 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Emotion Recognition using Transfer Learning from Speaker Recognition and BERT-based models
Paper and Code
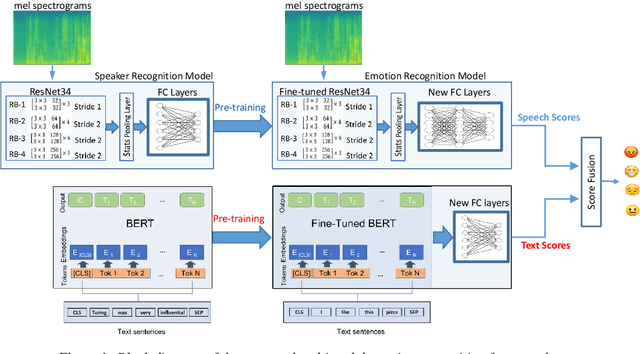
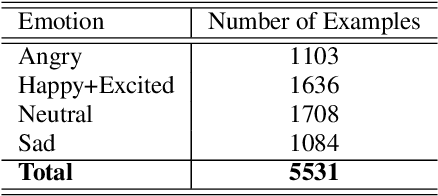
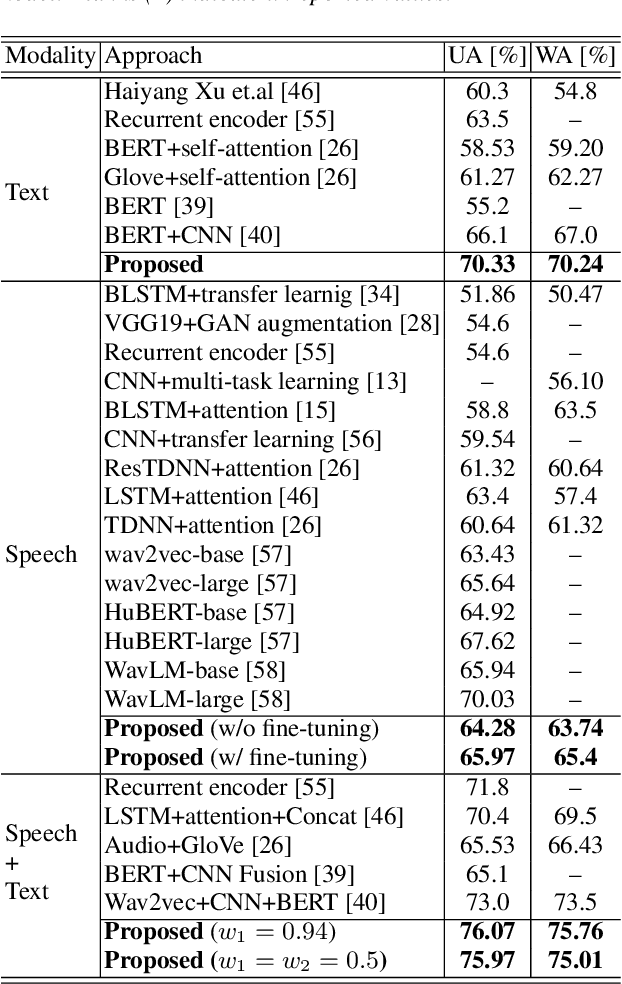
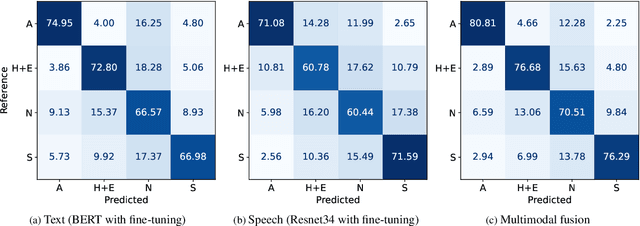
Automatic emotion recognition plays a key role in computer-human interaction as it has the potential to enrich the next-generation artificial intelligence with emotional intelligence. It finds applications in customer and/or representative behavior analysis in call centers, gaming, personal assistants, and social robots, to mention a few. Therefore, there has been an increasing demand to develop robust automatic methods to analyze and recognize the various emotions. In this paper, we propose a neural network-based emotion recognition framework that uses a late fusion of transfer-learned and fine-tuned models from speech and text modalities. More specifically, we i) adapt a residual network (ResNet) based model trained on a large-scale speaker recognition task using transfer learning along with a spectrogram augmentation approach to recognize emotions from speech, and ii) use a fine-tuned bidirectional encoder representations from transformers (BERT) based model to represent and recognize emotions from the text. The proposed system then combines the ResNet and BERT-based model scores using a late fusion strategy to further improve the emotion recognition performance. The proposed multimodal solution addresses the data scarcity limitation in emotion recognition using transfer learning, data augmentation, and fine-tuning, thereby improving the generalization performance of the emotion recognition models. We evaluate the effectiveness of our proposed multimodal approach on the interactive emotional dyadic motion capture (IEMOCAP) dataset. Experimental results indicate that both audio and text-based models improve the emotion recognition performance and that the proposed multimodal solution achieves state-of-the-art results on the IEMOCAP benchmark.