 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tune Before Structured Pruning: Towards Compact and Accurate Self-Supervised Models for Speaker Diarization
May 30, 2025
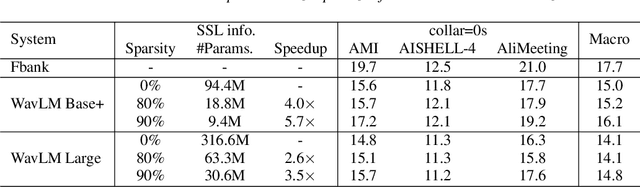


Self-supervised learning (SSL) models like WavLM can be effectively utilized when building speaker diarization systems but are often large and slow, limiting their use in resource constrained scenarios. Previous studies have explored compression techniques, but usually for the price of degraded performance at high pruning ratios. In this work, we propose to compress SSL models through structured pruning by introducing knowledge distillation. Different from the existing works, we emphasize the importance of fine-tuning SSL models before pruning. Experiments on far-field single-channel AMI, AISHELL-4, and AliMeeting datasets show that our method can remove redundant parameters of WavLM Base+ and WavLM Large by up to 80% without any performance degradation. After pruning, the inference speeds on a single GPU for the Base+ and Large models are 4.0 and 2.6 times faster, respectively. Our source code is publicly available.
Leveraging Self-Supervised Learning for Speaker Diarization
Sep 14, 2024



End-to-end neural diarization has evolved considerably over the past few years, but data scarcity is still a major obstacle for further improvements. Self-supervised learning methods such as WavLM have shown promising performance on several downstream tasks, but their application on speaker diarization is somehow limited. In this work, we explore using WavLM to alleviate the problem of data scarcity for neural diarization training. We use the same pipeline as Pyannote and improve the local end-to-end neural diarization with WavLM and Conformer. Experiments on far-field AMI, AISHELL-4, and AliMeeting datasets show that our method substantially outperforms the Pyannote baseline and achieves performance comparable to the state-of-the-art results on AMI and AISHELL-4. In addition, by analyzing the system performance under different data quantity scenarios, we show that WavLM representations are much more robust against data scarcity than filterbank features, enabling less data hungry training strategies. Furthermore, we found that simulated data, usually used to train endto-end diarization models, does not help when using WavLM in our experiments. Additionally, we also evaluate our model on the recent CHiME8 NOTSOFAR-1 task where it achieves better performance than the Pyannote baseline. Our source code is publicly available at https://github.com/BUTSpeechFIT/DiariZen.
Challenging margin-based speaker embedding extractors by using the variational information bottleneck
Jun 18, 2024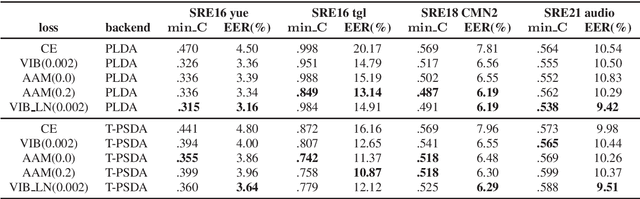
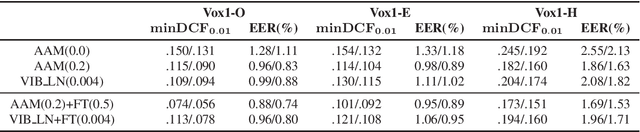
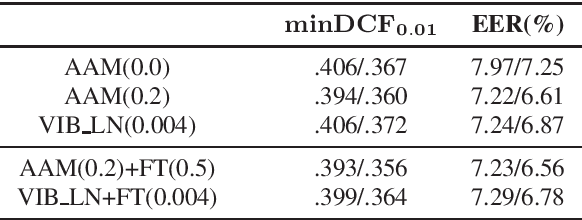
Speaker embedding extractors are typically trained using a classification loss over the training speakers. During the last few years, the standard softmax/cross-entropy loss has been replaced by the margin-based losses, yielding significant improvements in speaker recognition accuracy. Motivated by the fact that the margin merely reduces the logit of the target speaker during training, we consider a probabilistic framework that has a similar effect. The variational information bottleneck provides a principled mechanism for making deterministic nodes stochastic, resulting in an implicit reduction of the posterior of the target speaker. We experiment with a wide range of speaker recognition benchmarks and scoring methods and report competitive results to those obtained with the state-of-the-art Additive Angular Margin loss.
