 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSM-SCD: Multilingual Speaker Change Detection Based on Large Pretrained Foundation Models
Sep 14, 2023We introduce a multilingual speaker change detection model (USM-SCD) that can simultaneously detect speaker turns and perform ASR for 96 languages. This model is adapted from a speech foundation model trained on a large quantity of supervised and unsupervised data, demonstrating the utility of fine-tuning from a large generic foundation model for a downstream task. We analyze the performance of this multilingual speaker change detection model through a series of ablation studies. We show that the USM-SCD model can achieve more than 75% average speaker change detection F1 score across a test set that consists of data from 96 languages. On American English, the USM-SCD model can achieve an 85.8% speaker change detection F1 score across various public and internal test sets, beating the previous monolingual baseline model by 21% relative. We also show that we only need to fine-tune one-quarter of the trainable model parameters to achieve the best model performance. The USM-SCD model exhibits state-of-the-art ASR quality compared with a strong public ASR baseline, making it suitable to handle both tasks with negligible additional computational cost.
Attentive Temporal Pooling for Conformer-based Streaming Language Identification in Long-form Speech
Mar 21, 2022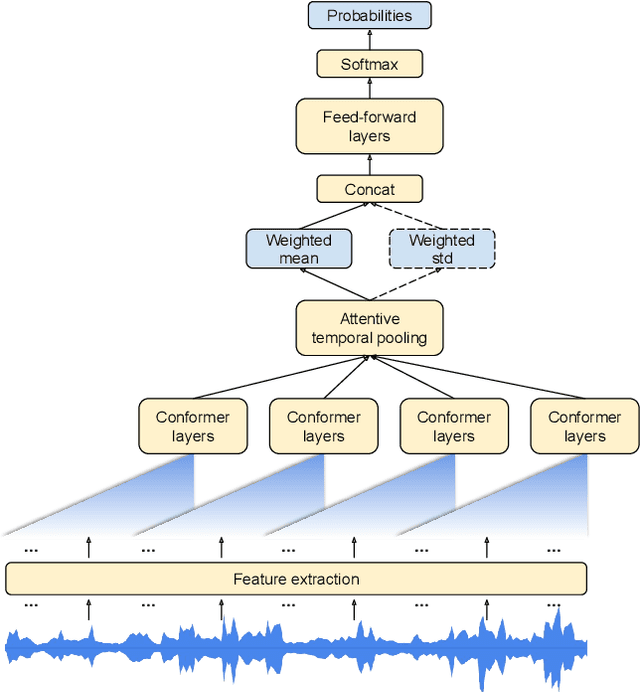
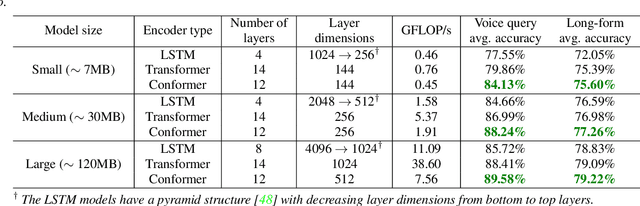
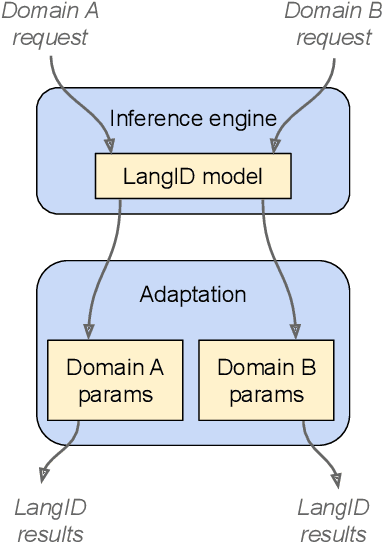
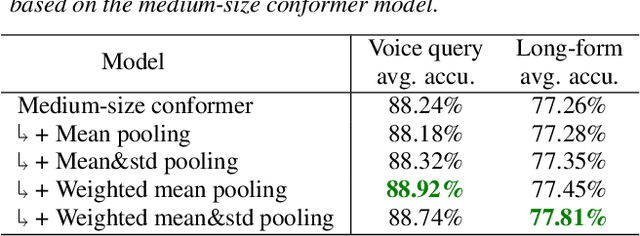
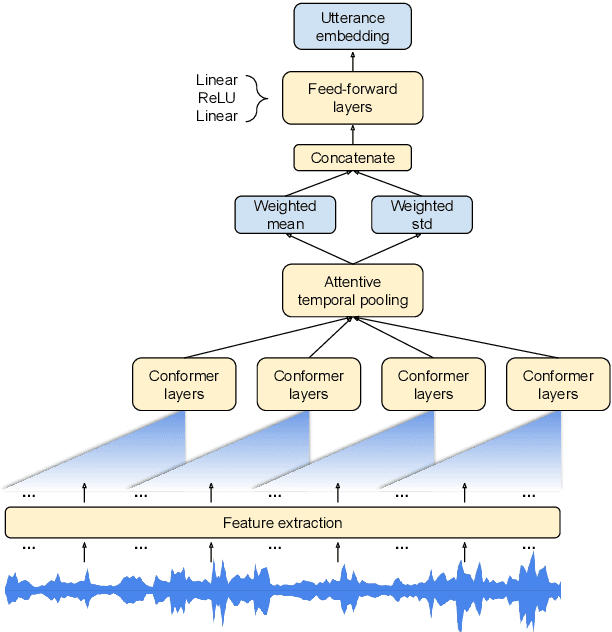
