 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tune Before Structured Pruning: Towards Compact and Accurate Self-Supervised Models for Speaker Diarization
May 30, 2025Self-supervised learning (SSL) models like WavLM can be effectively utilized when building speaker diarization systems but are often large and slow, limiting their use in resource constrained scenarios. Previous studies have explored compression techniques, but usually for the price of degraded performance at high pruning ratios. In this work, we propose to compress SSL models through structured pruning by introducing knowledge distillation. Different from the existing works, we emphasize the importance of fine-tuning SSL models before pruning. Experiments on far-field single-channel AMI, AISHELL-4, and AliMeeting datasets show that our method can remove redundant parameters of WavLM Base+ and WavLM Large by up to 80% without any performance degradation. After pruning, the inference speeds on a single GPU for the Base+ and Large models are 4.0 and 2.6 times faster, respectively. Our source code is publicly available.
Joint Training of Speaker Embedding Extractor, Speech and Overlap Detection for Diarization
Nov 04, 2024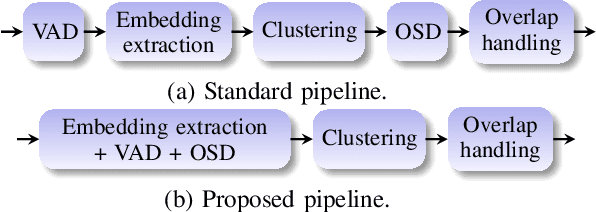
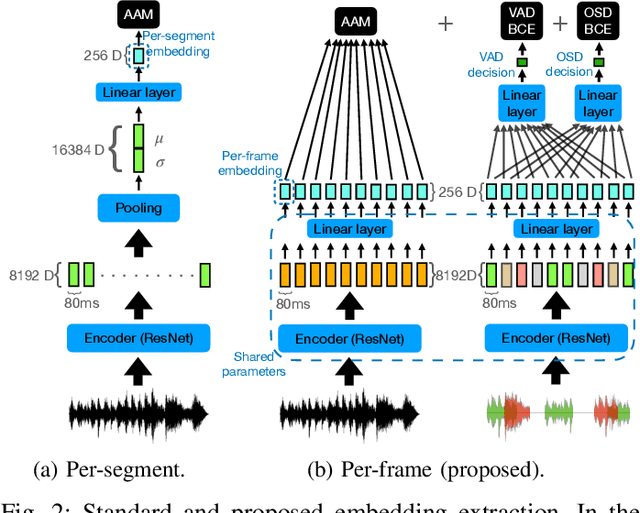
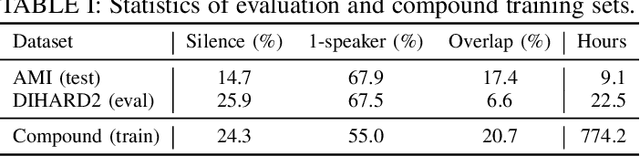
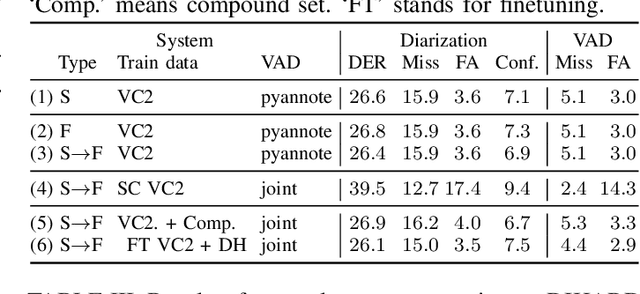
In spite of the popularity of end-to-end diarization systems nowadays, modular systems comprised of voice activity detection (VAD), speaker embedding extraction plus clustering, and overlapped speech detection (OSD) plus handling still attain competitive performance in many conditions. However, one of the main drawbacks of modular systems is the need to run (and train) different modules independently. In this work, we propose an approach to jointly train a model to produce speaker embeddings, VAD and OSD simultaneously and reach competitive performance at a fraction of the inference time of a standard approach. Furthermore, the joint inference leads to a simplified overall pipeline which brings us one step closer to a unified clustering-based method that can be trained end-to-end towards a diarization-specific objective.
Leveraging Self-Supervised Learning for Speaker Diarization
Sep 14, 2024