DiaCorrect: Error Correction Back-end For Speaker Diarization
Sep 15, 2023


In this work, we propose an error correction framework, named DiaCorrect, to refine the output of a diarization system in a simple yet effective way. This method is inspired by error correction techniques in automatic speech recognition. Our model consists of two parallel convolutional encoders and a transform-based decoder. By exploiting the interactions between the input recording and the initial system's outputs, DiaCorrect can automatically correct the initial speaker activities to minimize the diarization errors. Experiments on 2-speaker telephony data show that the proposed DiaCorrect can effectively improve the initial model's results. Our source code is publicly available at https://github.com/BUTSpeechFIT/diacorrect.
Multi-Stream Extension of Variational Bayesian HMM Clustering (MS-VBx) for Combined End-to-End and Vector Clustering-based Diarization
May 23, 2023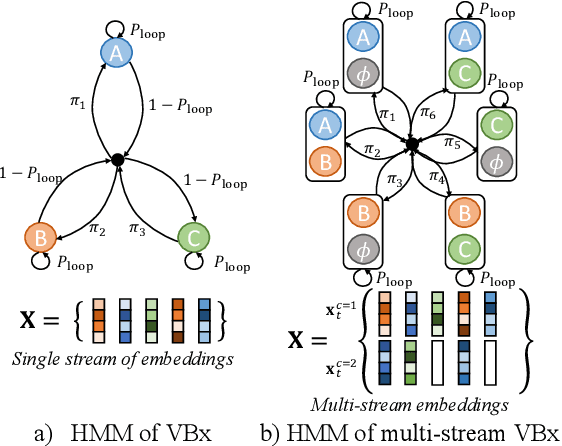
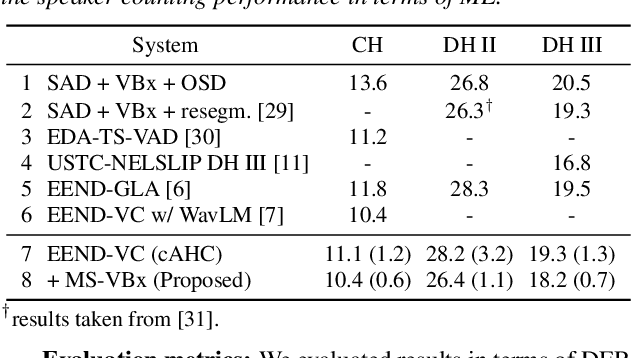
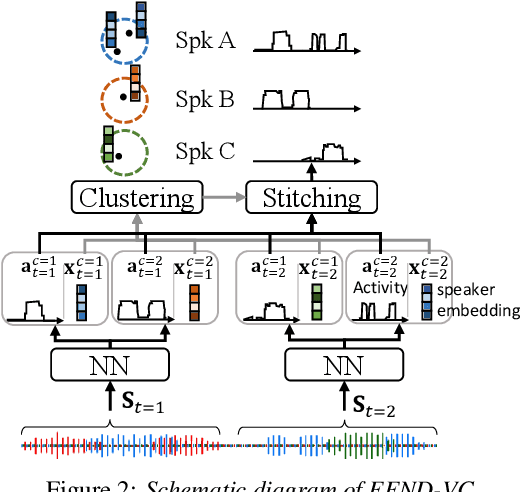
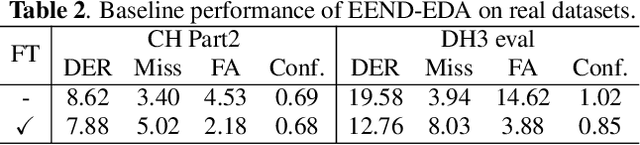
Combining end-to-end neural speaker diarization (EEND) with vector clustering (VC), known as EEND-VC, has gained interest for leveraging the strengths of both methods. EEND-VC estimates activities and speaker embeddings for all speakers within an audio chunk and uses VC to associate these activities with speaker identities across different chunks. EEND-VC generates thus multiple streams of embeddings, one for each speaker in a chunk. We can cluster these embeddings using constrained agglomerative hierarchical clustering (cAHC), ensuring embeddings from the same chunk belong to different clusters. This paper introduces an alternative clustering approach, a multi-stream extension of the successful Bayesian HMM clustering of x-vectors (VBx), called MS-VBx. Experiments on three datasets demonstrate that MS-VBx outperforms cAHC in diarization and speaker counting performance.