In this paper, we introduce a novel language identification system based on conformer layers. We propose an attentive temporal pooling mechanism to allow the model to carry information in long-form audio via a recurrent form, such that the inference can be performed in a streaming fashion. Additionally, a simple domain adaptation mechanism is introduced to allow adapting an existing language identification model to a new domain where the prior language distribution is different. We perform a comparative study of different model topologies under different constraints of model size, and find that conformer-base models outperform LSTM and transformer based models. Our experiments also show that attentive temporal pooling and domain adaptation significantly improve the model accuracy.
Parameter-Free Attentive Scoring for Speaker Verification
Mar 10, 2022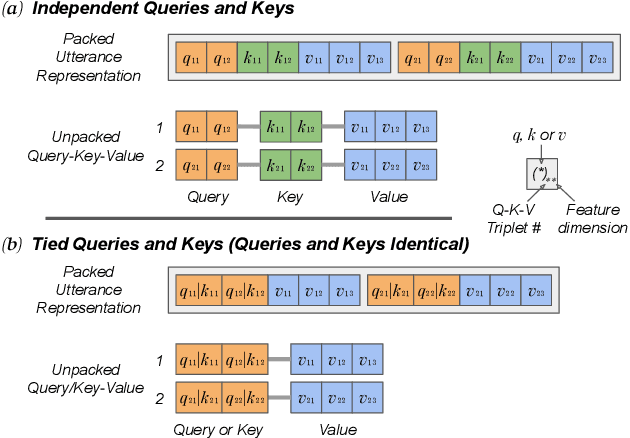
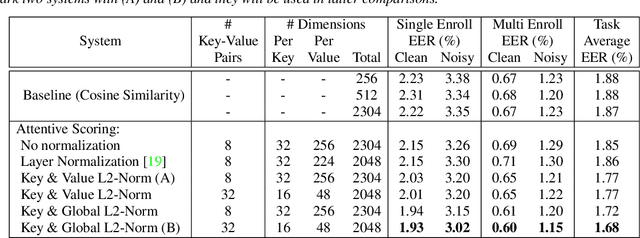
This paper presents a novel study of parameter-free attentive scoring for speaker verification. Parameter-free scoring provides the flexibility of comparing speaker representations without the need of an accompanying parametric scoring model. Inspired by the attention component in Transformer neural networks, we propose a variant of the scaled dot product attention mechanism to compare enrollment and test segment representations. In addition, this work explores the effect on performance of (i) different types of normalization, (ii) independent versus tied query/key estimation, (iii) varying the number of key-value pairs and (iv) pooling multiple enrollment utterance statistics. Experimental results for a 4 task average show that a simple parameter-free attentive scoring mechanism can improve the average EER by 10% over the best cosine similarity baseline.