End-to-end neural diarization has evolved considerably over the past few years, but data scarcity is still a major obstacle for further improvements. Self-supervised learning methods such as WavLM have shown promising performance on several downstream tasks, but their application on speaker diarization is somehow limited. In this work, we explore using WavLM to alleviate the problem of data scarcity for neural diarization training. We use the same pipeline as Pyannote and improve the local end-to-end neural diarization with WavLM and Conformer. Experiments on far-field AMI, AISHELL-4, and AliMeeting datasets show that our method substantially outperforms the Pyannote baseline and achieves performance comparable to the state-of-the-art results on AMI and AISHELL-4. In addition, by analyzing the system performance under different data quantity scenarios, we show that WavLM representations are much more robust against data scarcity than filterbank features, enabling less data hungry training strategies. Furthermore, we found that simulated data, usually used to train endto-end diarization models, does not help when using WavLM in our experiments. Additionally, we also evaluate our model on the recent CHiME8 NOTSOFAR-1 task where it achieves better performance than the Pyannote baseline. Our source code is publicly available at https://github.com/BUTSpeechFIT/DiariZen.
Spoof Diarization: "What Spoofed When" in Partially Spoofed Audio
Jun 12, 2024



This paper defines Spoof Diarization as a novel task in the Partial Spoof (PS) scenario. It aims to determine what spoofed when, which includes not only locating spoof regions but also clustering them according to different spoofing methods. As a pioneering study in spoof diarization, we focus on defining the task, establishing evaluation metrics, and proposing a benchmark model, namely the Countermeasure-Condition Clustering (3C) model. Utilizing this model, we first explore how to effectively train countermeasures to support spoof diarization using three labeling schemes. We then utilize spoof localization predictions to enhance the diarization performance. This first study reveals the high complexity of the task, even in restricted scenarios where only a single speaker per audio file and an oracle number of spoofing methods are considered. Our code is available at https://github.com/nii-yamagishilab/PartialSpoof.
Do End-to-End Neural Diarization Attractors Need to Encode Speaker Characteristic Information?
Feb 29, 2024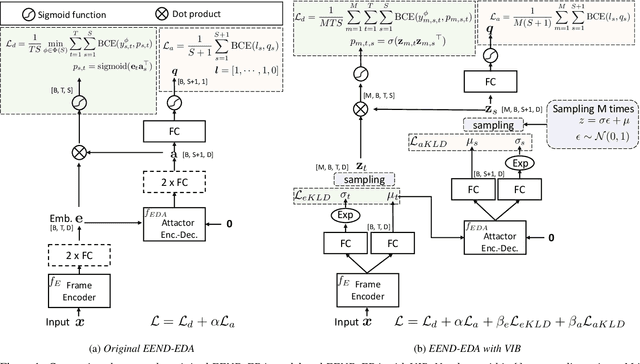