Stabilized training of joint energy-based models and their practical applications
Mar 07, 2023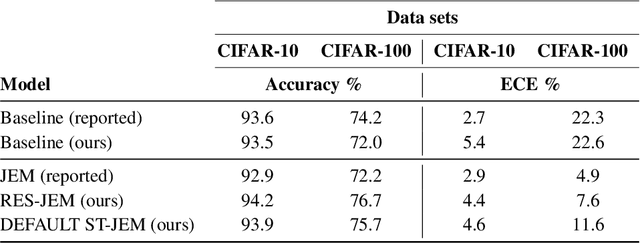
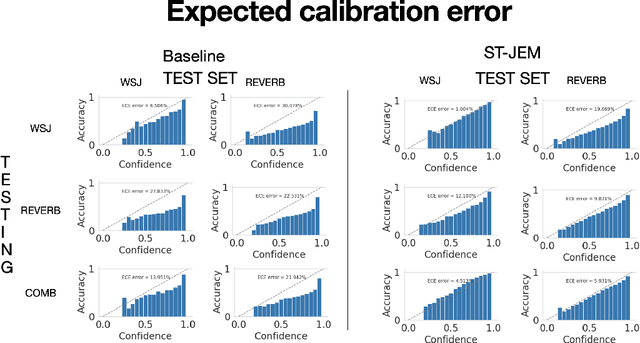
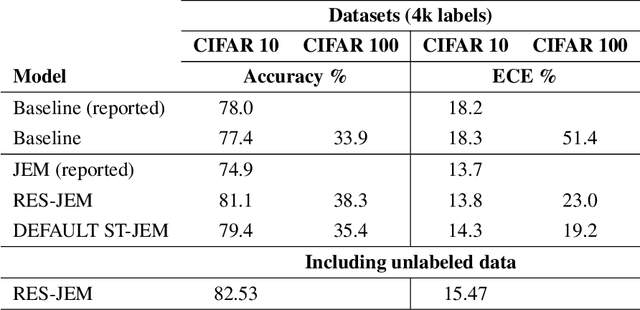
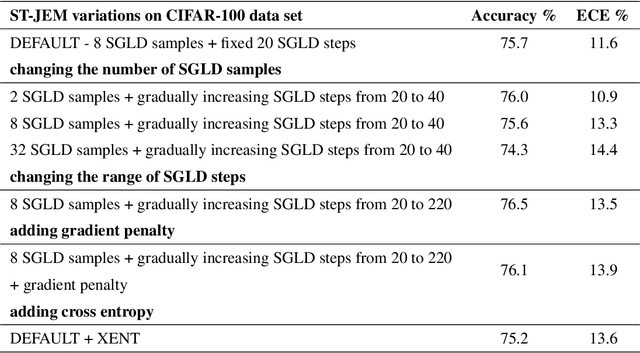
The recently proposed Joint Energy-based Model (JEM) interprets discriminatively trained classifier $p(y|x)$ as an energy model, which is also trained as a generative model describing the distribution of the input observations $p(x)$. The JEM training relies on "positive examples" (i.e. examples from the training data set) as well as on "negative examples", which are samples from the modeled distribution $p(x)$ generated by means of Stochastic Gradient Langevin Dynamics (SGLD). Unfortunately, SGLD often fails to deliver negative samples of sufficient quality during the standard JEM training, which causes a very unbalanced contribution from the positive and negative examples when calculating gradients for JEM updates. As a consequence, the standard JEM training is quite unstable requiring careful tuning of hyper-parameters and frequent restarts when the training starts diverging. This makes it difficult to apply JEM to different neural network architectures, modalities, and tasks. In this work, we propose a training procedure that stabilizes SGLD-based JEM training (ST-JEM) by balancing the contribution from the positive and negative examples. We also propose to add an additional "regularization" term to the training objective -- MI between the input observations $x$ and output labels $y$ -- which encourages the JEM classifier to make more certain decisions about output labels. We demonstrate the effectiveness of our approach on the CIFAR10 and CIFAR100 tasks. We also consider the task of classifying phonemes in a speech signal, for which we were not able to train JEM without the proposed stabilization. We show that a convincing speech can be generated from the trained model. Alternatively, corrupted speech can be de-noised by bringing it closer to the modeled speech distribution using a few SGLD iterations. We also propose and discuss additional applications of the trained model.
