 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Meta: Leveraging Game Design Parameters for Patch-Agnostic Esport Analytics
Jun 05, 2023
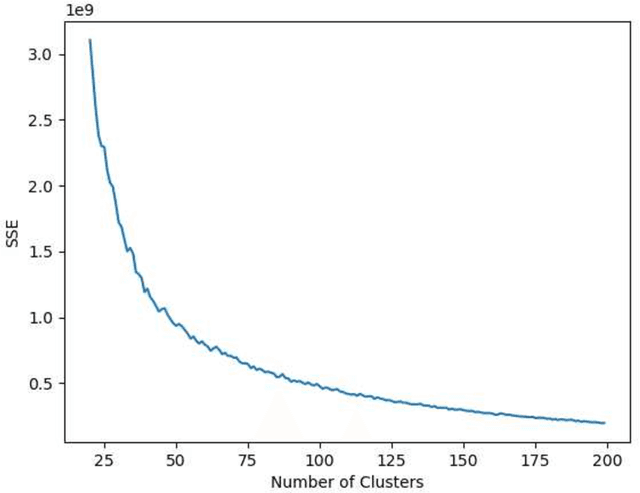
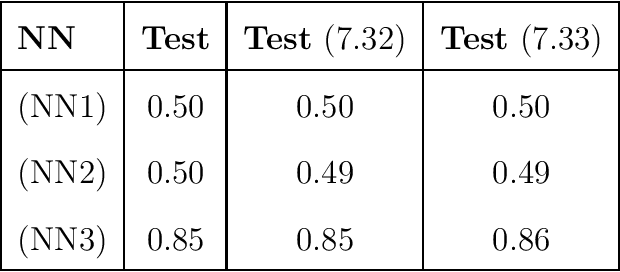
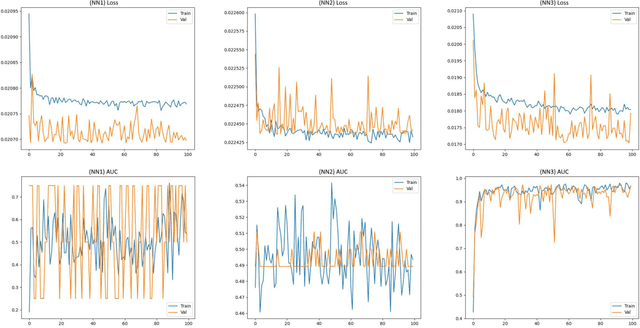
Esport games comprise a sizeable fraction of the global games market, and is the fastest growing segment in games. This has given rise to the domain of esports analytics, which uses telemetry data from games to inform players, coaches, broadcasters and other stakeholders. Compared to traditional sports, esport titles change rapidly, in terms of mechanics as well as rules. Due to these frequent changes to the parameters of the game, esport analytics models can have a short life-spam, a problem which is largely ignored within the literature. This paper extracts information from game design (i.e. patch notes) and utilises clustering techniques to propose a new form of character representation. As a case study, a neural network model is trained to predict the number of kills in a Dota 2 match utilising this novel character representation technique. The performance of this model is then evaluated against two distinct baselines, including conventional techniques. Not only did the model significantly outperform the baselines in terms of accuracy (85% AUC), but the model also maintains the accuracy in two newer iterations of the game that introduced one new character and a brand new character type. These changes introduced to the design of the game would typically break conventional techniques that are commonly used within the literature. Therefore, the proposed methodology for representing characters can increase the life-spam of machine learning models as well as contribute to a higher performance when compared to traditional techniques typically employed within the literature.
