 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Free Attentive Scoring for Speaker Verification
Paper and Code
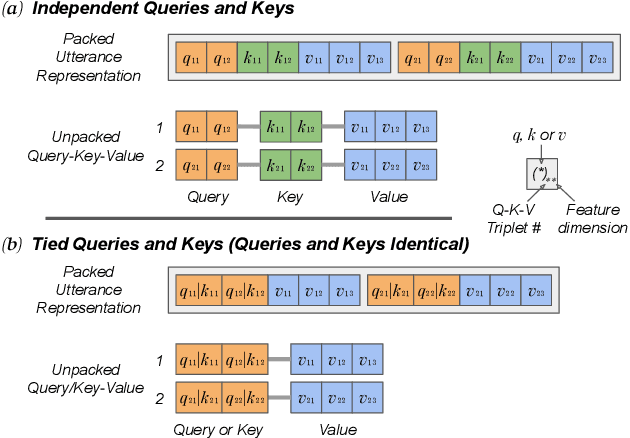
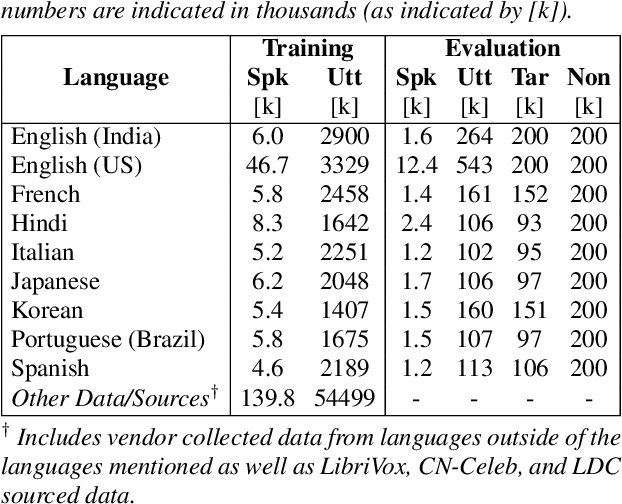
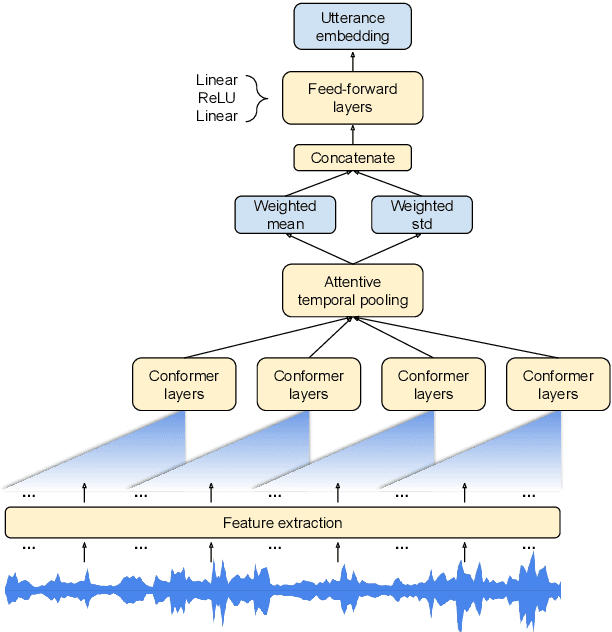
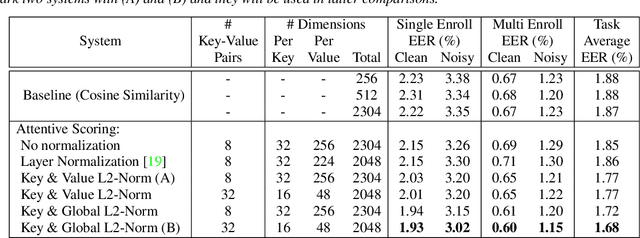
This paper presents a novel study of parameter-free attentive scoring for speaker verification. Parameter-free scoring provides the flexibility of comparing speaker representations without the need of an accompanying parametric scoring model. Inspired by the attention component in Transformer neural networks, we propose a variant of the scaled dot product attention mechanism to compare enrollment and test segment representations. In addition, this work explores the effect on performance of (i) different types of normalization, (ii) independent versus tied query/key estimation, (iii) varying the number of key-value pairs and (iv) pooling multiple enrollment utterance statistics. Experimental results for a 4 task average show that a simple parameter-free attentive scoring mechanism can improve the average EER by 10% over the best cosine similarity baseline.