 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLineConGraphs: Line Conversation Graphs for Effective Emotion Recognition using Graph Neural Networks
Dec 04, 2023Emotion Recognition in Conversations (ERC) is a critical aspect of affective computing, and it has many practical applications in healthcare, education, chatbots, and social media platforms. Earlier approaches for ERC analysis involved modeling both speaker and long-term contextual information using graph neural network architectures. However, it is ideal to deploy speaker-independent models for real-world applications. Additionally, long context windows can potentially create confusion in recognizing the emotion of an utterance in a conversation. To overcome these limitations, we propose novel line conversation graph convolutional network (LineConGCN) and graph attention (LineConGAT) models for ERC analysis. These models are speaker-independent and built using a graph construction strategy for conversations -- line conversation graphs (LineConGraphs). The conversational context in LineConGraphs is short-term -- limited to one previous and future utterance, and speaker information is not part of the graph. We evaluate the performance of our proposed models on two benchmark datasets, IEMOCAP and MELD, and show that our LineConGAT model outperforms the state-of-the-art methods with an F1-score of 64.58% and 76.50%. Moreover, we demonstrate that embedding sentiment shift information into line conversation graphs further enhances the ERC performance in the case of GCN models.
Multimodal Emotion Recognition using Transfer Learning from Speaker Recognition and BERT-based models
Feb 16, 2022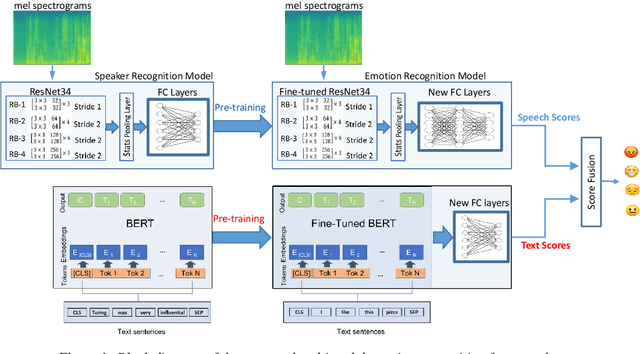
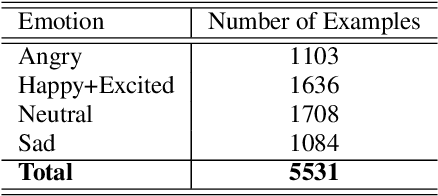
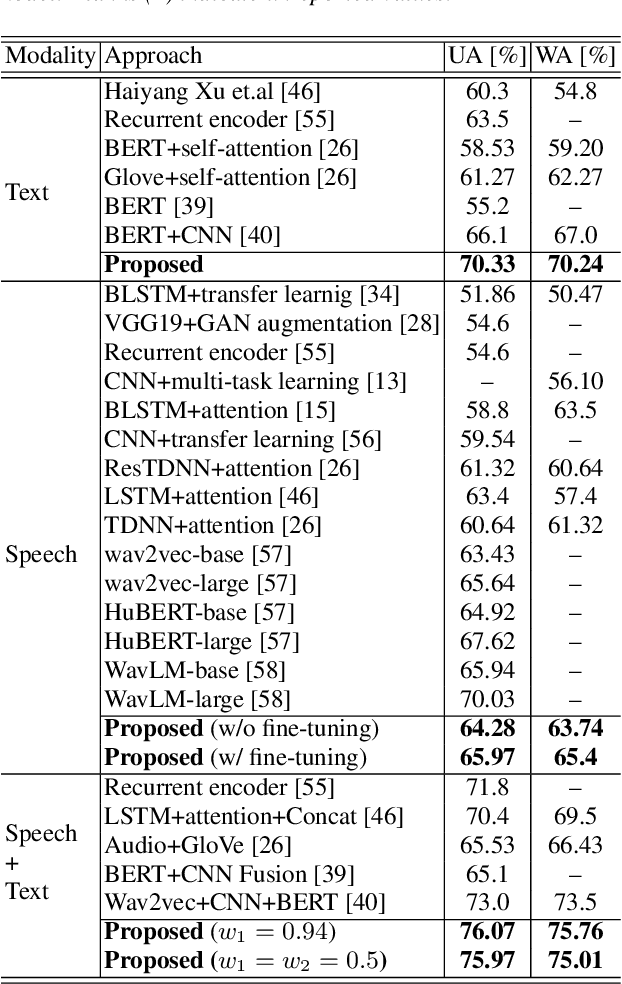
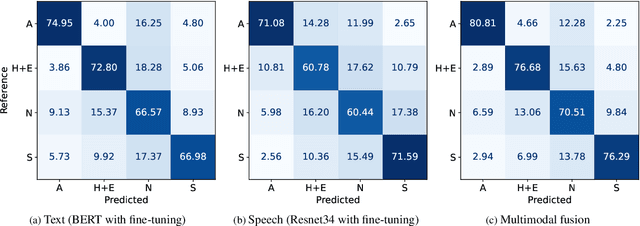
Automatic emotion recognition plays a key role in computer-human interaction as it has the potential to enrich the next-generation artificial intelligence with emotional intelligence. It finds applications in customer and/or representative behavior analysis in call centers, gaming, personal assistants, and social robots, to mention a few. Therefore, there has been an increasing demand to develop robust automatic methods to analyze and recognize the various emotions. In this paper, we propose a neural network-based emotion recognition framework that uses a late fusion of transfer-learned and fine-tuned models from speech and text modalities. More specifically, we i) adapt a residual network (ResNet) based model trained on a large-scale speaker recognition task using transfer learning along with