 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalizing Keyword Spotting with Speaker Information
Nov 06, 2023



Keyword spotting systems often struggle to generalize to a diverse population with various accents and age groups. To address this challenge, we propose a novel approach that integrates speaker information into keyword spotting using Feature-wise Linear Modulation (FiLM), a recent method for learning from multiple sources of information. We explore both Text-Dependent and Text-Independent speaker recognition systems to extract speaker information, and we experiment on extracting this information from both the input audio and pre-enrolled user audio. We evaluate our systems on a diverse dataset and achieve a substantial improvement in keyword detection accuracy, particularly among underrepresented speaker groups. Moreover, our proposed approach only requires a small 1% increase in the number of parameters, with a minimum impact on latency and computational cost, which makes it a practical solution for real-world applications.
Locale Encoding For Scalable Multilingual Keyword Spotting Models
Feb 25, 2023



A Multilingual Keyword Spotting (KWS) system detects spokenkeywords over multiple locales. Conventional monolingual KWSapproaches do not scale well to multilingual scenarios because ofhigh development/maintenance costs and lack of resource sharing.To overcome this limit, we propose two locale-conditioned universalmodels with locale feature concatenation and feature-wise linearmodulation (FiLM). We compare these models with two baselinemethods: locale-specific monolingual KWS, and a single universalmodel trained over all data. Experiments over 10 localized languagedatasets show that locale-conditioned models substantially improveaccuracy over baseline methods across all locales in different noiseconditions.FiLMperformed the best, improving on average FRRby 61% (relative) compared to monolingual KWS models of similarsizes.
A Conformer-based Waveform-domain Neural Acoustic Echo Canceller Optimized for ASR Accuracy
May 06, 2022
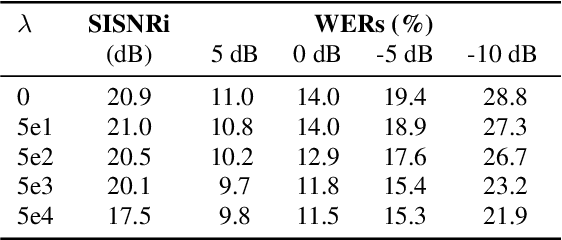
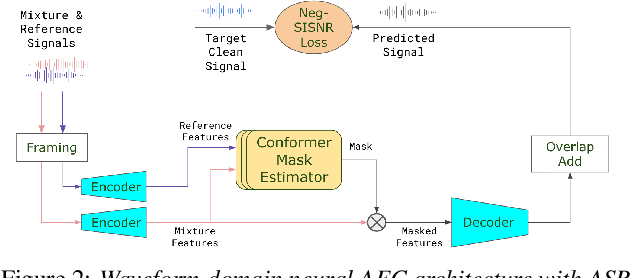
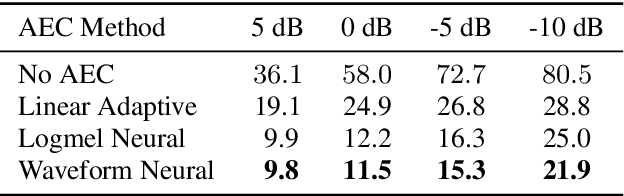
Acoustic Echo Cancellation (AEC) is essential for accurate recognition of queries spoken to a smart speaker that is playing out audio. Previous work has shown that a neural AEC model operating on log-mel spectral features (denoted "logmel" hereafter) can greatly improve Automatic Speech Recognition (ASR) accuracy when optimized with an auxiliary loss utilizing a pre-trained ASR model encoder. In this paper, we develop a conformer-based waveform-domain neural AEC model inspired by the "TasNet" architecture. The model is trained by jointly optimizing Negative Scale-Invariant SNR (SISNR) and ASR losses on a large speech dataset. On a realistic rerecorded test set, we find that cascading a linear adaptive AEC and a waveform-domain neural AEC is very effective, giving 56-59% word error rate (WER) reduction over the linear AEC alone. On this test set, the 1.6M parameter waveform-domain neural AEC also improves over a larger 6.5M parameter logmel-domain neural AEC model by 20-29% in easy to moderate conditions. By operating on smaller frames, the waveform neural model is able to perform better at smaller sizes and is better suited for applications where memory is limited.