A Conformer-based Waveform-domain Neural Acoustic Echo Canceller Optimized for ASR Accuracy
May 06, 2022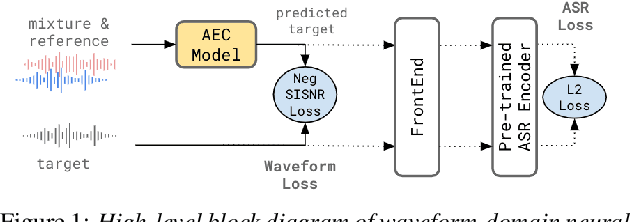
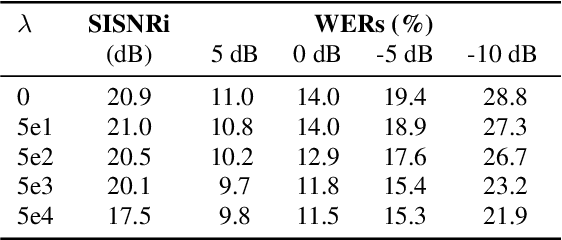
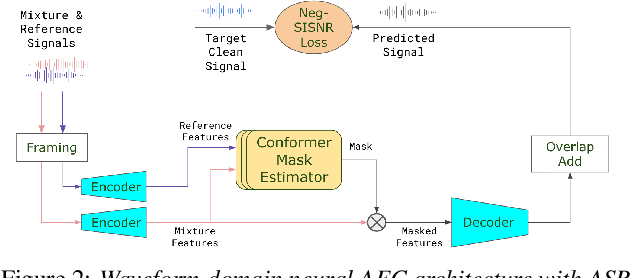
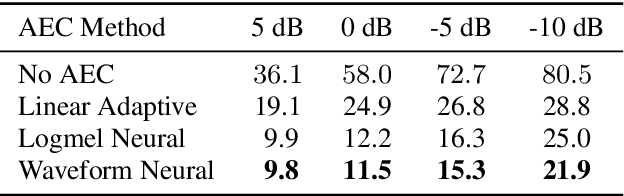
Acoustic Echo Cancellation (AEC) is essential for accurate recognition of queries spoken to a smart speaker that is playing out audio. Previous work has shown that a neural AEC model operating on log-mel spectral features (denoted "logmel" hereafter) can greatly improve Automatic Speech Recognition (ASR) accuracy when optimized with an auxiliary loss utilizing a pre-trained ASR model encoder. In this paper, we develop a conformer-based waveform-domain neural AEC model inspired by the "TasNet" architecture. The model is trained by jointly optimizing Negative Scale-Invariant SNR (SISNR) and ASR losses on a large speech dataset. On a realistic rerecorded test set, we find that cascading a linear adaptive AEC and a waveform-domain neural AEC is very effective, giving 56-59% word error rate (WER) reduction over the linear AEC alone. On this test set, the 1.6M parameter waveform-domain neural AEC also improves over a larger 6.5M parameter logmel-domain neural AEC model by 20-29% in easy to moderate conditions. By operating on smaller frames, the waveform neural model is able to perform better at smaller sizes and is better suited for applications where memory is limited.
Mask scalar prediction for improving robust automatic speech recognition
Apr 26, 2022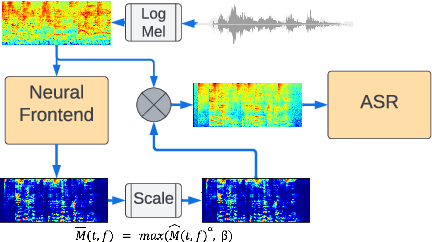
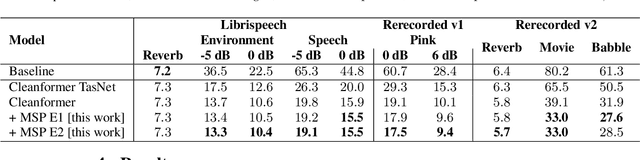
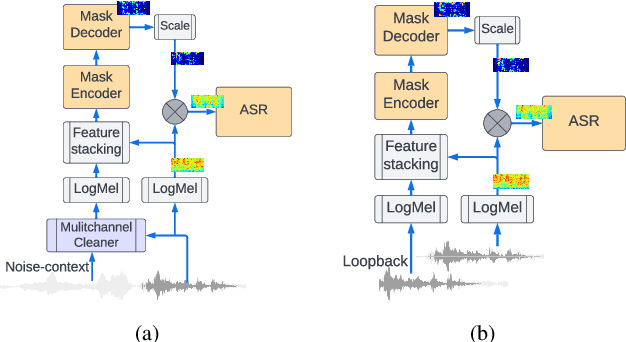
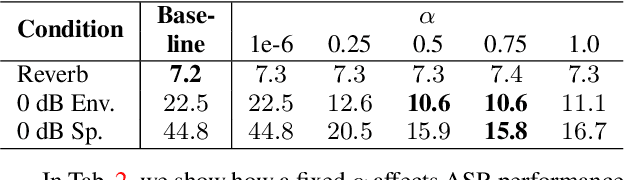
Using neural network based acoustic frontends for improving robustness of streaming automatic speech recognition (ASR) systems is challenging because of the causality constraints and the resulting distortion that the frontend processing introduces in speech. Time-frequency masking based approaches have been shown to work well, but they need additional hyper-parameters to scale the mask to limit speech distortion. Such mask scalars are typically hand-tuned and chosen conservatively. In this work, we present a technique to predict mask scalars using an ASR-based loss in an end-to-end fashion, with minimal increase in the overall model size and complexity. We evaluate the approach on two robust ASR tasks: multichannel enhancement in the presence of speech and non-speech noise, and acoustic echo cancellation (AEC). Results show that the presented algorithm consistently improves word error rate (WER) without the need for any additional tuning over strong baselines that use hand-tuned hyper-parameters: up to 16% for multichannel enhancement in noisy conditions, and up to 7% for AEC.
