 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxWatch: An open-set speaker recognition benchmark on VoxCeleb
Jun 30, 2023



Despite its broad practical applications such as in fraud prevention, open-set speaker identification (OSI) has received less attention in the speaker recognition community compared to speaker verification (SV). OSI deals with determining if a test speech sample belongs to a speaker from a set of pre-enrolled individuals (in-set) or if it is from an out-of-set speaker. In addition to the typical challenges associated with speech variability, OSI is prone to the "false-alarm problem"; as the size of the in-set speaker population (a.k.a watchlist) grows, the out-of-set scores become larger, leading to increased false alarm rates. This is in particular challenging for applications in financial institutions and border security where the watchlist size is typically of the order of several thousand speakers. Therefore, it is important to systematically quantify the false-alarm problem, and develop techniques that alleviate the impact of watchlist size on detection performance. Prior studies on this problem are sparse, and lack a common benchmark for systematic evaluations. In this paper, we present the first public benchmark for OSI, developed using the VoxCeleb dataset. We quantify the effect of the watchlist size and speech duration on the watchlist-based speaker detection task using three strong neural network based systems. In contrast to the findings from prior research, we show that the commonly adopted adaptive score normalization is not guaranteed to improve the performance for this task. On the other hand, we show that score calibration and score fusion, two other commonly used techniques in SV, result in significant improvements in OSI performance.
The 2021 NIST Speaker Recognition Evaluation
Apr 21, 2022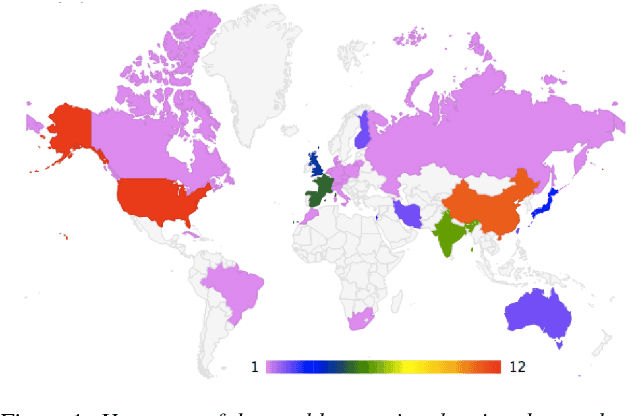
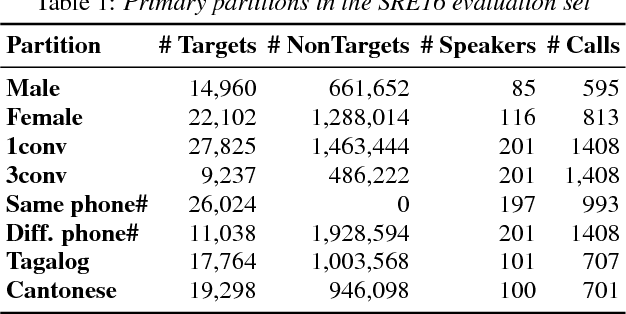
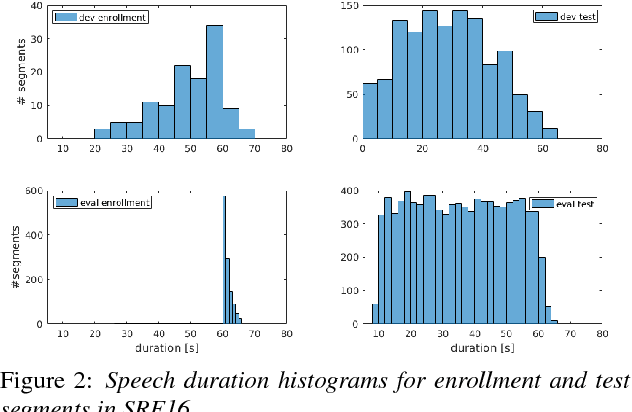