SpeakerStew: Scaling to Many Languages with a Triaged Multilingual Text-Dependent and Text-Independent Speaker Verification System
Apr 26, 2021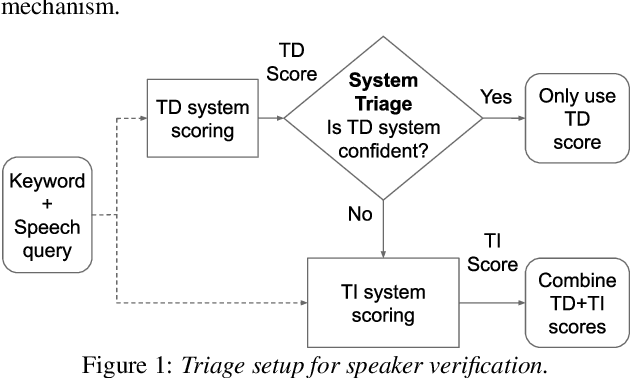
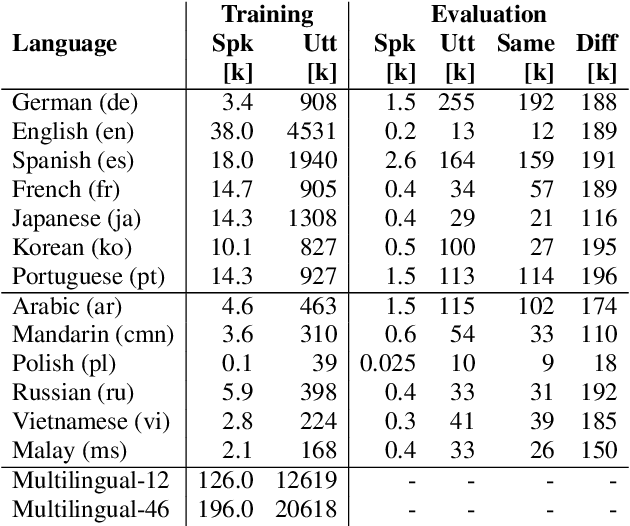
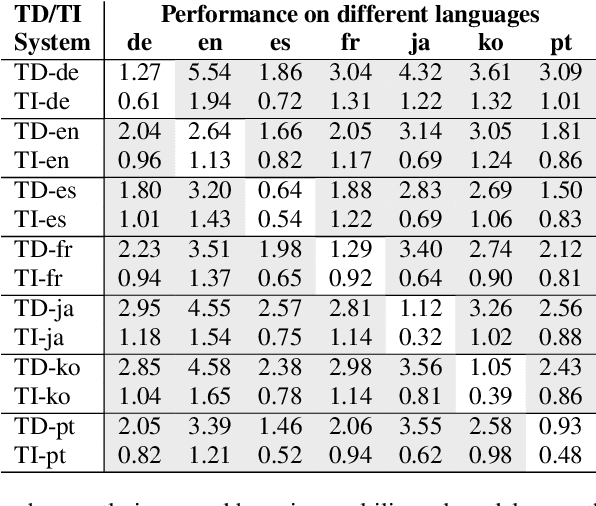
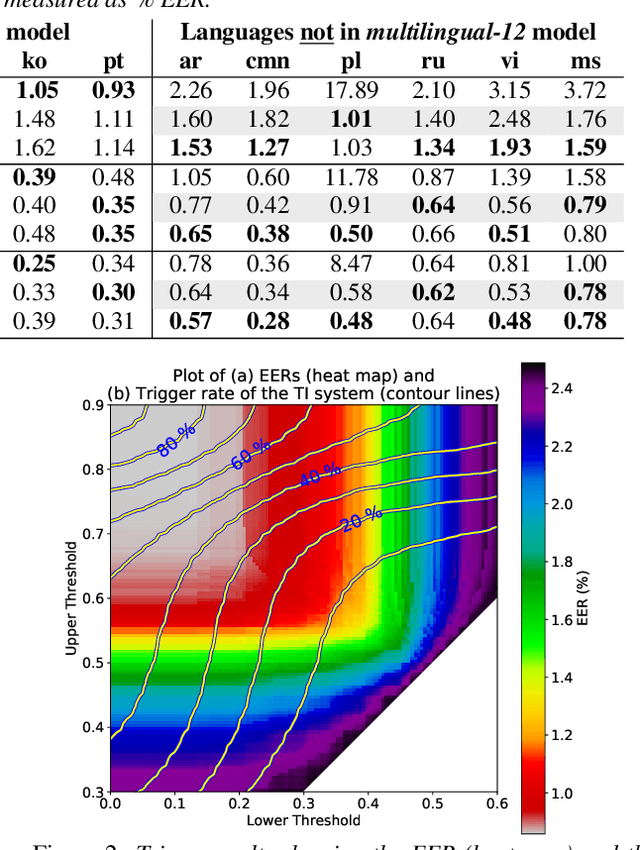
In this paper, we describe SpeakerStew - a hybrid system to perform speaker verification on 46 languages. Two core ideas were explored in this system: (1) Pooling training data of different languages together for multilingual generalization and reducing development cycles; (2) A triage mechanism between text-dependent and text-independent models to reduce runtime cost and expected latency. To the best of our knowledge, this is the first study of speaker verification systems at the scale of 46 languages. The problem is framed from the perspective of using a smart speaker device with interactions consisting of a wake-up keyword (text-dependent) followed by a speech query (text-independent).Experimental evidence suggests that training on multiple languages can generalize to unseen varieties while maintaining performance on seen varieties. We also found that it can reduce computational requirements for training models by an order of magnitude. Furthermore, during model inference on English data, we observe that leveraging a triage framework can reduce the number of calls to the more computationally expensive text-independent system by 73% (and reduce latency by 60%) while maintaining an EER no worse than the text-independent setup.
