 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnLM: Improving Gemini for Learning
Dec 21, 2024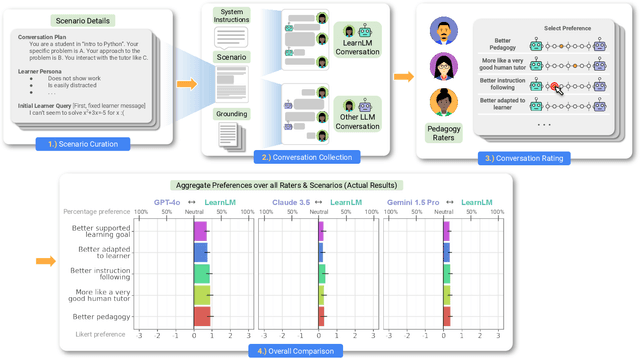
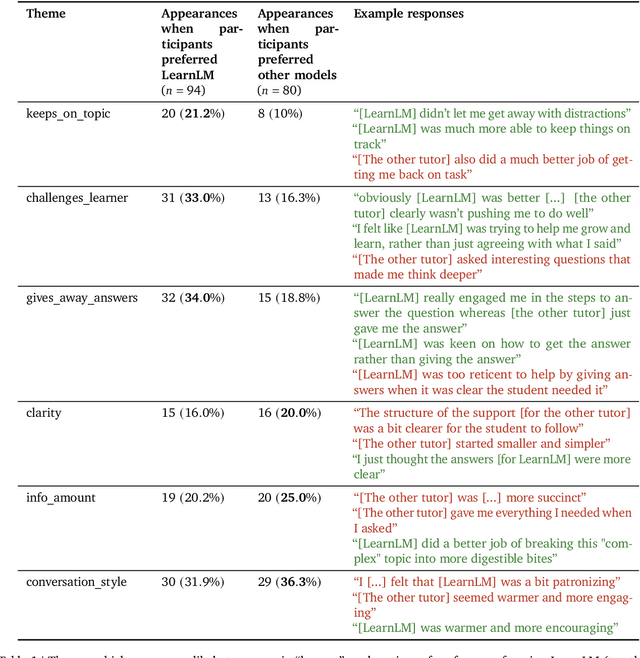
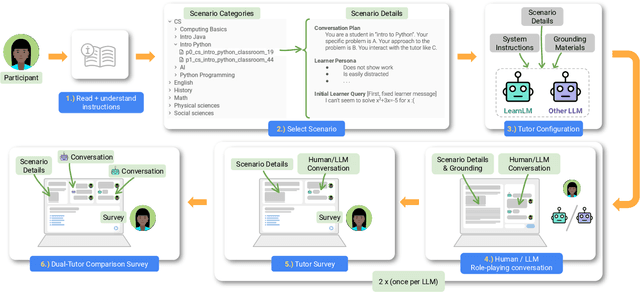
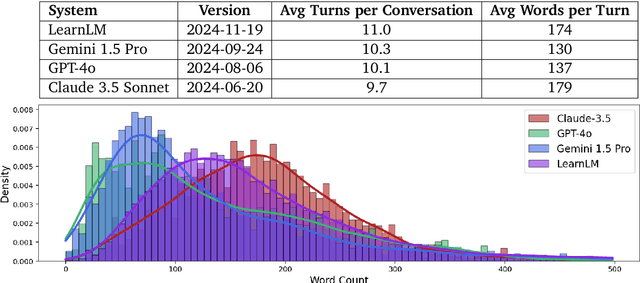
Today's generative AI systems are tuned to present information by default rather than engage users in service of learning as a human tutor would. To address the wide range of potential education use cases for these systems, we reframe the challenge of injecting pedagogical behavior as one of \textit{pedagogical instruction following}, where training and evaluation examples include system-level instructions describing the specific pedagogy attributes present or desired in subsequent model turns. This framing avoids committing our models to any particular definition of pedagogy, and instead allows teachers or developers to specify desired model behavior. It also clears a path to improving Gemini models for learning -- by enabling the addition of our pedagogical data to post-training mixtures -- alongside their rapidly expanding set of capabilities. Both represent important changes from our initial tech report. We show how training with pedagogical instruction following produces a LearnLM model (available on Google AI Studio) that is preferred substantially by expert raters across a diverse set of learning scenarios, with average preference strengths of 31\% over GPT-4o, 11\% over Claude 3.5, and 13\% over the Gemini 1.5 Pro model LearnLM was based on.