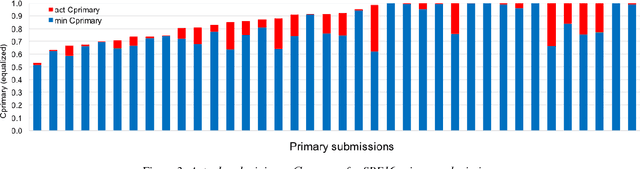
The 2021 Speaker Recognition Evaluation (SRE21) was the latest cycle of the ongoing evaluation series conducted by the U.S. National Institute of Standards and Technology (NIST) since 1996. It was the second large-scale multimodal speaker/person recognition evaluation organized by NIST (the first one being SRE19). Similar to SRE19, it featured two core evaluation tracks, namely audio and audio-visual, as well as an optional visual track. In addition to offering fixed and open training conditions, it also introduced new challenges for the community, thanks to a new multimodal (i.e., audio, video, and selfie images) and multilingual (i.e., with multilingual speakers) corpus, termed WeCanTalk, collected outside North America by the Linguistic Data Consortium (LDC). These challenges included: 1) trials (target and non-target) with enrollment and test segments originating from different domains (i.e., telephony versus video), and 2) trials (target and non-target) with enrollment and test segments spoken in different languages (i.e., cross-lingual trials). This paper presents an overview of SRE21 including the tasks, performance metric, data, evaluation protocol, results and system performance analyses. A total of 23 organizations (forming 15 teams) from academia and industry participated in SRE21 and submitted 158 valid system outputs. Evaluation results indicate: audio-visual fusion produce substantial gains in performance over audio-only or visual-only systems; top performing speaker and face recognition systems exhibited comparable performance under the matched domain conditions present in this evaluation; and, the use of complex neural network architectures (e.g., ResNet) along with angular losses with margin, data augmentation, as well as long duration fine-tuning contributed to notable performance improvements for the audio-only speaker recognition task.
The NIST CTS Speaker Recognition Challenge
Apr 21, 2022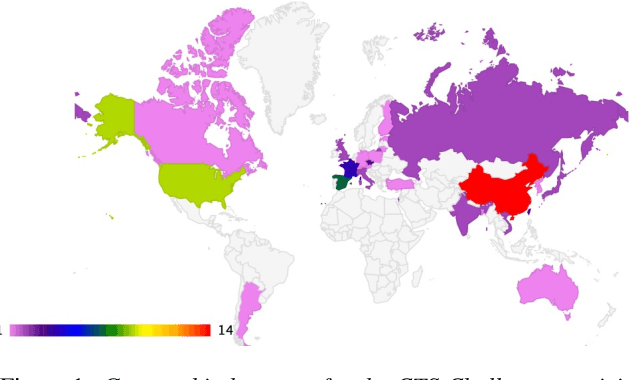
