 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Branching Heuristics for Propositional Model Counting
Jul 07, 2020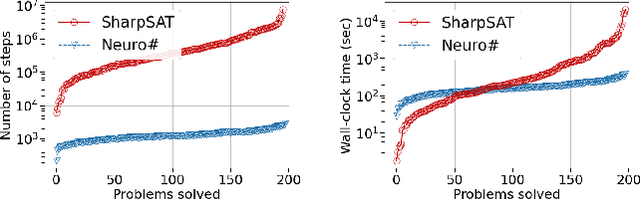
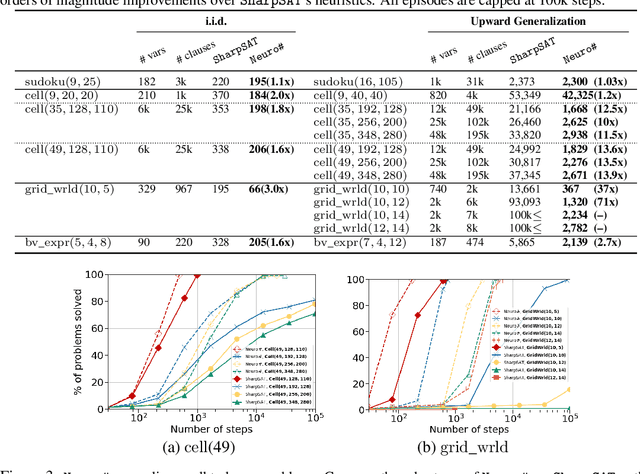
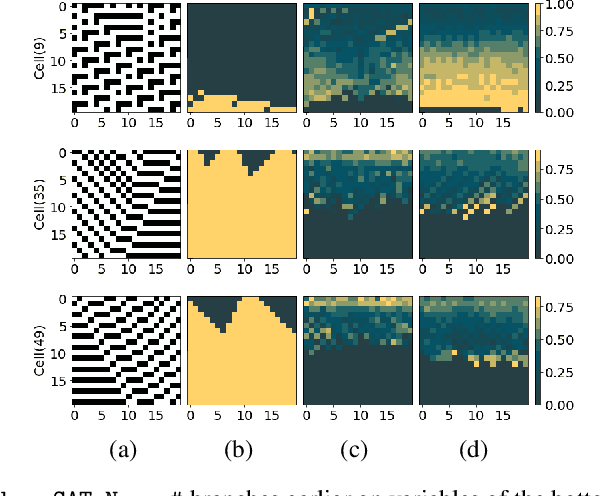
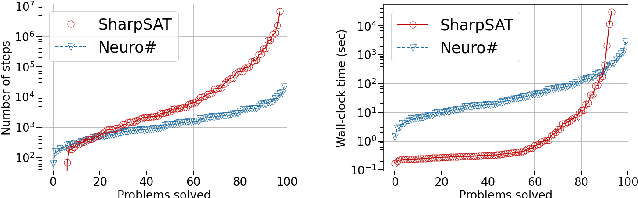
Propositional model counting or #SAT is the problem of computing the number of satisfying assignments of a Boolean formula and many discrete probabilistic inference problems can be translated into a model counting problem to be solved by #SAT solvers. Generic ``exact'' #SAT solvers, however, are often not scalable to industrial-level instances. In this paper, we present Neuro#, an approach for learning branching heuristics for exact #SAT solvers via evolution strategies (ES) to reduce the number of branching steps the solver takes to solve an instance. We experimentally show that our approach not only reduces the step count on similarly distributed held-out instances but it also generalizes to much larger instances from the same problem family. The gap between the learned and the vanilla solver on larger instances is sometimes so wide that the learned solver can even overcome the run time overhead of querying the model and beat the vanilla in wall-clock time by orders of magnitude.