Dr-Vectors: Decision Residual Networks and an Improved Loss for Speaker Recognition
Apr 05, 2021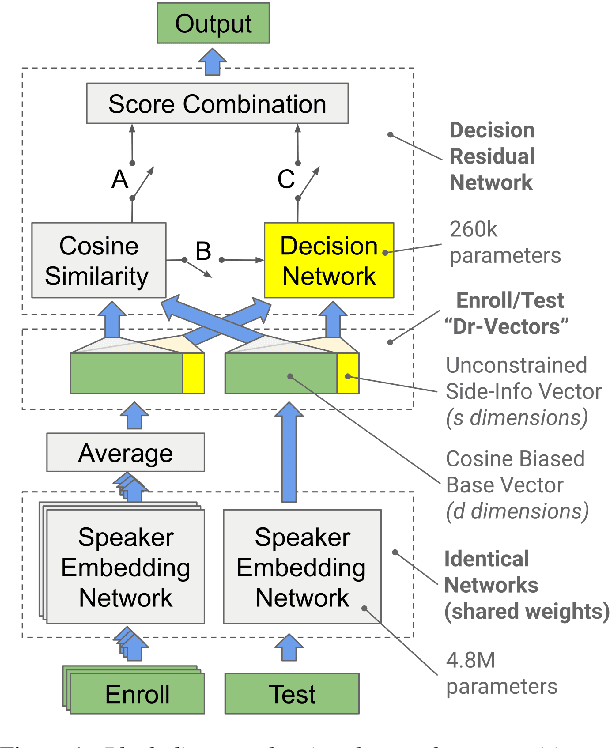
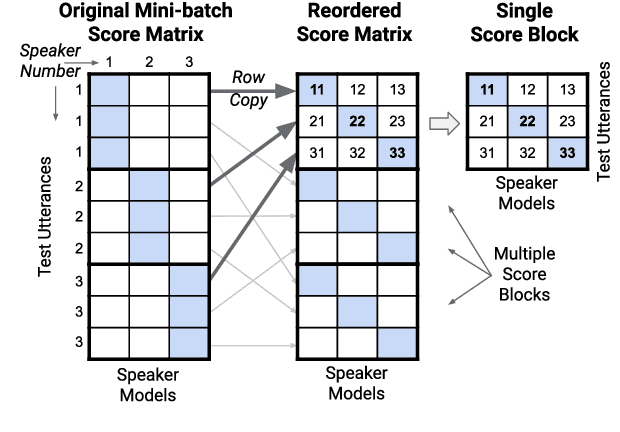
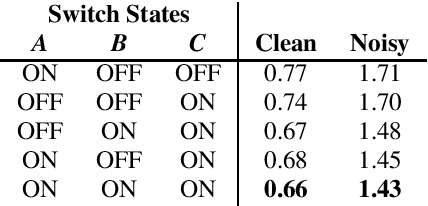
Many neural network speaker recognition systems model each speaker using a fixed-dimensional embedding vector. These embeddings are generally compared using either linear or 2nd-order scoring and, until recently, do not handle utterance-specific uncertainty. In this work we propose scoring these representations in a way that can capture uncertainty, enroll/test asymmetry and additional non-linear information. This is achieved by incorporating a 2nd-stage neural network (known as a decision network) as part of an end-to-end training regimen. In particular, we propose the concept of decision residual networks which involves the use of a compact decision network to leverage cosine scores and to model the residual signal that's needed. Additionally, we present a modification to the generalized end-to-end softmax loss function to better target the separation of same/different speaker scores. We observed significant performance gains for the two techniques.