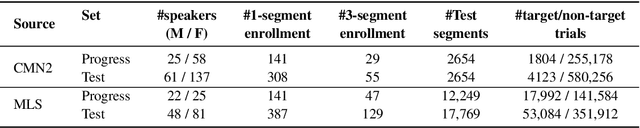
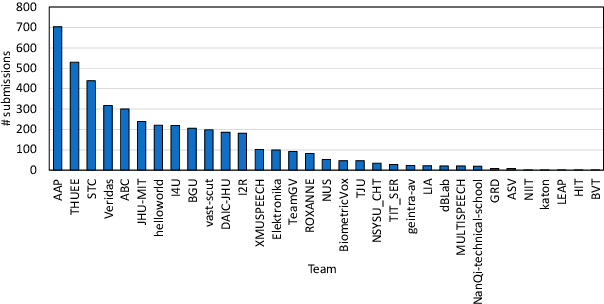
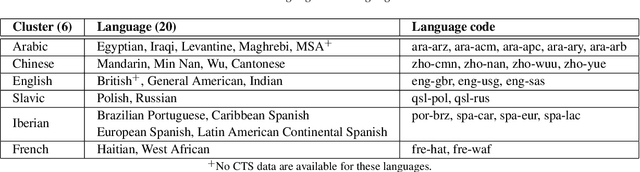
The US National Institute of Standards and Technology (NIST) has been conducting a second iteration of the CTS challenge since August 2020. The current iteration of the CTS Challenge is a leaderboard-style speaker recognition evaluation using telephony data extracted from the unexposed portions of the Call My Net 2 (CMN2) and Multi-Language Speech (MLS) corpora collected by the LDC. The CTS Challenge is currently organized in a similar manner to the SRE19 CTS Challenge, offering only an open training condition using two evaluation subsets, namely Progress and Test. Unlike in the SRE19 Challenge, no training or development set was initially released, and NIST has publicly released the leaderboards on both subsets for the CTS Challenge. Which subset (i.e., Progress or Test) a trial belongs to is unknown to challenge participants, and each system submission needs to contain outputs for all of the trials. The CTS Challenge has also served, and will continue to do so, as a prerequisite for entrance to the regular SREs (such as SRE21). Since August 2020, a total of 53 organizations (forming 33 teams) from academia and industry have participated in the CTS Challenge and submitted more than 4400 valid system outputs. This paper presents an overview of the evaluation and several analyses of system performance for some primary conditions in the CTS Challenge. The CTS Challenge results thus far indicate remarkable improvements in performance due to 1) speaker embeddings extracted using large-scale and complex neural network architectures such as ResNets along with angular margin losses for speaker embedding extraction, 2) extensive data augmentation, 3) the use of large amounts of in-house proprietary data from a large number of labeled speakers, 4) long-duration fine-tuning.
Multimodal Emotion Recognition using Transfer Learning from Speaker Recognition and BERT-based models
