 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Large Protein Language Models in Constrained Evaluation Scenarios within the FLIP Benchmark
Jan 30, 2025



In this study, we expand upon the FLIP benchmark-designed for evaluating protein fitness prediction models in small, specialized prediction tasks-by assessing the performance of state-of-the-art large protein language models, including ESM-2 and SaProt on the FLIP dataset. Unlike larger, more diverse benchmarks such as ProteinGym, which cover a broad spectrum of tasks, FLIP focuses on constrained settings where data availability is limited. This makes it an ideal framework to evaluate model performance in scenarios with scarce task-specific data. We investigate whether recent advances in protein language models lead to significant improvements in such settings. Our findings provide valuable insights into the performance of large-scale models in specialized protein prediction tasks.
Leveraging Speaker Embeddings in End-to-End Neural Diarization for Two-Speaker Scenarios
Jul 01, 2024End-to-end neural speaker diarization systems are able to address the speaker diarization task while effectively handling speech overlap. This work explores the incorporation of speaker information embeddings into the end-to-end systems to enhance the speaker discriminative capabilities, while maintaining their overlap handling strengths. To achieve this, we propose several methods for incorporating these embeddings along the acoustic features. Furthermore, we delve into an analysis of the correct handling of silence frames, the window length for extracting speaker embeddings and the transformer encoder size. The effectiveness of our proposed approach is thoroughly evaluated on the CallHome dataset for the two-speaker diarization task, with results that demonstrate a significant reduction in diarization error rates achieving a relative improvement of a 10.78% compared to the baseline end-to-end model.
Personalizing Keyword Spotting with Speaker Information
Nov 06, 2023



Keyword spotting systems often struggle to generalize to a diverse population with various accents and age groups. To address this challenge, we propose a novel approach that integrates speaker information into keyword spotting using Feature-wise Linear Modulation (FiLM), a recent method for learning from multiple sources of information. We explore both Text-Dependent and Text-Independent speaker recognition systems to extract speaker information, and we experiment on extracting this information from both the input audio and pre-enrolled user audio. We evaluate our systems on a diverse dataset and achieve a substantial improvement in keyword detection accuracy, particularly among underrepresented speaker groups. Moreover, our proposed approach only requires a small 1% increase in the number of parameters, with a minimum impact on latency and computational cost, which makes it a practical solution for real-world applications.
Multi-Speaker and Wide-Band Simulated Conversations as Training Data for End-to-End Neural Diarization
Nov 12, 2022End-to-end diarization presents an attractive alternative to standard cascaded diarization systems because a single system can handle all aspects of the task at once. Many flavors of end-to-end models have been proposed but all of them require (so far non-existing) large amounts of annotated data for training. The compromise solution consists in generating synthetic data and the recently proposed simulated conversations (SC) have shown remarkable improvements over the original simulated mixtures (SM). In this work, we create SC with multiple speakers per conversation and show that they allow for substantially better performance than SM, also reducing the dependence on a fine-tuning stage. We also create SC with wide-band public audio sources and present an analysis on several evaluation sets. Together with this publication, we release the recipes for generating such data and models trained on public sets as well as the implementation to efficiently handle multiple speakers per conversation and an auxiliary voice activity detection loss.
From Simulated Mixtures to Simulated Conversations as Training Data for End-to-End Neural Diarization
Apr 02, 2022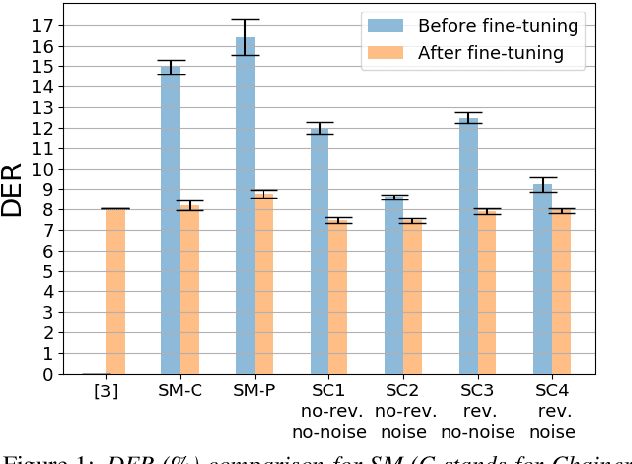
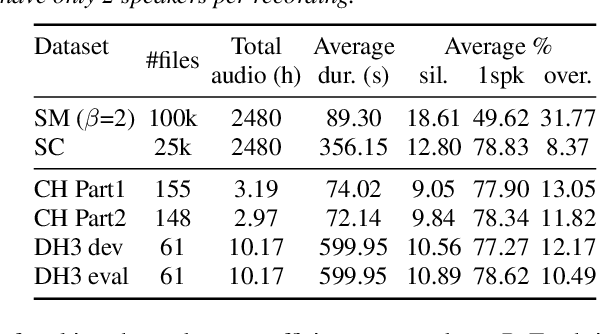
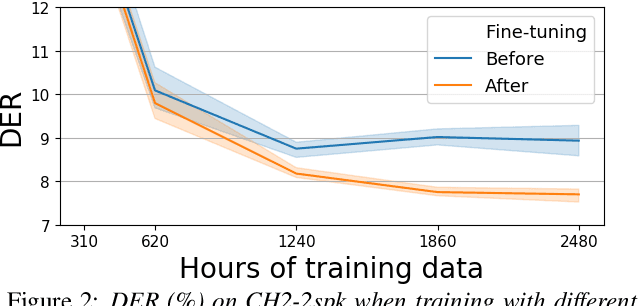
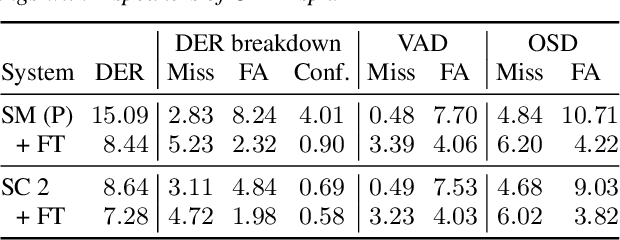
End-to-end neural diarization (EEND) is nowadays one of the most prominent research topics in speaker diarization. EEND presents an attractive alternative to standard cascaded diarization systems since a single system is trained at once to deal with the whole diarization problem. Several EEND variants and approaches are being proposed, however, all these models require large amounts of annotated data for training but available annotated data are scarce. Thus, EEND works have used mostly simulated mixtures for training. However, simulated mixtures do not resemble real conversations in many aspects. In this work we present an alternative method for creating synthetic conversations that resemble real ones by using statistics about distributions of pauses and overlaps estimated on genuine conversations. Furthermore, we analyze the effect of the source of the statistics, different augmentations and amounts of data. We demonstrate that our approach performs substantially better than the original one, while reducing the dependence on the fine-tuning stage. Experiments are carried out on 2-speaker telephone conversations of Callhome and DIHARD 3. Together with this publication, we release our implementations of EEND and the method for creating simulated conversations.
