 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLineConGraphs: Line Conversation Graphs for Effective Emotion Recognition using Graph Neural Networks
Dec 04, 2023Emotion Recognition in Conversations (ERC) is a critical aspect of affective computing, and it has many practical applications in healthcare, education, chatbots, and social media platforms. Earlier approaches for ERC analysis involved modeling both speaker and long-term contextual information using graph neural network architectures. However, it is ideal to deploy speaker-independent models for real-world applications. Additionally, long context windows can potentially create confusion in recognizing the emotion of an utterance in a conversation. To overcome these limitations, we propose novel line conversation graph convolutional network (LineConGCN) and graph attention (LineConGAT) models for ERC analysis. These models are speaker-independent and built using a graph construction strategy for conversations -- line conversation graphs (LineConGraphs). The conversational context in LineConGraphs is short-term -- limited to one previous and future utterance, and speaker information is not part of the graph. We evaluate the performance of our proposed models on two benchmark datasets, IEMOCAP and MELD, and show that our LineConGAT model outperforms the state-of-the-art methods with an F1-score of 64.58% and 76.50%. Moreover, we demonstrate that embedding sentiment shift information into line conversation graphs further enhances the ERC performance in the case of GCN models.
Exact and Approximate Hierarchical Clustering Using A*
Apr 14, 2021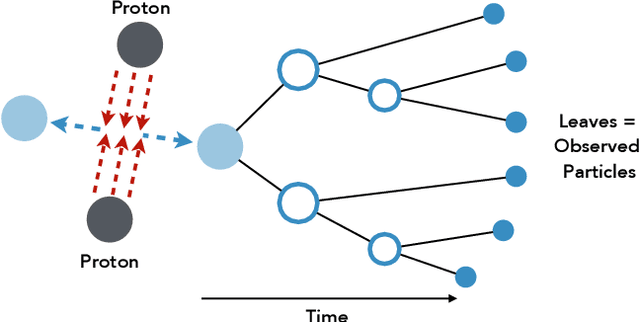
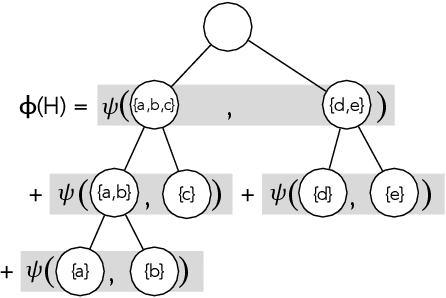
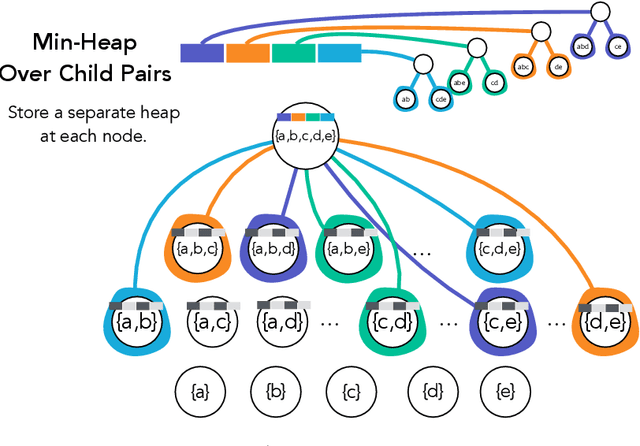
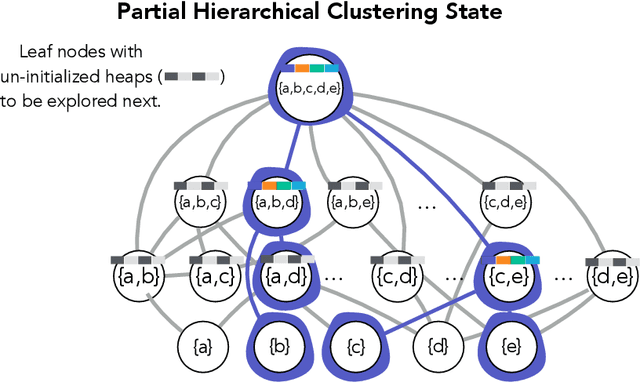
Hierarchical clustering is a critical task in numerous domains. Many approaches are based on heuristics and the properties of the resulting clusterings are studied post hoc. However, in several applications, there is a natural cost function that can be used to characterize the quality of the clustering. In those cases, hierarchical clustering can be seen as a combinatorial optimization problem. To that end, we introduce a new approach based on A* search. We overcome the prohibitively large search space by combining A* with a novel \emph{trellis} data structure. This combination results in an exact algorithm that scales beyond previous state of the art, from a search space with $10^{12}$ trees to $10^{15}$ trees, and an approximate algorithm that improves over baselines, even in enormous search spaces that contain more than $10^{1000}$ trees. We empirically demonstrate that our method achieves substantially higher quality results than baselines for a particle physics use case and other clustering benchmarks. We describe how our method provides significantly improved theoretical bounds on the time and space complexity of A* for clustering.
Compact Representation of Uncertainty in Hierarchical Clustering
Feb 26, 2020



Hierarchical clustering is a fundamental task often used to discover meaningful structures in data, such as phylogenetic trees, taxonomies of concepts, subtypes of cancer, and cascades of particle decays in particle physics. When multiple hierarchical clusterings of the data are possible, it is useful to represent uncertainty in the clustering through various probabilistic quantities. Existing approaches represent uncertainty for a range of models; however, they only provide approximate inference. This paper presents dynamic-programming algorithms and proofs for exact inference in hierarchical clustering. We are able to compute the partition function, MAP hierarchical clustering, and marginal probabilities of sub-hierarchies and clusters. Our method supports a wide range of hierarchical models and only requires a cluster compatibility function. Rather than scaling with the number of hierarchical clusterings of $n$ elements ($\omega(n n! / 2^{n-1})$), our approach runs in time and space proportional to the significantly smaller powerset of $n$. Despite still being large, these algorithms enable exact inference in small-data applications and are also interesting from a theoretical perspective. We demonstrate the utility of our method and compare its performance with respect to existing approximate methods.