Feb 16, 2022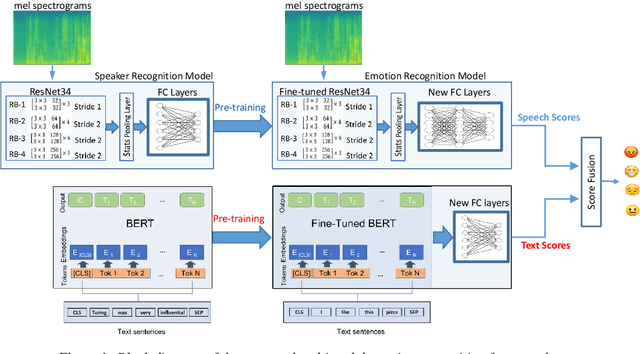
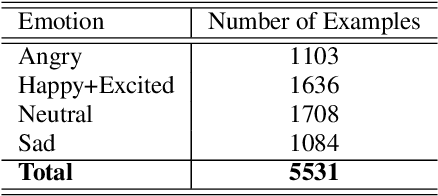
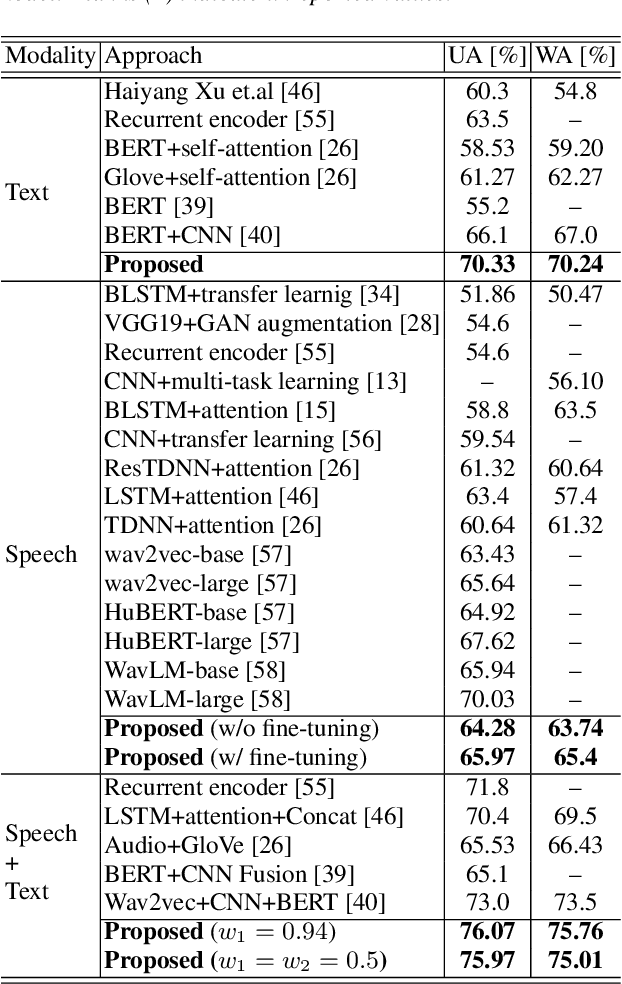
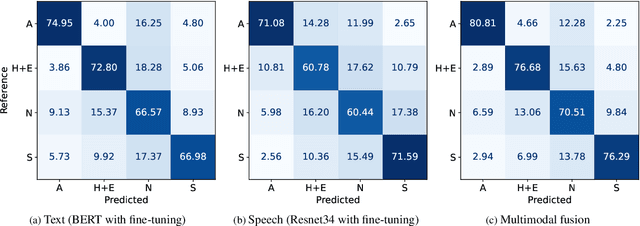
Automatic emotion recognition plays a key role in computer-human interaction as it has the potential to enrich the next-generation artificial intelligence with emotional intelligence. It finds applications in customer and/or representative behavior analysis in call centers, gaming, personal assistants, and social robots, to mention a few. Therefore, there has been an increasing demand to develop robust automatic methods to analyze and recognize the various emotions. In this paper, we propose a neural network-based emotion recognition framework that uses a late fusion of transfer-learned and fine-tuned models from speech and text modalities. More specifically, we i) adapt a residual network (ResNet) based model trained on a large-scale speaker recognition task using transfer learning along with a spectrogram augmentation approach to recognize emotions from speech, and ii) use a fine-tuned bidirectional encoder representations from transformers (BERT) based model to represent and recognize emotions from the text. The proposed system then combines the ResNet and BERT-based model scores using a late fusion strategy to further improve the emotion recognition performance. The proposed multimodal solution addresses the data scarcity limitation in emotion recognition using transfer learning, data augmentation, and fine-tuning, thereby improving the generalization performance of the emotion recognition models. We evaluate the effectiveness of our proposed multimodal approach on the interactive emotional dyadic motion capture (IEMOCAP) dataset. Experimental results indicate that both audio and text-based models improve the emotion recognition performance and that the proposed multimodal solution achieves state-of-the-art results on the IEMOCAP benchmark.