Synth2Aug: Cross-domain speaker recognition with TTS synthesized speech
Nov 24, 2020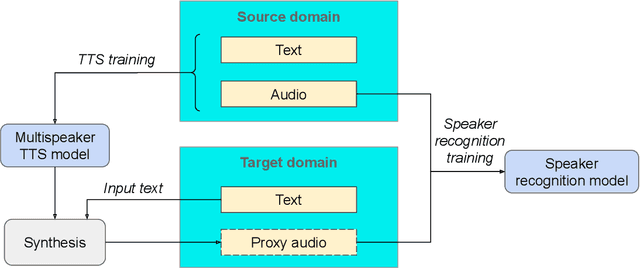
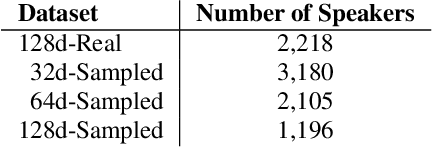
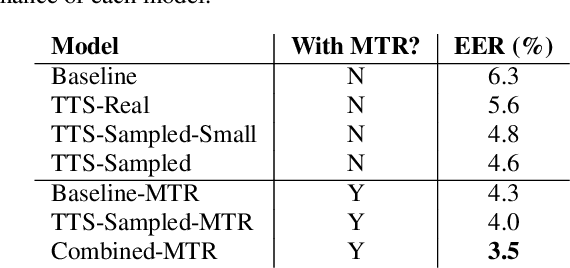
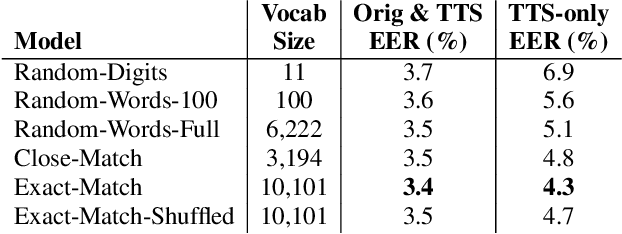
In recent years, Text-To-Speech (TTS) has been used as a data augmentation technique for speech recognition to help complement inadequacies in the training data. Correspondingly, we investigate the use of a multi-speaker TTS system to synthesize speech in support of speaker recognition. In this study we focus the analysis on tasks where a relatively small number of speakers is available for training. We observe on our datasets that TTS synthesized speech improves cross-domain speaker recognition performance and can be combined effectively with multi-style training. Additionally, we explore the effectiveness of different types of text transcripts used for TTS synthesis. Results suggest that matching the textual content of the target domain is a good practice, and if that is not feasible, a transcript with a sufficiently large vocabulary is recommended.
VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition
Sep 09, 2020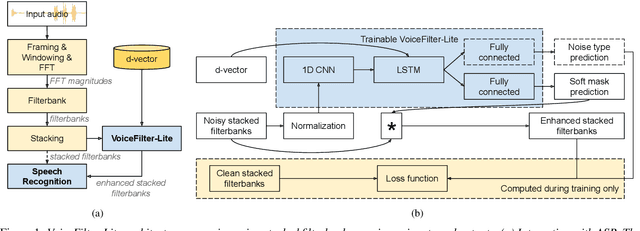

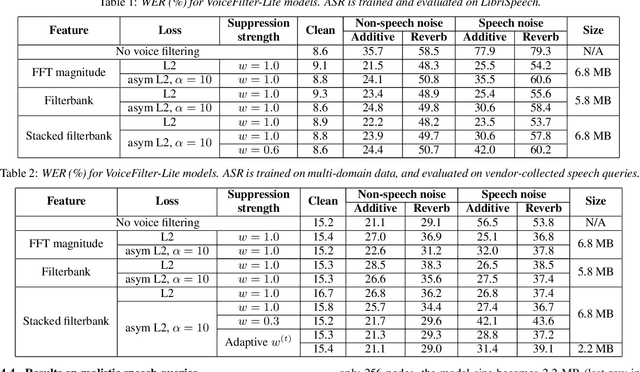
We introduce VoiceFilter-Lite, a single-channel source separation model that runs on the device to preserve only the speech signals from a target user, as part of a streaming speech recognition system. Delivering such a model presents numerous challenges: It should improve the performance when the input signal consists of overlapped speech, and must not hurt the speech recognition performance under all other acoustic conditions. Besides, this model must be tiny, fast, and perform inference in a streaming fashion, in order to have minimal impact on CPU, memory, battery and latency. We propose novel techniques to meet these multi-faceted requirements, including using a new asymmetric loss, and adopting adaptive runtime suppression strength. We also show that such a model can be quantized as a 8-bit integer model and run in realtime.