Production federated keyword spotting via distillation, filtering, and joint federated-centralized training
Apr 11, 2022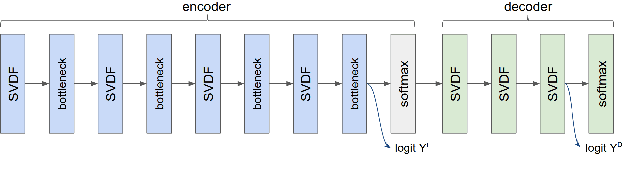
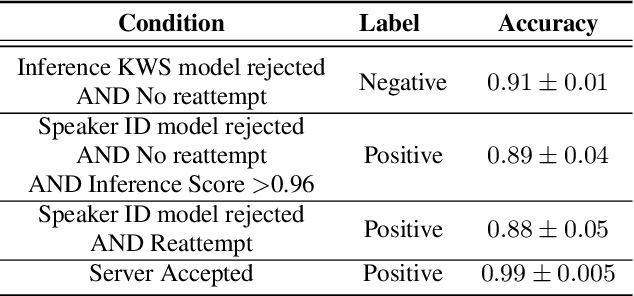
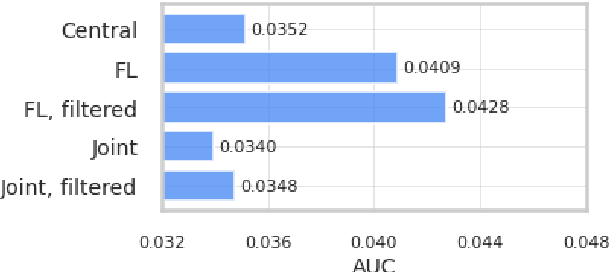

We trained a keyword spotting model using federated learning on real user devices and observed significant improvements when the model was deployed for inference on phones. To compensate for data domains that are missing from on-device training caches, we employed joint federated-centralized training. And to learn in the absence of curated labels on-device, we formulated a confidence filtering strategy based on user-feedback signals for federated distillation. These techniques created models that significantly improved quality metrics in offline evaluations and user-experience metrics in live A/B experiments.
A Conformer-based ASR Frontend for Joint Acoustic Echo Cancellation, Speech Enhancement and Speech Separation
Nov 18, 2021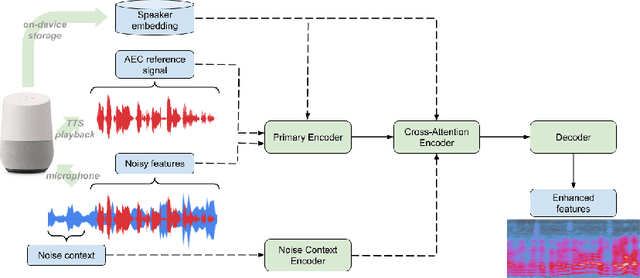
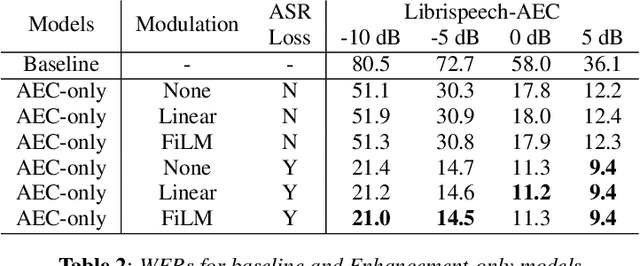
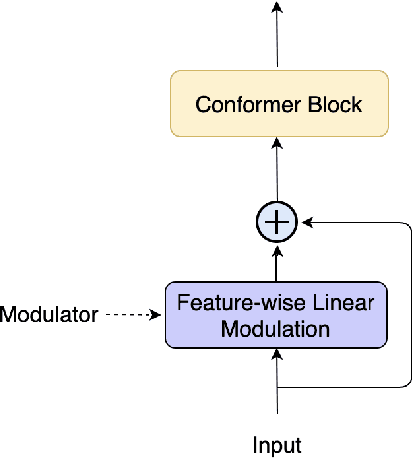
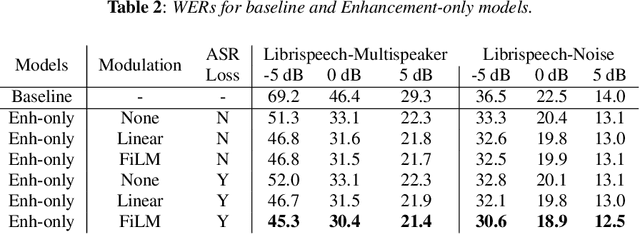
We present a frontend for improving robustness of automatic speech recognition (ASR), that jointly implements three modules within a single model: acoustic echo cancellation, speech enhancement, and speech separation. This is achieved by using a contextual enhancement neural network that can optionally make use of different types of side inputs: (1) a reference signal of the playback audio, which is necessary for echo cancellation; (2) a noise context, which is useful for speech enhancement; and (3) an embedding vector representing the voice characteristic of the target speaker of interest, which is not only critical in speech separation, but also helpful for echo cancellation and speech enhancement. We present detailed evaluations to show that the joint model performs almost as well as the task-specific models, and significantly reduces word error rate in noisy conditions even when using a large-scale state-of-the-art ASR model. Compared to the noisy baseline, the joint model reduces the word error rate in low signal-to-noise ratio conditions by at least 71% on our echo cancellation dataset, 10% on our noisy dataset, and 26% on our multi-speaker dataset. Compared to task-specific models, the joint model performs within 10% on our echo cancellation dataset, 2% on the noisy dataset, and 3% on the multi-speaker dataset.