Bayesian Strategies for Likelihood Ratio Computation in Forensic Voice Comparison with Automatic Systems
Sep 18, 2019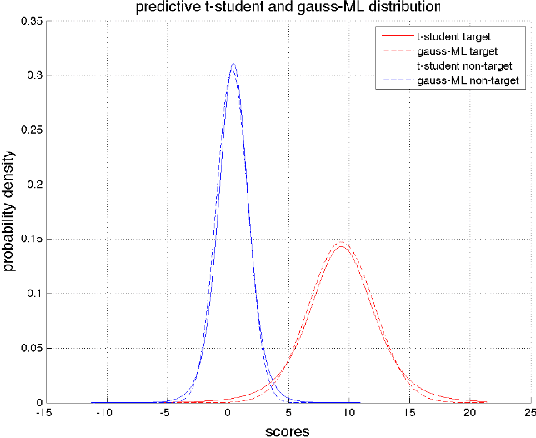
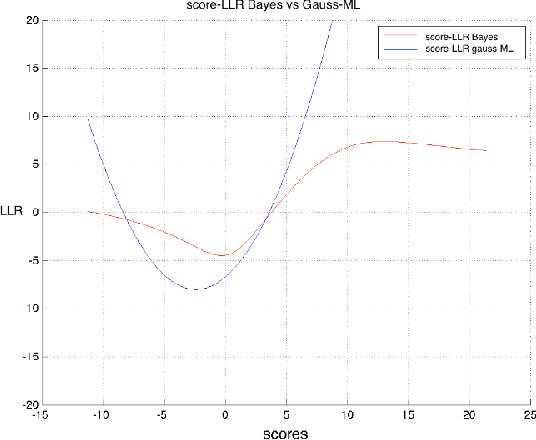
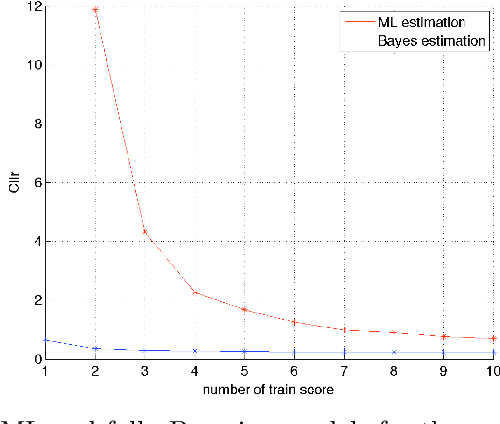
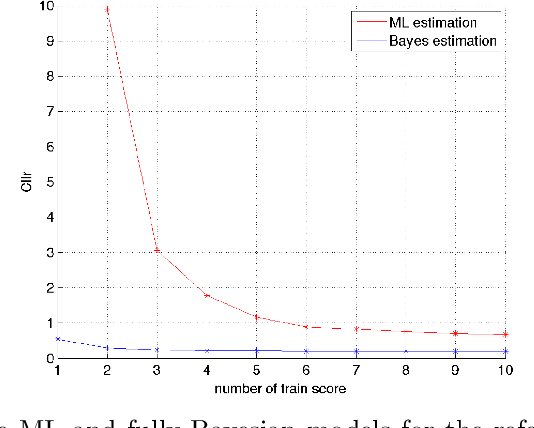
This paper explores several strategies for Forensic Voice Comparison (FVC), aimed at improving the performance of the LRs when using generative Gaussian score-to-LR models. First, different anchoring strategies are proposed, with the objective of adapting the LR computation process to the case at hand, always respecting the propositions defined for the particular case. Second, a fully-Bayesian Gaussian model is used to tackle the sparsity in the training scores that is often present when the proposed anchoring strategies are used. Experiments are performed using the 2014 i-Vector challenge set-up, which presents high variability in a telephone speech context. The results show that the proposed fully-Bayesian model clearly outperforms a more common Maximum-Likelihood approach, leading to high robustness when the scores to train the model become sparse.