Improved Speech Emotion Recognition using Transfer Learning and Spectrogram Augmentation
Aug 16, 2021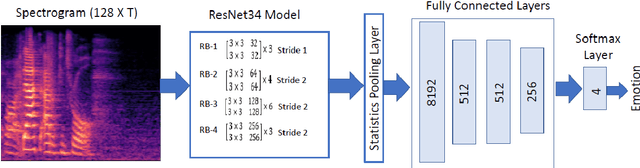
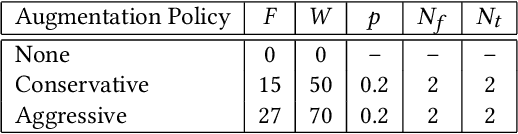
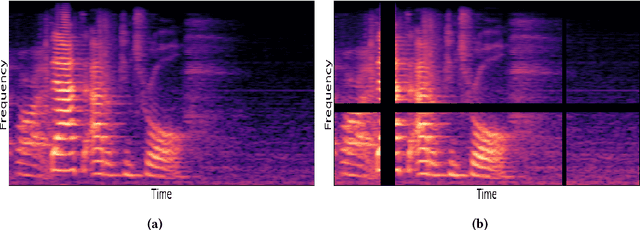
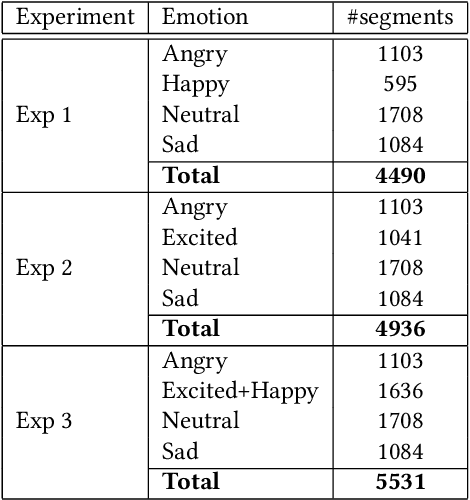
Automatic speech emotion recognition (SER) is a challenging task that plays a crucial role in natural human-computer interaction. One of the main challenges in SER is data scarcity, i.e., insufficient amounts of carefully labeled data to build and fully explore complex deep learning models for emotion classification. This paper aims to address this challenge using a transfer learning strategy combined with spectrogram augmentation. Specifically, we propose a transfer learning approach that leverages a pre-trained residual network (ResNet) model including a statistics pooling layer from speaker recognition trained using large amounts of speaker-labeled data. The statistics pooling layer enables the model to efficiently process variable-length input, thereby eliminating the need for sequence truncation which is commonly used in SER systems. In addition, we adopt a spectrogram augmentation technique to generate additional training data samples by applying random time-frequency masks to log-mel spectrograms to mitigate overfitting and improve the generalization of emotion recognition models. We evaluate the effectiveness of our proposed approach on the interactive emotional dyadic motion capture (IEMOCAP) dataset. Experimental results indicate that the transfer learning and spectrogram augmentation approaches improve the SER performance, and when combined achieve state-of-the-art results.
NIST SRE CTS Superset: A large-scale dataset for telephony speaker recognition
Aug 16, 2021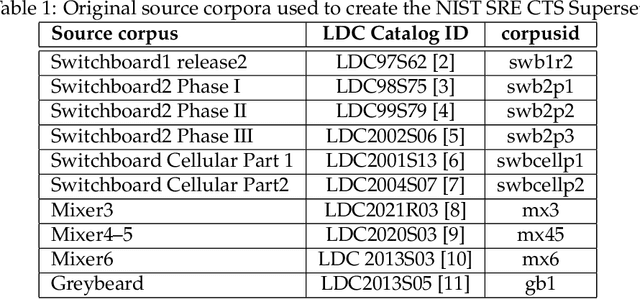
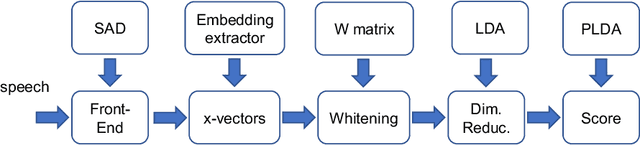
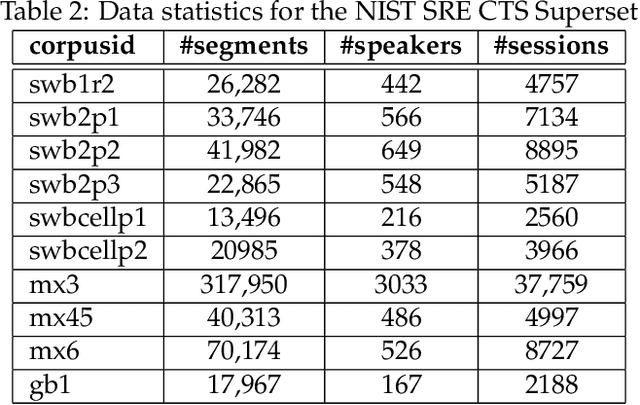
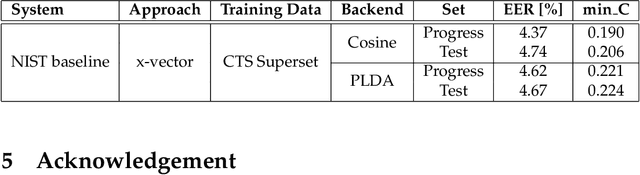