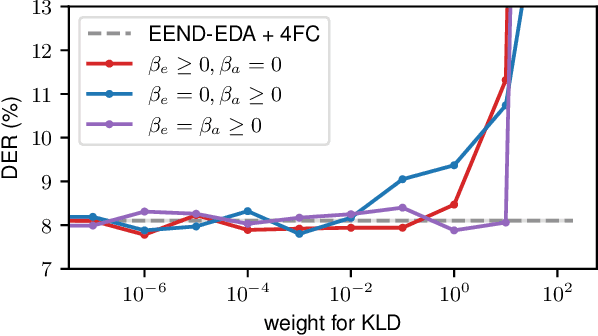

In this paper, we apply the variational information bottleneck approach to end-to-end neural diarization with encoder-decoder attractors (EEND-EDA). This allows us to investigate what information is essential for the model. EEND-EDA utilizes vector representations of the speakers in a conversation - attractors. Our analysis shows that, attractors do not necessarily have to contain speaker characteristic information. On the other hand, giving the attractors more freedom allowing them to encode some extra (possibly speaker-specific) information leads to small but consistent diarization performance improvements. Despite architectural differences in EEND systems, the notion of attractors and frame embeddings is common to most of them and not specific to EEND-EDA. We believe that the main conclusions of this work can apply to other variants of EEND. Thus, we hope this paper will be a valuable contribution to guide the community to make more informed decisions when designing new systems.
DiaPer: End-to-End Neural Diarization with Perceiver-Based Attractors
Dec 22, 2023



Until recently, the field of speaker diarization was dominated by cascaded systems. Due to their limitations, mainly regarding overlapped speech and cumbersome pipelines, end-to-end models have gained great popularity lately. One of the most successful models is end-to-end neural diarization with encoder-decoder based attractors (EEND-EDA). In this work, we replace the EDA module with a Perceiver-based one and show its advantages over EEND-EDA; namely obtaining better performance on the largely studied Callhome dataset, finding the quantity of speakers in a conversation more accurately, and running inference on almost half of the time on long recordings. Furthermore, when exhaustively compared with other methods, our model, DiaPer, reaches remarkable performance with a very lightweight design. Besides, we perform comparisons with other works and a cascaded baseline across more than ten public wide-band datasets. Together with this publication, we release the code of DiaPer as well as models trained on public and free data.
Discriminative Training of VBx Diarization
Oct 04, 2023


Bayesian HMM clustering of x-vector sequences (VBx) has become a widely adopted diarization baseline model in publications and challenges. It uses an HMM to model speaker turns, a generatively trained probabilistic linear discriminant analysis (PLDA) for speaker distribution modeling, and Bayesian inference to estimate the assignment of x-vectors to speakers. This paper presents a new framework for updating the VBx parameters using discriminative training, which directly optimizes a predefined loss. We also propose a new loss that better correlates with the diarization error rate compared to binary cross-entropy $\unicode{x2013}$ the default choice for diarization end-to-end systems. Proof-of-concept results across three datasets (AMI, CALLHOME, and DIHARD II) demonstrate the method's capability of automatically finding hyperparameters, achieving comparable performance to those found by extensive grid search, which typically requires additional hyperparameter behavior knowledge. Moreover, we show that discriminative fine-tuning of PLDA can further improve the model's performance. We release the source code with this publication.
DiaCorrect: Error Correction Back-end For Speaker Diarization
Sep 15, 2023

