short-Term Memory (LSTM) acoustic model trained with connectionist temporal classification (CTC) to directly predict phoneme targets, and further reduce its memory footprint using an SVD-based compression scheme. Additionally, we minimize our memory footprint by using a single language model for both dictation and voice command domains, constructed using Bayesian interpolation. Finally, in order to properly handle device-specific information, such as proper names and other context-dependent information, we inject vocabulary items into the decoder graph and bias the language model on-the-fly. Our system achieves 13.5% word error rate on an open-ended dictation task, running with a median speed that is seven times faster than real-time.