 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNIST SRE CTS Superset: A large-scale dataset for telephony speaker recognition
Paper and Code
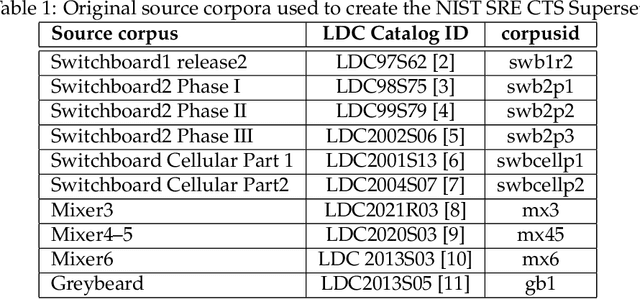
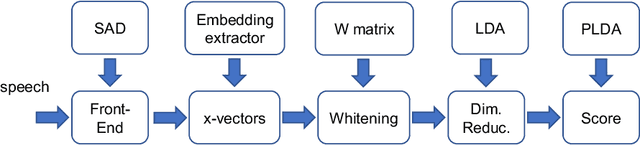
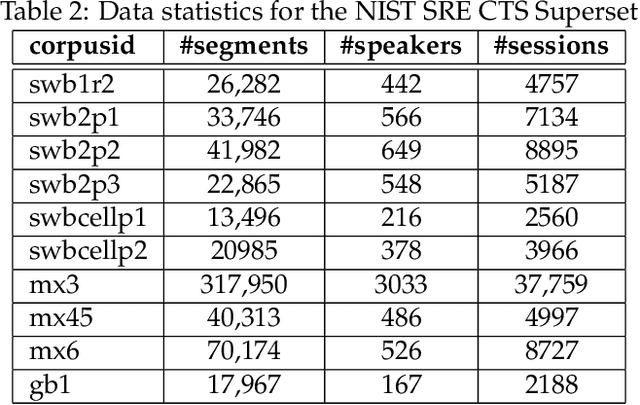
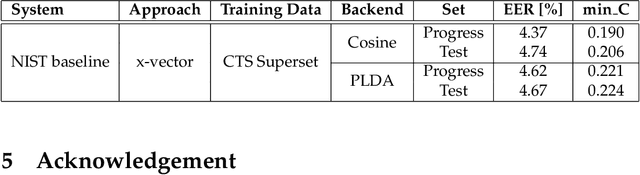
This document provides a brief description of the National Institute of Standards and Technology (NIST) speaker recognition evaluation (SRE) conversational telephone speech (CTS) Superset. The CTS Superset has been created in an attempt to provide the research community with a large-scale dataset along with uniform metadata that can be used to effectively train and develop telephony (narrowband) speaker recognition systems. It contains a large number of telephony speech segments from more than 6800 speakers with speech durations distributed uniformly in the [10s, 60s] range. The segments have been extracted from the source corpora used to compile prior SRE datasets (SRE1996-2012), including the Greybeard corpus as well as the Switchboard and Mixer series collected by the Linguistic Data Consortium (LDC). In addition to the brief description, we also report speaker recognition results on the NIST 2020 CTS Speaker Recognition Challenge, obtained using a system trained with the CTS Superset. The results will serve as a reference baseline for the challenge.