Speech-based emotion recognition with self-supervised models using attentive channel-wise correlations and label smoothing
Nov 03, 2022When recognizing emotions from speech, we encounter two common problems: how to optimally capture emotion-relevant information from the speech signal and how to best quantify or categorize the noisy subjective emotion labels. Self-supervised pre-trained representations can robustly capture information from speech enabling state-of-the-art results in many downstream tasks including emotion recognition. However, better ways of aggregating the information across time need to be considered as the relevant emotion information is likely to appear piecewise and not uniformly across the signal. For the labels, we need to take into account that there is a substantial degree of noise that comes from the subjective human annotations. In this paper, we propose a novel approach to attentive pooling based on correlations between the representations' coefficients combined with label smoothing, a method aiming to reduce the confidence of the classifier on the training labels. We evaluate our proposed approach on the benchmark dataset IEMOCAP, and demonstrate high performance surpassing that in the literature. The code to reproduce the results is available at github.com/skakouros/s3prl_attentive_correlation.
Extracting speaker and emotion information from self-supervised speech models via channel-wise correlations
Oct 15, 2022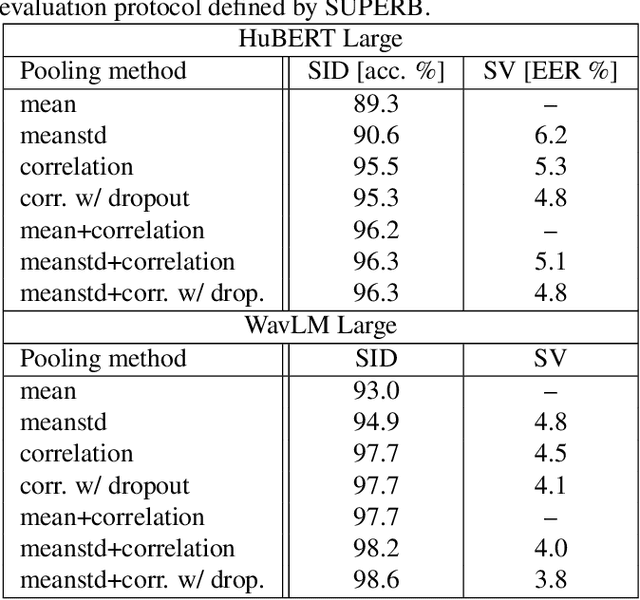
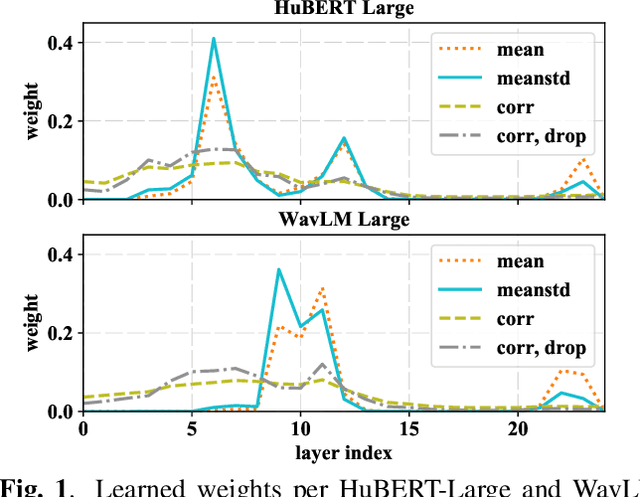
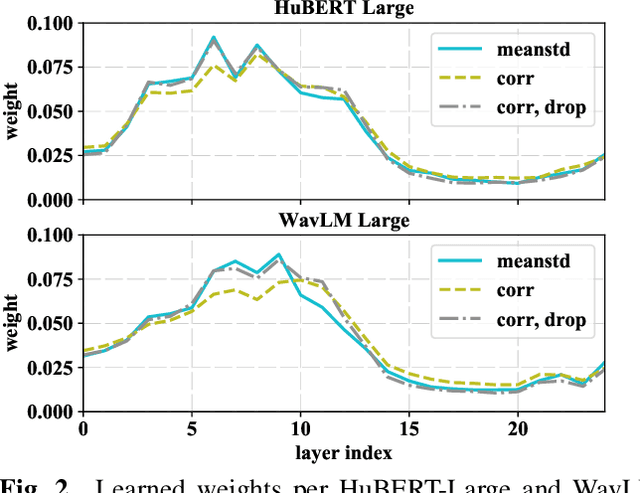
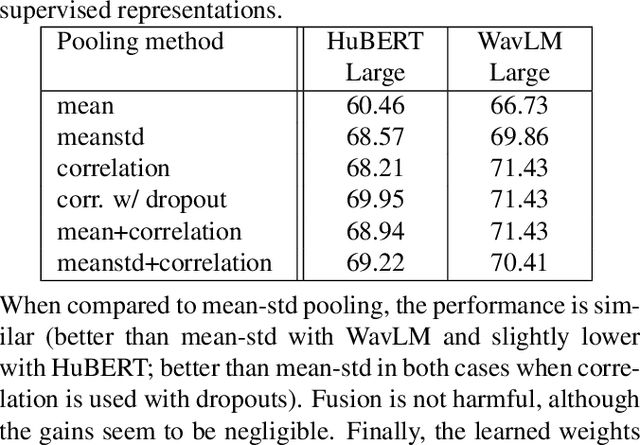
Self-supervised learning of speech representations from large amounts of unlabeled data has enabled state-of-the-art results in several speech processing tasks. Aggregating these speech representations across time is typically approached by using descriptive statistics, and in particular, using the first- and second-order statistics of representation coefficients. In this paper, we examine an alternative way of extracting speaker and emotion information from self-supervised trained models, based on the correlations between the coefficients of the representations - correlation pooling. We show improvements over mean pooling and further gains when the pooling methods are combined via fusion. The code is available at github.com/Lamomal/s3prl_correlation.