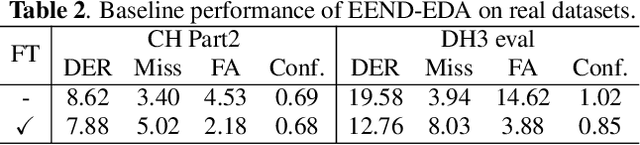

In this work, we propose an error correction framework, named DiaCorrect, to refine the output of a diarization system in a simple yet effective way. This method is inspired by error correction techniques in automatic speech recognition. Our model consists of two parallel convolutional encoders and a transform-based decoder. By exploiting the interactions between the input recording and the initial system's outputs, DiaCorrect can automatically correct the initial speaker activities to minimize the diarization errors. Experiments on 2-speaker telephony data show that the proposed DiaCorrect can effectively improve the initial model's results. Our source code is publicly available at https://github.com/BUTSpeechFIT/diacorrect.
Multi-Stream Extension of Variational Bayesian HMM Clustering (MS-VBx) for Combined End-to-End and Vector Clustering-based Diarization
May 23, 2023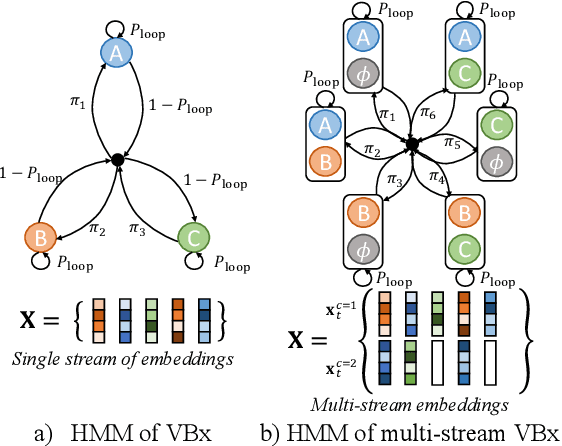
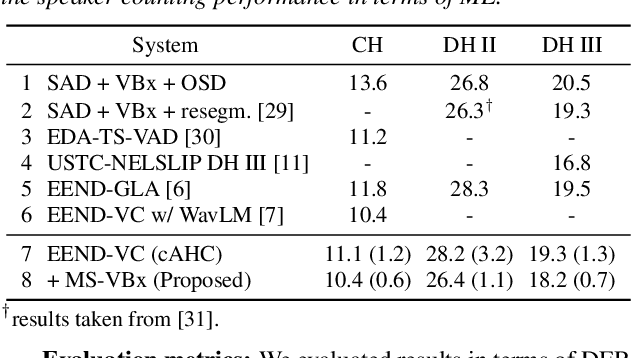
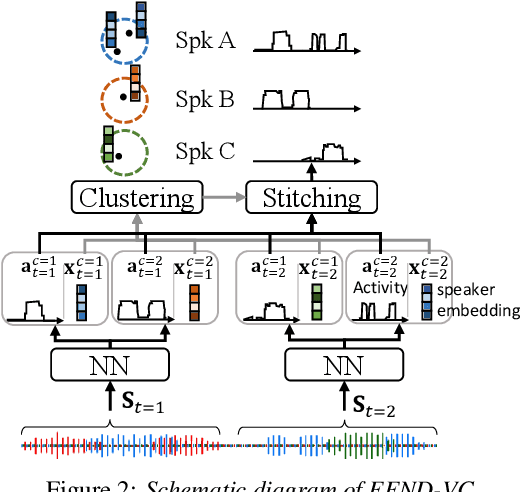
Combining end-to-end neural speaker diarization (EEND) with vector clustering (VC), known as EEND-VC, has gained interest for leveraging the strengths of both methods. EEND-VC estimates activities and speaker embeddings for all speakers within an audio chunk and uses VC to associate these activities with speaker identities across different chunks. EEND-VC generates thus multiple streams of embeddings, one for each speaker in a chunk. We can cluster these embeddings using constrained agglomerative hierarchical clustering (cAHC), ensuring embeddings from the same chunk belong to different clusters. This paper introduces an alternative clustering approach, a multi-stream extension of the successful Bayesian HMM clustering of x-vectors (VBx), called MS-VBx. Experiments on three datasets demonstrate that MS-VBx outperforms cAHC in diarization and speaker counting performance.
Multi-Speaker and Wide-Band Simulated Conversations as Training Data for End-to-End Neural Diarization
Nov 12, 2022End-to-end diarization presents an attractive alternative to standard cascaded diarization systems because a single system can handle all aspects of the task at once. Many flavors of end-to-end models have been proposed but all of them require (so far non-existing) large amounts of annotated data for training. The compromise solution consists in generating synthetic data and the recently proposed simulated conversations (SC) have shown remarkable improvements over the original simulated mixtures (SM). In this work, we create SC with multiple speakers per conversation and show that they allow for substantially better performance than SM, also reducing the dependence on a fine-tuning stage. We also create SC with wide-band public audio sources and present an analysis on several evaluation sets. Together with this publication, we release the recipes for generating such data and models trained on public sets as well as the implementation to efficiently handle multiple speakers per conversation and an auxiliary voice activity detection loss.