The IBM Speaker Recognition System: Recent Advances and Error Analysis
May 05, 2016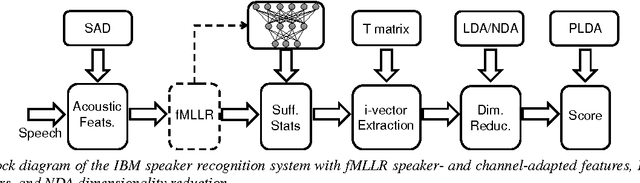
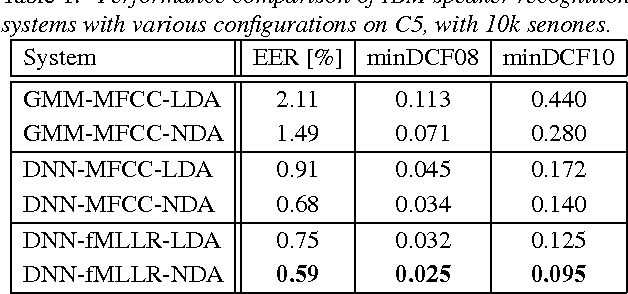
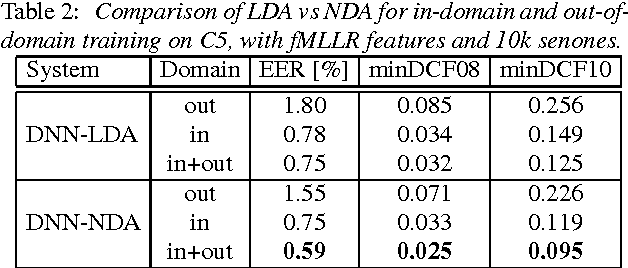
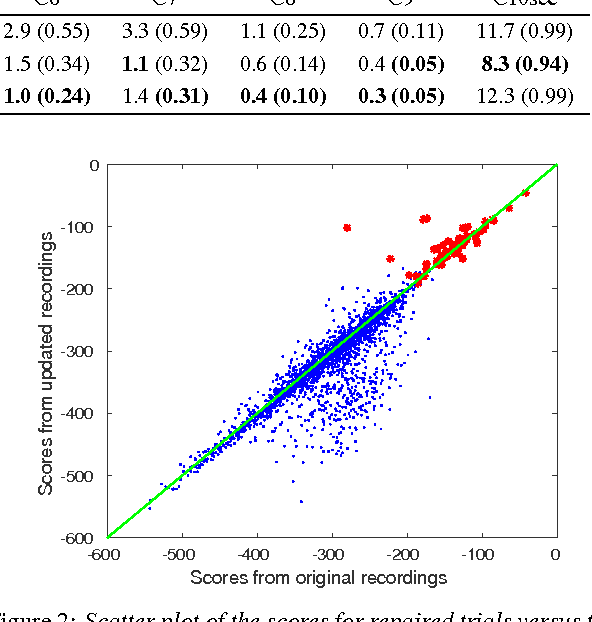
We present the recent advances along with an error analysis of the IBM speaker recognition system for conversational speech. Some of the key advancements that contribute to our system include: a nearest-neighbor discriminant analysis (NDA) approach (as opposed to LDA) for intersession variability compensation in the i-vector space, the application of speaker and channel-adapted features derived from an automatic speech recognition (ASR) system for speaker recognition, and the use of a DNN acoustic model with a very large number of output units (~10k senones) to compute the frame-level soft alignments required in the i-vector estimation process. We evaluate these techniques on the NIST 2010 SRE extended core conditions (C1-C9), as well as the 10sec-10sec condition. To our knowledge, results achieved by our system represent the best performances published to date on these conditions. For example, on the extended tel-tel condition (C5) the system achieves an EER of 0.59%. To garner further understanding of the remaining errors (on C5), we examine the recordings associated with the low scoring target trials, where various issues are identified for the problematic recordings/trials. Interestingly, it is observed that correcting the pathological recordings not only improves the scores for the target trials but also for the nontarget trials.