A Neural Acoustic Echo Canceller Optimized Using An Automatic Speech Recognizer And Large Scale Synthetic Data
Jun 01, 2021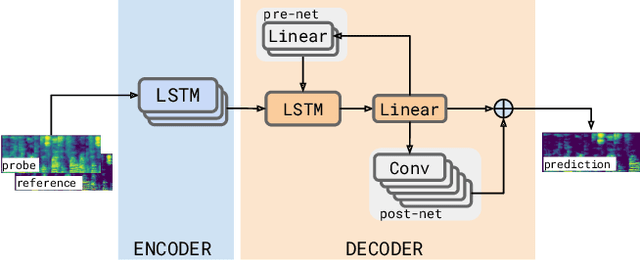
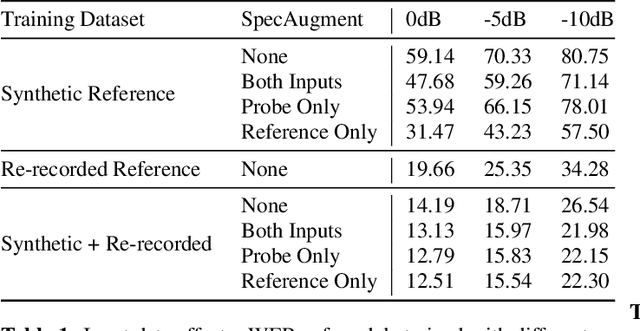

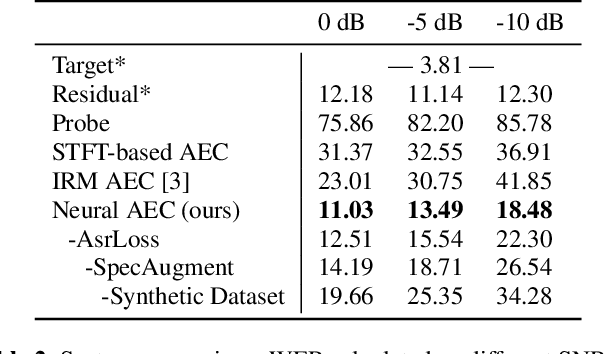
We consider the problem of recognizing speech utterances spoken to a device which is generating a known sound waveform; for example, recognizing queries issued to a digital assistant which is generating responses to previous user inputs. Previous work has proposed building acoustic echo cancellation (AEC) models for this task that optimize speech enhancement metrics using both neural network as well as signal processing approaches. Since our goal is to recognize the input speech, we consider enhancements which improve word error rates (WERs) when the predicted speech signal is passed to an automatic speech recognition (ASR) model. First, we augment the loss function with a term that produces outputs useful to a pre-trained ASR model and show that this augmented loss function improves WER metrics. Second, we demonstrate that augmenting our training dataset of real world examples with a large synthetic dataset improves performance. Crucially, applying SpecAugment style masks to the reference channel during training aids the model in adapting from synthetic to real domains. In experimental evaluations, we find the proposed approaches improve performance, on average, by 57% over a signal processing baseline and 45% over the neural AEC model without the proposed changes.