A Conformer-based ASR Frontend for Joint Acoustic Echo Cancellation, Speech Enhancement and Speech Separation
Nov 18, 2021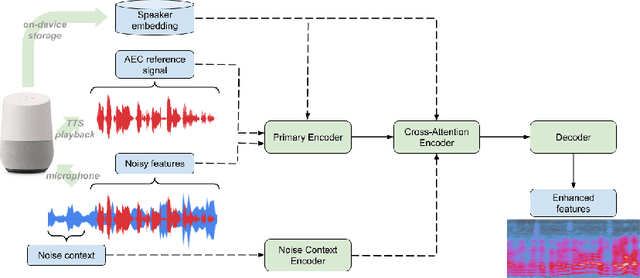
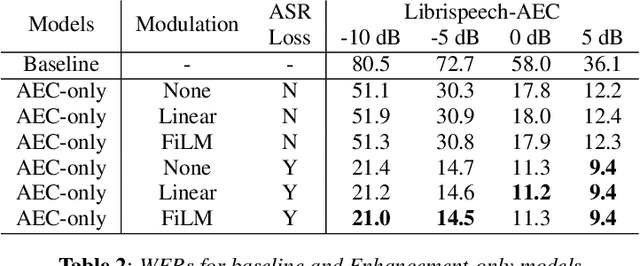
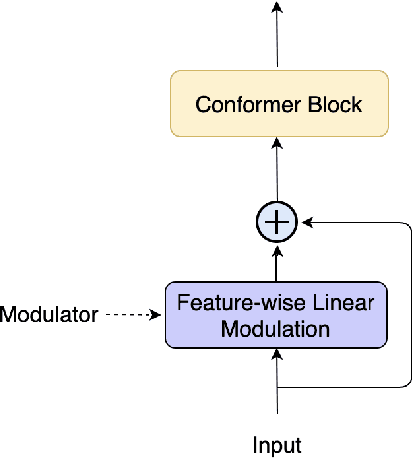
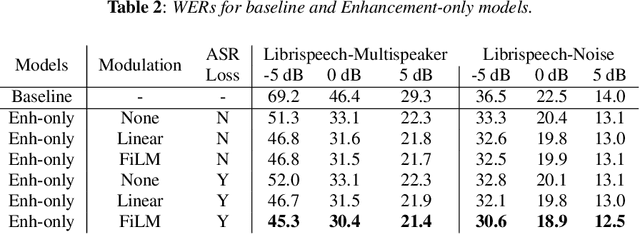
We present a frontend for improving robustness of automatic speech recognition (ASR), that jointly implements three modules within a single model: acoustic echo cancellation, speech enhancement, and speech separation. This is achieved by using a contextual enhancement neural network that can optionally make use of different types of side inputs: (1) a reference signal of the playback audio, which is necessary for echo cancellation; (2) a noise context, which is useful for speech enhancement; and (3) an embedding vector representing the voice characteristic of the target speaker of interest, which is not only critical in speech separation, but also helpful for echo cancellation and speech enhancement. We present detailed evaluations to show that the joint model performs almost as well as the task-specific models, and significantly reduces word error rate in noisy conditions even when using a large-scale state-of-the-art ASR model. Compared to the noisy baseline, the joint model reduces the word error rate in low signal-to-noise ratio conditions by at least 71% on our echo cancellation dataset, 10% on our noisy dataset, and 26% on our multi-speaker dataset. Compared to task-specific models, the joint model performs within 10% on our echo cancellation dataset, 2% on the noisy dataset, and 3% on the multi-speaker dataset.