 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Training of Speaker Embedding Extractor, Speech and Overlap Detection for Diarization
Paper and Code
Nov 04, 2024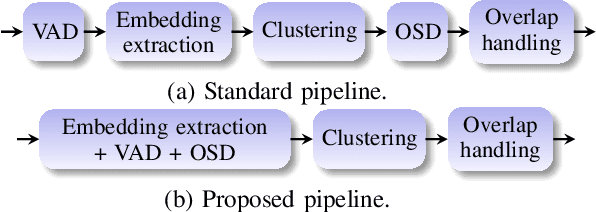
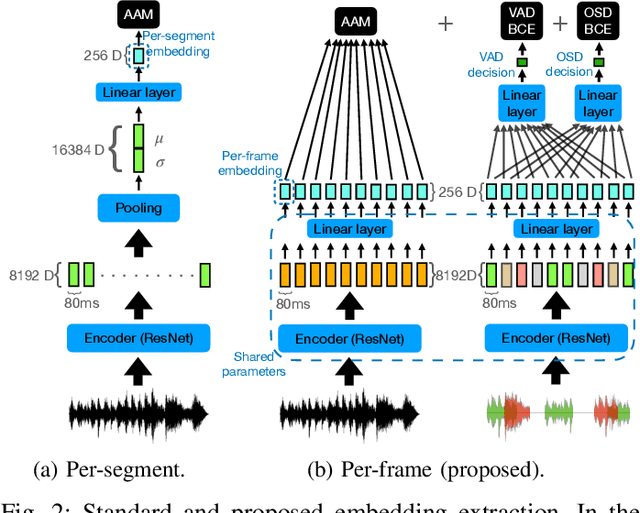
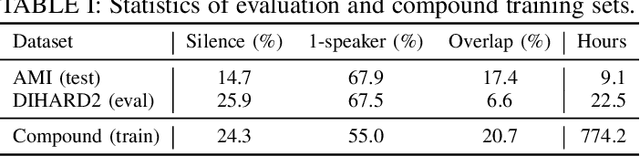
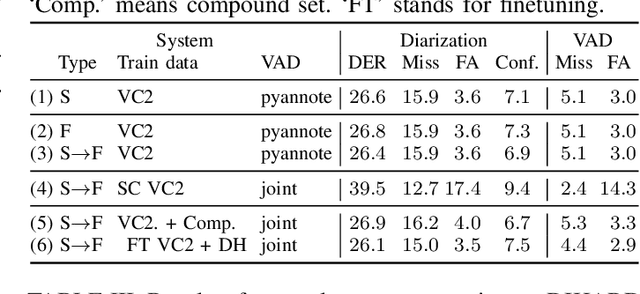
In spite of the popularity of end-to-end diarization systems nowadays, modular systems comprised of voice activity detection (VAD), speaker embedding extraction plus clustering, and overlapped speech detection (OSD) plus handling still attain competitive performance in many conditions. However, one of the main drawbacks of modular systems is the need to run (and train) different modules independently. In this work, we propose an approach to jointly train a model to produce speaker embeddings, VAD and OSD simultaneously and reach competitive performance at a fraction of the inference time of a standard approach. Furthermore, the joint inference leads to a simplified overall pipeline which brings us one step closer to a unified clustering-based method that can be trained end-to-end towards a diarization-specific objective.