 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe NIST CTS Speaker Recognition Challenge
Paper and Code
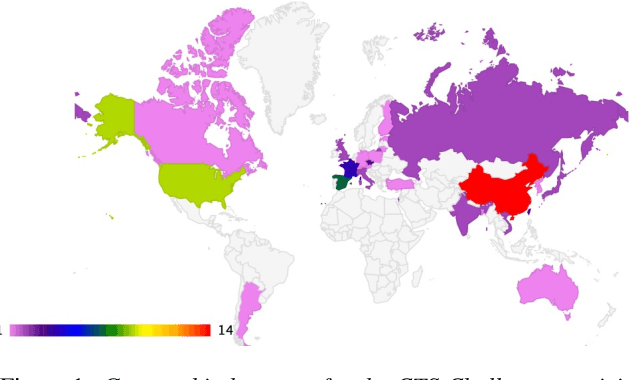
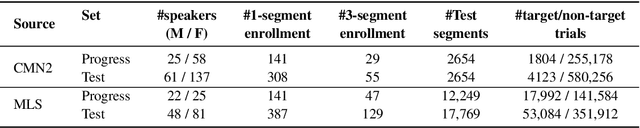
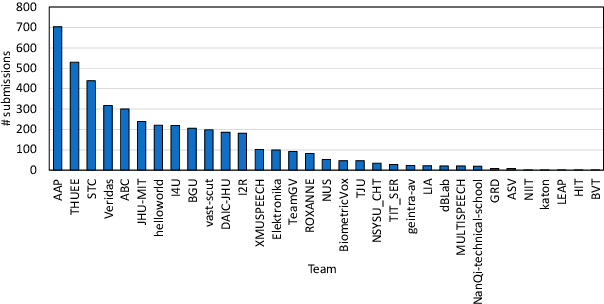
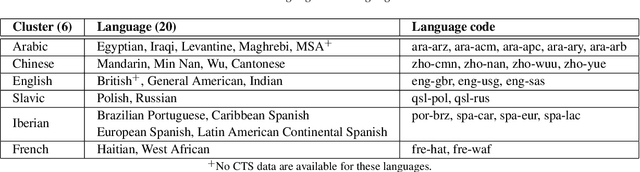
The US National Institute of Standards and Technology (NIST) has been conducting a second iteration of the CTS challenge since August 2020. The current iteration of the CTS Challenge is a leaderboard-style speaker recognition evaluation using telephony data extracted from the unexposed portions of the Call My Net 2 (CMN2) and Multi-Language Speech (MLS) corpora collected by the LDC. The CTS Challenge is currently organized in a similar manner to the SRE19 CTS Challenge, offering only an open training condition using two evaluation subsets, namely Progress and Test. Unlike in the SRE19 Challenge, no training or development set was initially released, and NIST has publicly released the leaderboards on both subsets for the CTS Challenge. Which subset (i.e., Progress or Test) a trial belongs to is unknown to challenge participants, and each system submission needs to contain outputs for all of the trials. The CTS Challenge has also served, and will continue to do so, as a prerequisite for entrance to the regular SREs (such as SRE21). Since August 2020, a total of 53 organizations (forming 33 teams) from academia and industry have participated in the CTS Challenge and submitted more than 4400 valid system outputs. This paper presents an overview of the evaluation and several analyses of system performance for some primary conditions in the CTS Challenge. The CTS Challenge results thus far indicate remarkable improvements in performance due to 1) speaker embeddings extracted using large-scale and complex neural network architectures such as ResNets along with angular margin losses for speaker embedding extraction, 2) extensive data augmentation, 3) the use of large amounts of in-house proprietary data from a large number of labeled speakers, 4) long-duration fine-tuning.