An attention-based backend allowing efficient fine-tuning of transformer models for speaker verification
Oct 03, 2022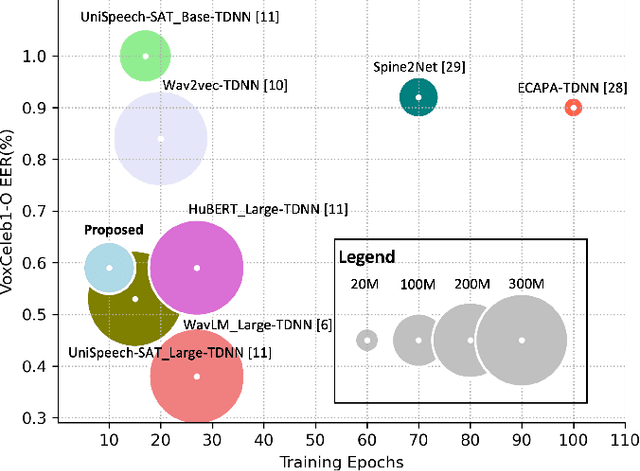

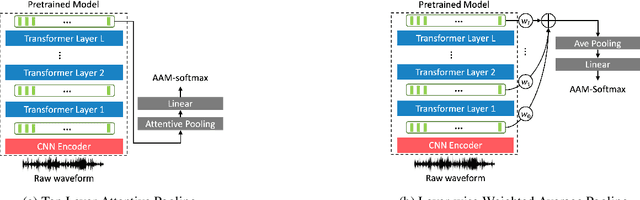

In recent years, self-supervised learning paradigm has received extensive attention due to its great success in various down-stream tasks. However, the fine-tuning strategies for adapting those pre-trained models to speaker verification task have yet to be fully explored. In this paper, we analyze several feature extraction approaches built on top of a pre-trained model, as well as regularization and learning rate schedule to stabilize the fine-tuning process and further boost performance: multi-head factorized attentive pooling is proposed to factorize the comparison of speaker representations into multiple phonetic clusters. We regularize towards the parameters of the pre-trained model and we set different learning rates for each layer of the pre-trained model during fine-tuning. The experimental results show our method can significantly shorten the training time to 4 hours and achieve SOTA performance: 0.59%, 0.79% and 1.77% EER on Vox1-O, Vox1-E and Vox1-H, respectively.
Analyzing speaker verification embedding extractors and back-ends under language and channel mismatch
Mar 19, 2022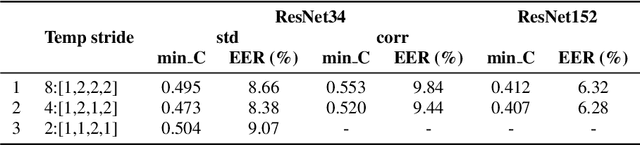
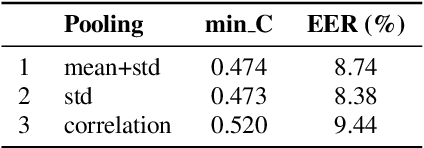
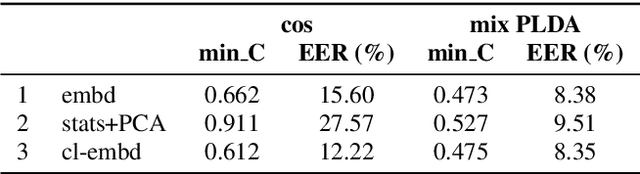
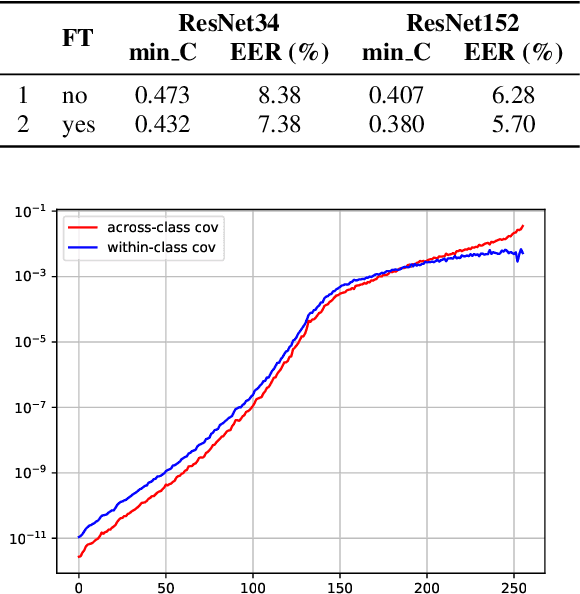
In this paper, we analyze the behavior and performance of speaker embeddings and the back-end scoring model under domain and language mismatch. We present our findings regarding ResNet-based speaker embedding architectures and show that reduced temporal stride yields improved performance. We then consider a PLDA back-end and show how a combination of small speaker subspace, language-dependent PLDA mixture, and nuisance-attribute projection can have a drastic impact on the performance of the system. Besides, we present an efficient way of scoring and fusing class posterior logit vectors recently shown to perform well for speaker verification task. The experiments are performed using the NIST SRE 2021 setup.