a spectrogram augmentation approach to recognize emotions from speech, and ii) use a fine-tuned bidirectional encoder representations from transformers (BERT) based model to represent and recognize emotions from the text. The proposed system then combines the ResNet and BERT-based model scores using a late fusion strategy to further improve the emotion recognition performance. The proposed multimodal solution addresses the data scarcity limitation in emotion recognition using transfer learning, data augmentation, and fine-tuning, thereby improving the generalization performance of the emotion recognition models. We evaluate the effectiveness of our proposed multimodal approach on the interactive emotional dyadic motion capture (IEMOCAP) dataset. Experimental results indicate that both audio and text-based models improve the emotion recognition performance and that the proposed multimodal solution achieves state-of-the-art results on the IEMOCAP benchmark.
Improved Speech Emotion Recognition using Transfer Learning and Spectrogram Augmentation
Aug 16, 2021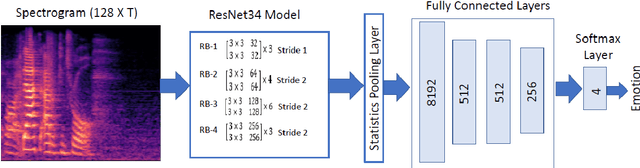
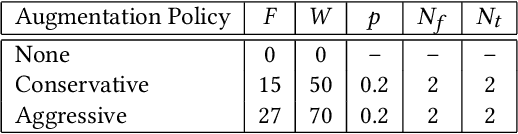
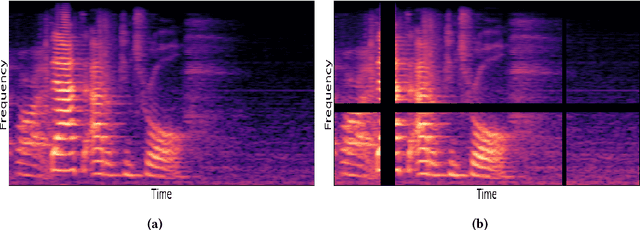
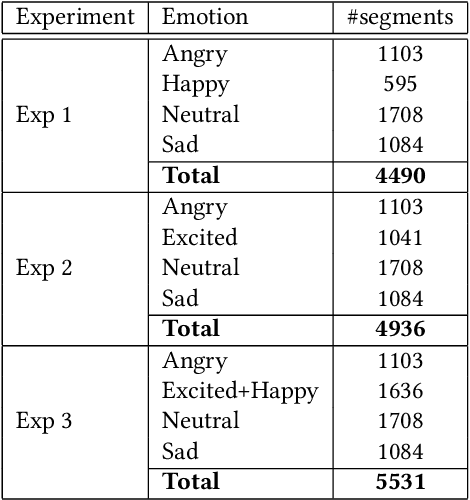
Automatic speech emotion recognition (SER) is a challenging task that plays a crucial role in natural human-computer interaction. One of the main challenges in SER is data scarcity, i.e., insufficient amounts of carefully labeled data to build and fully explore complex deep learning models for emotion classification. This paper aims to address this challenge using a transfer learning strategy combined with spectrogram augmentation. Specifically, we propose a transfer learning approach that leverages a pre-trained residual network (ResNet) model including a statistics pooling layer from speaker recognition trained using large amounts of speaker-labeled data. The statistics pooling layer enables the model to efficiently process variable-length input, thereby eliminating the need for sequence truncation which is commonly used in SER systems. In addition, we adopt a spectrogram augmentation technique to generate additional training data samples by applying random time-frequency masks to log-mel spectrograms to mitigate overfitting and improve the generalization of emotion recognition models. We evaluate the effectiveness of our proposed approach on the interactive emotional dyadic motion capture (IEMOCAP) dataset. Experimental results indicate that the transfer learning and spectrogram augmentation approaches improve the SER performance, and when combined achieve state-of-the-art results.
