 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe IBM 2016 Speaker Recognition System
Paper and Code
Feb 23, 2016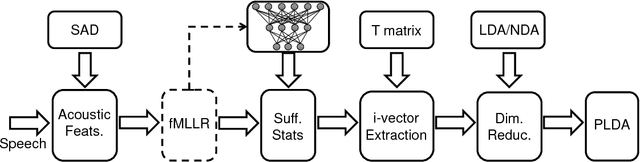


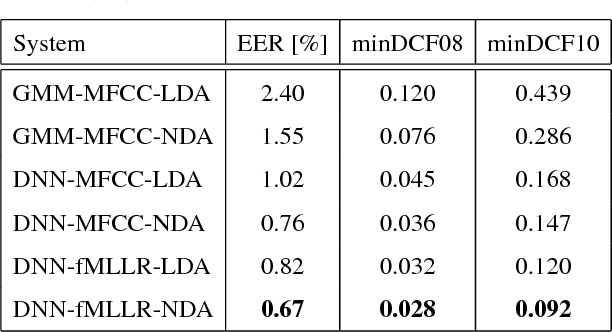
In this paper we describe the recent advancements made in the IBM i-vector speaker recognition system for conversational speech. In particular, we identify key techniques that contribute to significant improvements in performance of our system, and quantify their contributions. The techniques include: 1) a nearest-neighbor discriminant analysis (NDA) approach that is formulated to alleviate some of the limitations associated with the conventional linear discriminant analysis (LDA) that assumes Gaussian class-conditional distributions, 2) the application of speaker- and channel-adapted features, which are derived from an automatic speech recognition (ASR) system, for speaker recognition, and 3) the use of a deep neural network (DNN) acoustic model with a large number of output units (~10k senones) to compute the frame-level soft alignments required in the i-vector estimation process. We evaluate these techniques on the NIST 2010 speaker recognition evaluation (SRE) extended core conditions involving telephone and microphone trials. Experimental results indicate that: 1) the NDA is more effective (up to 35% relative improvement in terms of EER) than the traditional parametric LDA for speaker recognition, 2) when compared to raw acoustic features (e.g., MFCCs), the ASR speaker-adapted features provide gains in speaker recognition performance, and 3) increasing the number of output units in the DNN acoustic model (i.e., increasing the senone set size from 2k to 10k) provides consistent improvements in performance (for example from 37% to 57% relative EER gains over our baseline GMM i-vector system). To our knowledge, results reported in this paper represent the best performances published to date on the NIST SRE 2010 extended core tasks.