Exploring Strategy-Proofness, Uniqueness, and Pareto Optimality for the Stable Matching Problem with Couples
May 13, 2015
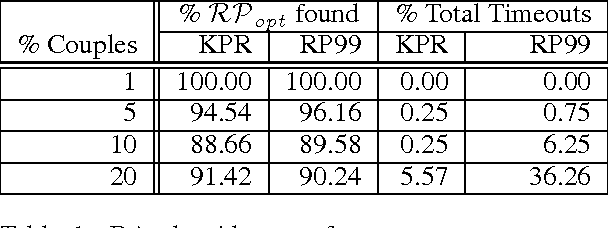

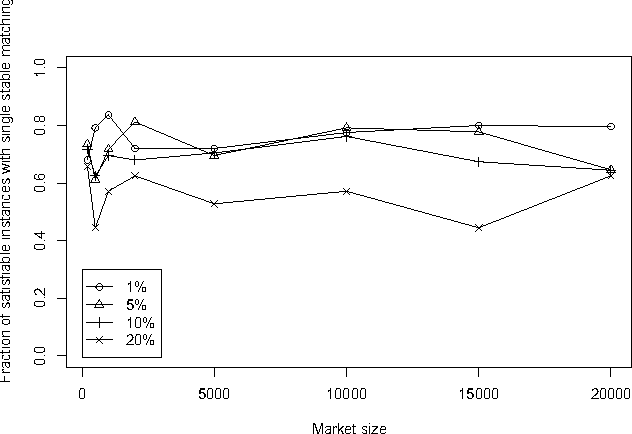
The Stable Matching Problem with Couples (SMP-C) is a ubiquitous real-world extension of the stable matching problem (SMP) involving complementarities. Although SMP can be solved in polynomial time, SMP-C is NP-Complete. Hence, it is not clear which, if any, of the theoretical results surrounding the canonical SMP problem apply in this setting. In this paper, we use a recently-developed SAT encoding to solve SMP-C exactly. This allows us to enumerate all stable matchings for any given instance of SMP-C. With this tool, we empirically evaluate some of the properties that have been hypothesized to hold for SMP-C. We take particular interest in investigating if, as the size of the market grows, the percentage of instances with unique stable matchings also grows. While we did not find this trend among the random problem instances we sampled, we did find that the percentage of instances with an resident optimal matching seems to more closely follow the trends predicted by previous conjectures. We also define and investigate resident Pareto optimal stable matchings, finding that, even though this is important desideratum for the deferred acceptance style algorithms previously designed to solve SMP-C, they do not always find one. We also investigate strategy-proofness for SMP-C, showing that even if only one stable matching exists, residents still have incentive to misreport their preferences. However, if a problem has a resident optimal stable matching, we show that residents cannot manipulate via truncation.
Proceedings of the Twenty-First Conference on Uncertainty in Artificial Intelligence
Aug 28, 2014This is the Proceedings of the Twenty-First Conference on Uncertainty in Artificial Intelligence, which was held in Edinburgh, Scotland July 26 - 29 2005.
Solving #SAT and Bayesian Inference with Backtracking Search
Jan 15, 2014
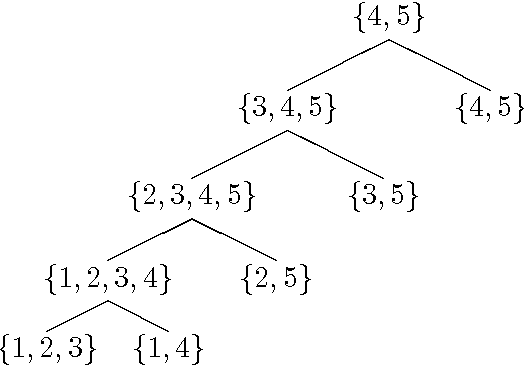
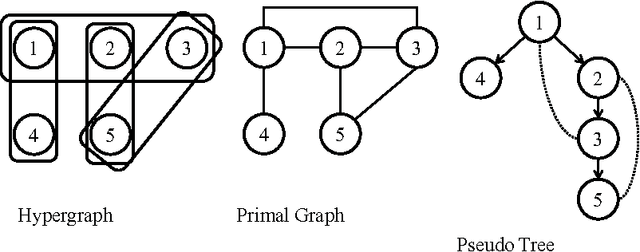
Inference in Bayes Nets (BAYES) is an important problem with numerous applications in probabilistic reasoning. Counting the number of satisfying assignments of a propositional formula (#SAT) is a closely related problem of fundamental theoretical importance. Both these problems, and others, are members of the class of sum-of-products (SUMPROD) problems. In this paper we show that standard backtracking search when augmented with a simple memoization scheme (caching) can solve any sum-of-products problem with time complexity that is at least as good any other state-of-the-art exact algorithm, and that it can also achieve the best known time-space tradeoff. Furthermore, backtracking's ability to utilize more flexible variable orderings allows us to prove that it can achieve an exponential speedup over other standard algorithms for SUMPROD on some instances. The ideas presented here have been utilized in a number of solvers that have been applied to various types of sum-of-product problems. These system's have exploited the fact that backtracking can naturally exploit more of the problem's structure to achieve improved performance on a range of probleminstances. Empirical evidence of this performance gain has appeared in published works describing these solvers, and we provide references to these works.
