 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilized training of joint energy-based models and their practical applications
Mar 07, 2023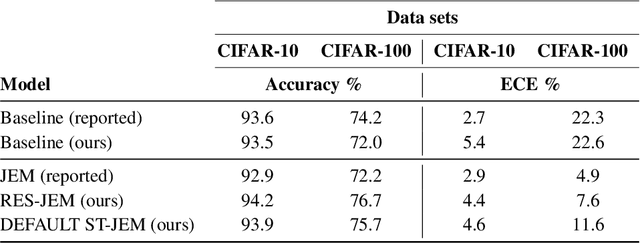
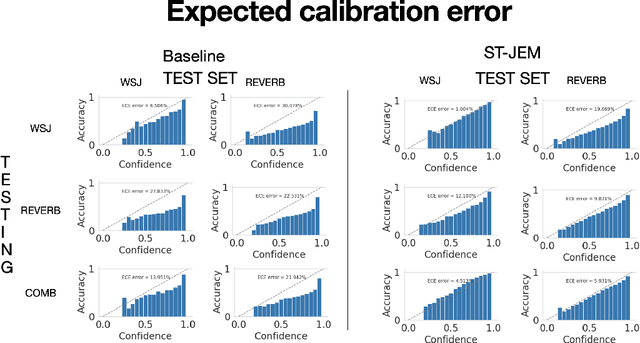
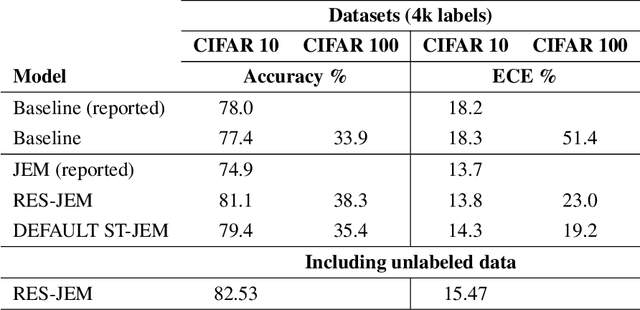
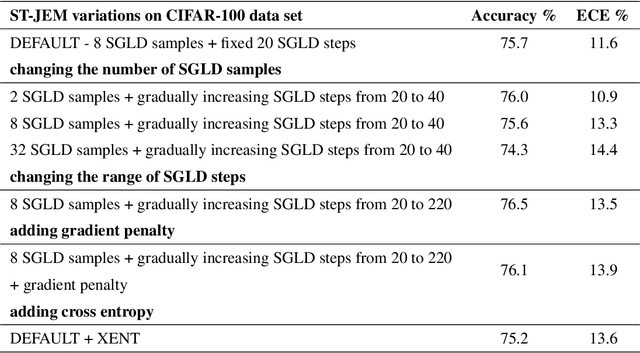
The recently proposed Joint Energy-based Model (JEM) interprets discriminatively trained classifier $p(y|x)$ as an energy model, which is also trained as a generative model describing the distribution of the input observations $p(x)$. The JEM training relies on "positive examples" (i.e. examples from the training data set) as well as on "negative examples", which are samples from the modeled distribution $p(x)$ generated by means of Stochastic Gradient Langevin Dynamics (SGLD). Unfortunately, SGLD often fails to deliver negative samples of sufficient quality during the standard JEM training, which causes a very unbalanced contribution from the positive and negative examples when calculating gradients for JEM updates. As a consequence, the standard JEM training is quite unstable requiring careful tuning of hyper-parameters and frequent restarts when the training starts diverging. This makes it difficult to apply JEM to different neural network architectures, modalities, and tasks. In this work, we propose a training procedure that stabilizes SGLD-based JEM training (ST-JEM) by balancing the contribution from the positive and negative examples. We also propose to add an additional "regularization" term to the training objective -- MI between the input observations $x$ and output labels $y$ -- which encourages the JEM classifier to make more certain decisions about output labels. We demonstrate the effectiveness of our approach on the CIFAR10 and CIFAR100 tasks. We also consider the task of classifying phonemes in a speech signal, for which we were not able to train JEM without the proposed stabilization. We show that a convincing speech can be generated from the trained model. Alternatively, corrupted speech can be de-noised by bringing it closer to the modeled speech distribution using a few SGLD iterations. We also propose and discuss additional applications of the trained model.