Learning to Learn Faster from Human Feedback with Language Model Predictive Control
Feb 18, 2024



Large language models (LLMs) have been shown to exhibit a wide range of capabilities, such as writing robot code from language commands -- enabling non-experts to direct robot behaviors, modify them based on feedback, or compose them to perform new tasks. However, these capabilities (driven by in-context learning) are limited to short-term interactions, where users' feedback remains relevant for only as long as it fits within the context size of the LLM, and can be forgotten over longer interactions. In this work, we investigate fine-tuning the robot code-writing LLMs, to remember their in-context interactions and improve their teachability i.e., how efficiently they adapt to human inputs (measured by average number of corrections before the user considers the task successful). Our key observation is that when human-robot interactions are formulated as a partially observable Markov decision process (in which human language inputs are observations, and robot code outputs are actions), then training an LLM to complete previous interactions can be viewed as training a transition dynamics model -- that can be combined with classic robotics techniques such as model predictive control (MPC) to discover shorter paths to success. This gives rise to Language Model Predictive Control (LMPC), a framework that fine-tunes PaLM 2 to improve its teachability on 78 tasks across 5 robot embodiments -- improving non-expert teaching success rates of unseen tasks by 26.9% while reducing the average number of human corrections from 2.4 to 1.9. Experiments show that LMPC also produces strong meta-learners, improving the success rate of in-context learning new tasks on unseen robot embodiments and APIs by 31.5%. See videos, code, and demos at: https://robot-teaching.github.io/.
AutoRT: Embodied Foundation Models for Large Scale Orchestration of Robotic Agents
Jan 23, 2024Foundation models that incorporate language, vision, and more recently actions have revolutionized the ability to harness internet scale data to reason about useful tasks. However, one of the key challenges of training embodied foundation models is the lack of data grounded in the physical world. In this paper, we propose AutoRT, a system that leverages existing foundation models to scale up the deployment of operational robots in completely unseen scenarios with minimal human supervision. AutoRT leverages vision-language models (VLMs) for scene understanding and grounding, and further uses large language models (LLMs) for proposing diverse and novel instructions to be performed by a fleet of robots. Guiding data collection by tapping into the knowledge of foundation models enables AutoRT to effectively reason about autonomy tradeoffs and safety while significantly scaling up data collection for robot learning. We demonstrate AutoRT proposing instructions to over 20 robots across multiple buildings and collecting 77k real robot episodes via both teleoperation and autonomous robot policies. We experimentally show that such "in-the-wild" data collected by AutoRT is significantly more diverse, and that AutoRT's use of LLMs allows for instruction following data collection robots that can align to human preferences.
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Jul 28, 2023We study how vision-language models trained on Internet-scale data can be incorporated directly into end-to-end robotic control to boost generalization and enable emergent semantic reasoning. Our goal is to enable a single end-to-end trained model to both learn to map robot observations to actions and enjoy the benefits of large-scale pretraining on language and vision-language data from the web. To this end, we propose to co-fine-tune state-of-the-art vision-language models on both robotic trajectory data and Internet-scale vision-language tasks, such as visual question answering. In contrast to other approaches, we propose a simple, general recipe to achieve this goal: in order to fit both natural language responses and robotic actions into the same format, we express the actions as text tokens and incorporate them directly into the training set of the model in the same way as natural language tokens. We refer to such category of models as vision-language-action models (VLA) and instantiate an example of such a model, which we call RT-2. Our extensive evaluation (6k evaluation trials) shows that our approach leads to performant robotic policies and enables RT-2 to obtain a range of emergent capabilities from Internet-scale training. This includes significantly improved generalization to novel objects, the ability to interpret commands not present in the robot training data (such as placing an object onto a particular number or icon), and the ability to perform rudimentary reasoning in response to user commands (such as picking up the smallest or largest object, or the one closest to another object). We further show that incorporating chain of thought reasoning allows RT-2 to perform multi-stage semantic reasoning, for example figuring out which object to pick up for use as an improvised hammer (a rock), or which type of drink is best suited for someone who is tired (an energy drink).