Probability Distributions Over Possible Worlds
Mar 27, 2013In Probabilistic Logic Nilsson uses the device of a probability distribution over a set of possible worlds to assign probabilities to the sentences of a logical language. In his paper Nilsson concentrated on inference and associated computational issues. This paper, on the other hand, examines the probabilistic semantics in more detail, particularly for the case of first-order languages, and attempts to explain some of the features and limitations of this form of probability logic. It is pointed out that the device of assigning probabilities to logical sentences has certain expressive limitations. In particular, statistical assertions are not easily expressed by such a device. This leads to certain difficulties with attempts to give probabilistic semantics to default reasoning using probabilities assigned to logical sentences.
Lp : A Logic for Statistical Information
Mar 27, 2013
This extended abstract presents a logic, called Lp, that is capable of representing and reasoning with a wide variety of both qualitative and quantitative statistical information. The advantage of this logical formalism is that it offers a declarative representation of statistical knowledge; knowledge represented in this manner can be used for a variety of reasoning tasks. The logic differs from previous work in probability logics in that it uses a probability distribution over the domain of discourse, whereas most previous work (e.g., Nilsson [2], Scott et al. [3], Gaifinan [4], Fagin et al. [5]) has investigated the attachment of probabilities to the sentences of the logic (also, see Halpern [6] and Bacchus [7] for further discussion of the differences). The logic Lp possesses some further important features. First, Lp is a superset of first order logic, hence it can represent ordinary logical assertions. This means that Lp provides a mechanism for integrating statistical information and reasoning about uncertainty into systems based solely on logic. Second, Lp possesses transparent semantics, based on sets and probabilities of those sets. Hence, knowledge represented in Lp can be understood in terms of the simple primative concepts of sets and probabilities. And finally, the there is a sound proof theory that has wide coverage (the proof theory is complete for certain classes of models). The proof theory captures a sufficient range of valid inferences to subsume most previous probabilistic uncertainty reasoning systems. For example, the linear constraints like those generated by Nilsson's probabilistic entailment [2] can be generated by the proof theory, and the Bayesian inference underlying belief nets [8] can be performed. In addition, the proof theory integrates quantitative and qualitative reasoning as well as statistical and logical reasoning. In the next section we briefly examine previous work in probability logics, comparing it to Lp. Then we present some of the varieties of statistical information that Lp is capable of expressing. After this we present, briefly, the syntax, semantics, and proof theory of the logic. We conclude with a few examples of knowledge representation and reasoning in Lp, pointing out the advantages of the declarative representation offered by Lp. We close with a brief discussion of probabilities as degrees of belief, indicating how such probabilities can be generated from statistical knowledge encoded in Lp. The reader who is interested in a more complete treatment should consult Bacchus [7].
Using Causal Information and Local Measures to Learn Bayesian Networks
Mar 06, 2013In previous work we developed a method of learning Bayesian Network models from raw data. This method relies on the well known minimal description length (MDL) principle. The MDL principle is particularly well suited to this task as it allows us to tradeoff, in a principled way, the accuracy of the learned network against its practical usefulness. In this paper we present some new results that have arisen from our work. In particular, we present a new local way of computing the description length. This allows us to make significant improvements in our search algorithm. In addition, we modify our algorithm so that it can take into account partial domain information that might be provided by a domain expert. The local computation of description length also opens the door for local refinement of an existent network. The feasibility of our approach is demonstrated by experiments involving networks of a practical size.
