 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaPIM: Scalable Sequence CLAssification using Processing-In-Memory
Feb 16, 2023DNA sequence classification is a fundamental task in computational biology with vast implications for applications such as disease prevention and drug design. Therefore, fast high-quality sequence classifiers are significantly important. This paper introduces ClaPIM, a scalable DNA sequence classification architecture based on the emerging concept of hybrid in-crossbar and near-crossbar memristive processing-in-memory (PIM). We enable efficient and high-quality classification by uniting the filter and search stages within a single algorithm. Specifically, we propose a custom filtering technique that drastically narrows the search space and a search approach that facilitates approximate string matching through a distance function. ClaPIM is the first PIM architecture for scalable approximate string matching that benefits from the high density of memristive crossbar arrays and the massive computational parallelism of PIM. Compared with Kraken2, a state-of-the-art software classifier, ClaPIM provides significantly higher classification quality (up to 20x improvement in F1 score) and also demonstrates a 1.8x throughput improvement. Compared with EDAM, a recently-proposed SRAM-based accelerator that is restricted to small datasets, we observe both a 30.4x improvement in normalized throughput per area and a 7% increase in classification precision.
MTJ-Based Hardware Synapse Design for Quantized Deep Neural Networks
Dec 29, 2019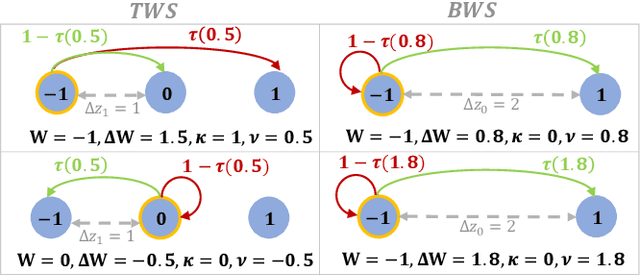

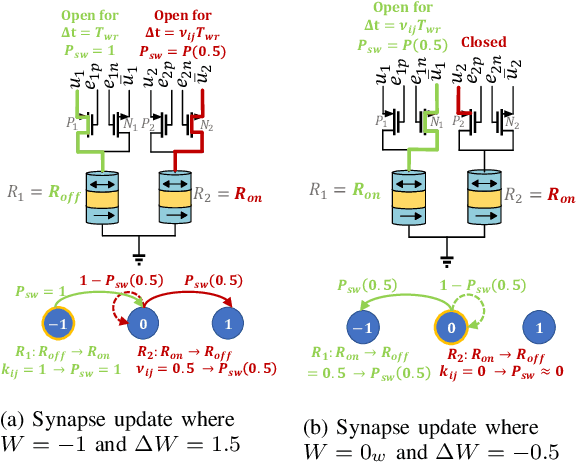
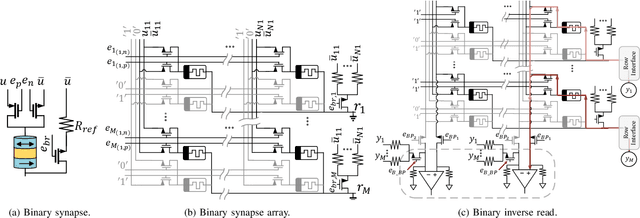
Quantized neural networks (QNNs) are being actively researched as a solution for the computational complexity and memory intensity of deep neural networks. This has sparked efforts to develop algorithms that support both inference and training with quantized weight and activation values without sacrificing accuracy. A recent example is the GXNOR framework for stochastic training of ternary and binary neural networks. In this paper, we introduce a novel hardware synapse circuit that uses magnetic tunnel junction (MTJ) devices to support the GXNOR training. Our solution enables processing near memory (PNM) of QNNs, therefore can further reduce the data movements from and into the memory. We simulated MTJ-based stochastic training of a TNN over the MNIST and SVHN datasets and achieved an accuracy of 98.61% and 93.99%, respectively.