This document provides a brief description of the National Institute of Standards and Technology (NIST) speaker recognition evaluation (SRE) conversational telephone speech (CTS) Superset. The CTS Superset has been created in an attempt to provide the research community with a large-scale dataset along with uniform metadata that can be used to effectively train and develop telephony (narrowband) speaker recognition systems. It contains a large number of telephony speech segments from more than 6800 speakers with speech durations distributed uniformly in the [10s, 60s] range. The segments have been extracted from the source corpora used to compile prior SRE datasets (SRE1996-2012), including the Greybeard corpus as well as the Switchboard and Mixer series collected by the Linguistic Data Consortium (LDC). In addition to the brief description, we also report speaker recognition results on the NIST 2020 CTS Speaker Recognition Challenge, obtained using a system trained with the CTS Superset. The results will serve as a reference baseline for the challenge.
The IBM Speaker Recognition System: Recent Advances and Error Analysis
May 05, 2016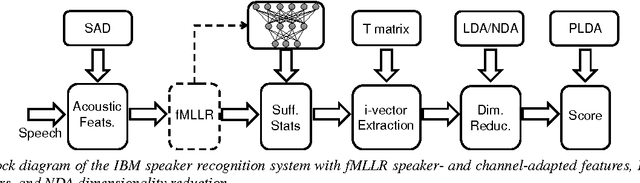
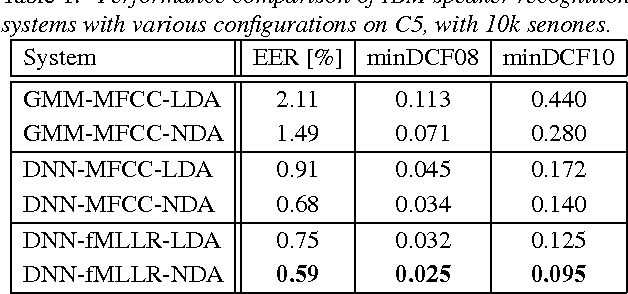
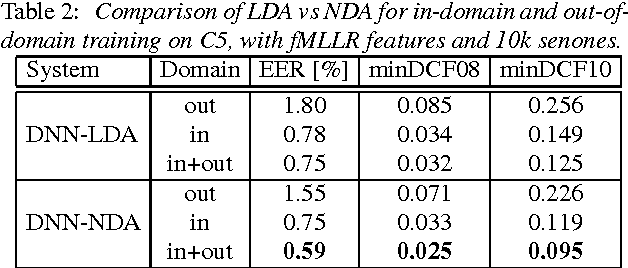
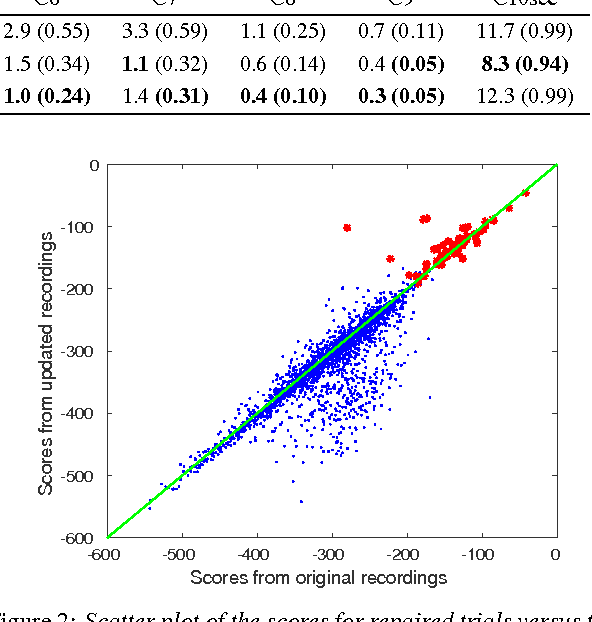
We present the recent advances along with an error analysis of the IBM speaker recognition system for conversational speech. Some of the key advancements that contribute to our system include: a nearest-neighbor discriminant analysis (NDA) approach (as opposed to LDA) for intersession variability compensation in the i-vector space, the application of speaker and channel-adapted features derived from an automatic speech recognition (ASR) system for speaker recognition, and the use of a DNN acoustic model with a very large number of output units (~10k senones) to compute the frame-level soft alignments required in the i-vector estimation process. We evaluate these techniques on the NIST 2010 SRE extended core conditions (C1-C9), as well as the 10sec-10sec condition. To our knowledge, results achieved by our system represent the best performances published to date on these conditions. For example, on the extended tel-tel condition (C5) the system achieves an EER of 0.59%. To garner further understanding of the remaining errors (on C5), we examine the recordings associated with the low scoring target trials, where various issues are identified for the problematic recordings/trials. Interestingly, it is observed that correcting the pathological recordings not only improves the scores for the target trials but also for the nontarget trials.