Using First-Order Probability Logic for the Construction of Bayesian Networks
Mar 06, 2013We present a mechanism for constructing graphical models, specifically Bayesian networks, from a knowledge base of general probabilistic information. The unique feature of our approach is that it uses a powerful first-order probabilistic logic for expressing the general knowledge base. This logic allows for the representation of a wide range of logical and probabilistic information. The model construction procedure we propose uses notions from direct inference to identify pieces of local statistical information from the knowledge base that are most appropriate to the particular event we want to reason about. These pieces are composed to generate a joint probability distribution specified as a Bayesian network. Although there are fundamental difficulties in dealing with fully general knowledge, our procedure is practical for quite rich knowledge bases and it supports the construction of a far wider range of networks than allowed for by current template technology.
Using New Data to Refine a Bayesian Network
Feb 27, 2013
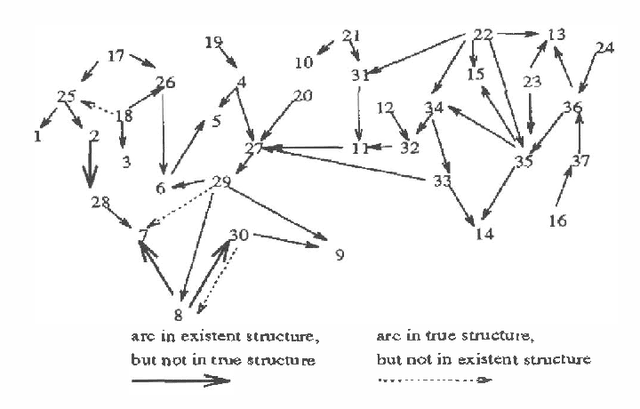
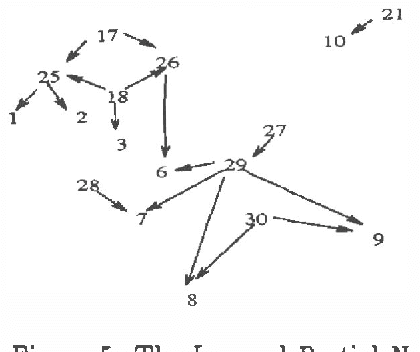
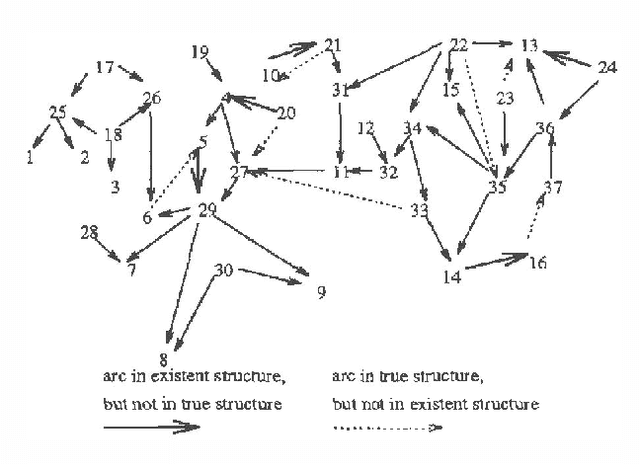
We explore the issue of refining an existent Bayesian network structure using new data which might mention only a subset of the variables. Most previous works have only considered the refinement of the network's conditional probability parameters, and have not addressed the issue of refining the network's structure. We develop a new approach for refining the network's structure. Our approach is based on the Minimal Description Length (MDL) principle, and it employs an adapted version of a Bayesian network learning algorithm developed in our previous work. One of the adaptations required is to modify the previous algorithm to account for the structure of the existent network. The learning algorithm generates a partial network structure which can then be used to improve the existent network. We also present experimental evidence demonstrating the effectiveness of our approach.
Generating New Beliefs From Old
Feb 27, 2013In previous work [BGHK92, BGHK93], we have studied the random-worlds approach -- a particular (and quite powerful) method for generating degrees of belief (i.e., subjective probabilities) from a knowledge base consisting of objective (first-order, statistical, and default) information. But allowing a knowledge base to contain only objective information is sometimes limiting. We occasionally wish to include information about degrees of belief in the knowledge base as well, because there are contexts in which old beliefs represent important information that should influence new beliefs. In this paper, we describe three quite general techniques for extending a method that generates degrees of belief from objective information to one that can make use of degrees of belief as well. All of our techniques are bloused on well-known approaches, such as cross-entropy. We discuss general connections between the techniques and in particular show that, although conceptually and technically quite different, all of the techniques give the same answer when applied to the random-worlds method.