Multi-Window Data Augmentation Approach for Speech Emotion Recognition
Oct 28, 2020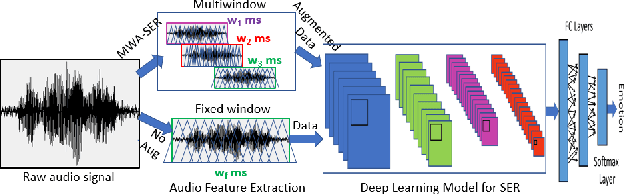
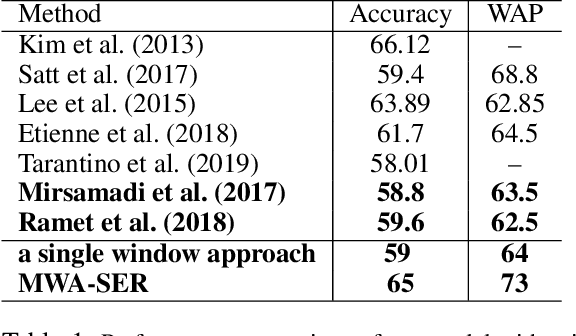
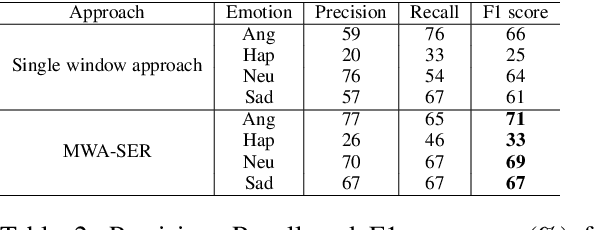
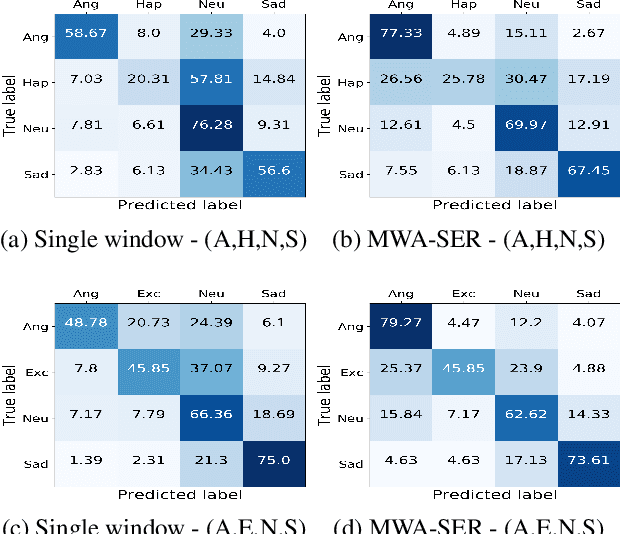
We present a novel, Multi-Window Data Augmentation (MWA-SER) approach for speech emotion recognition. MWA-SER is a unimodal approach that focuses on two key concepts; designing the speech augmentation method to generate additional data samples and building the deep learning models to recognize the underlying emotion of an audio signal. The multi-window augmentation method extracts more audio features from the speech signal by employing multiple window sizes in the audio feature extraction process. We show that our proposed augmentation method, combined with a deep learning model, improves the speech emotion recognition performance. We evaluate the performance of our MWA-SER approach on the IEMOCAP corpus and show that our proposed method achieves state-of-the-art results. Furthermore, the proposed system demonstrated 70% and 88% accuracy while recognizing the emotions for the SAVEE and RAVDESS datasets, respectively.