The IBM 2016 Speaker Recognition System
Feb 23, 2016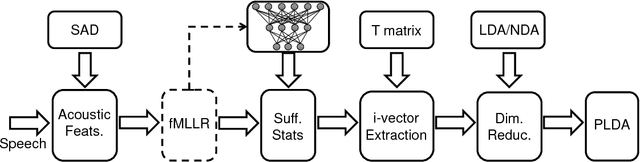


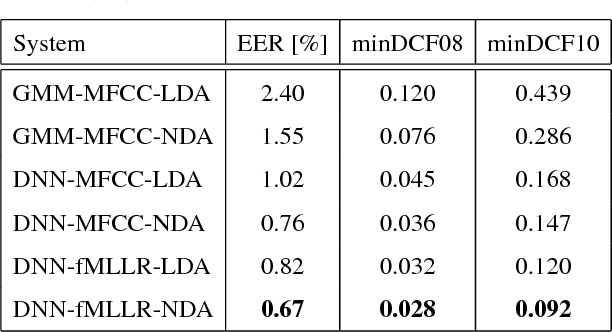
In this paper we describe the recent advancements made in the IBM i-vector speaker recognition system for conversational speech. In particular, we identify key techniques that contribute to significant improvements in performance of our system, and quantify their contributions. The techniques include: 1) a nearest-neighbor discriminant analysis (NDA) approach that is formulated to alleviate some of the limitations associated with the conventional linear discriminant analysis (LDA) that assumes Gaussian class-conditional distributions, 2) the application of speaker- and channel-adapted features, which are derived from an automatic speech recognition (ASR) system, for speaker recognition, and 3) the use of a deep neural network (DNN) acoustic model with a large number of output units (~10k senones) to compute the frame-level soft alignments required in the i-vector estimation process. We evaluate these techniques on the NIST 2010 speaker recognition evaluation (SRE) extended core conditions involving telephone and microphone trials. Experimental results indicate that: 1) the NDA is more effective (up to 35% relative improvement in terms of EER) than the traditional parametric LDA for speaker recognition, 2) when compared to raw acoustic features (e.g., MFCCs), the ASR speaker-adapted features provide gains in speaker recognition performance, and 3) increasing the number of output units in the DNN acoustic model (i.e., increasing the senone set size from 2k to 10k) provides consistent improvements in performance (for example from 37% to 57% relative EER gains over our baseline GMM i-vector system). To our knowledge, results reported in this paper represent the best performances published to date on the NIST SRE 2010 extended core tasks.