 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiMA: A Fast and Scalable History-based Memory Access Engine for Differentiable Neural Computer
Feb 15, 2022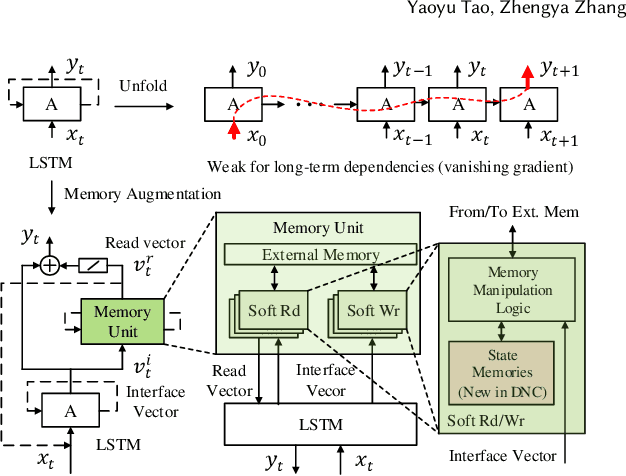
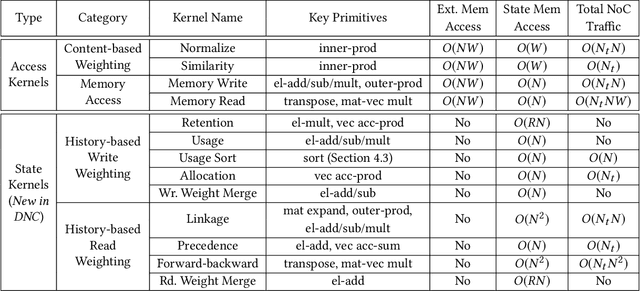
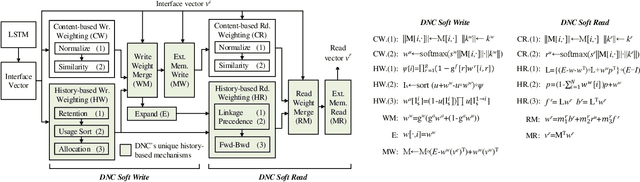
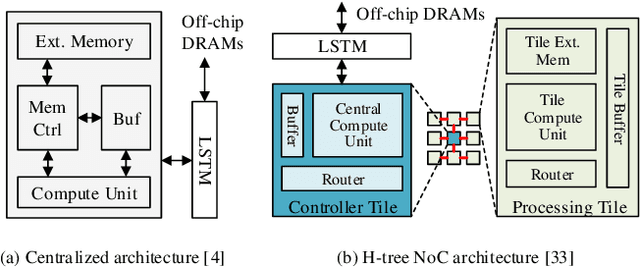
Memory-augmented neural networks (MANNs) provide better inference performance in many tasks with the help of an external memory. The recently developed differentiable neural computer (DNC) is a MANN that has been shown to outperform in representing complicated data structures and learning long-term dependencies. DNC's higher performance is derived from new history-based attention mechanisms in addition to the previously used content-based attention mechanisms. History-based mechanisms require a variety of new compute primitives and state memories, which are not supported by existing neural network (NN) or MANN accelerators. We present HiMA, a tiled, history-based memory access engine with distributed memories in tiles. HiMA incorporates a multi-mode network-on-chip (NoC) to reduce the communication latency and improve scalability. An optimal submatrix-wise memory partition strategy is applied to reduce the amount of NoC traffic; and a two-stage usage sort method leverages distributed tiles to improve computation speed. To make HiMA fundamentally scalable, we create a distributed version of DNC called DNC-D to allow almost all memory operations to be applied to local memories with trainable weighted summation to produce the global memory output. Two approximation techniques, usage skimming and softmax approximation, are proposed to further enhance hardware efficiency. HiMA prototypes are created in RTL and synthesized in a 40nm technology. By simulations, HiMA running DNC and DNC-D demonstrates 6.47x and 39.1x higher speed, 22.8x and 164.3x better area efficiency, and 6.1x and 61.2x better energy efficiency over the state-of-the-art MANN accelerator. Compared to an Nvidia 3080Ti GPU, HiMA demonstrates speedup by up to 437x and 2,646x when running DNC and DNC-D, respectively.
High-Throughput Split-Tree Architecture for Nonbinary SCL Polar Decoder
Feb 15, 2022

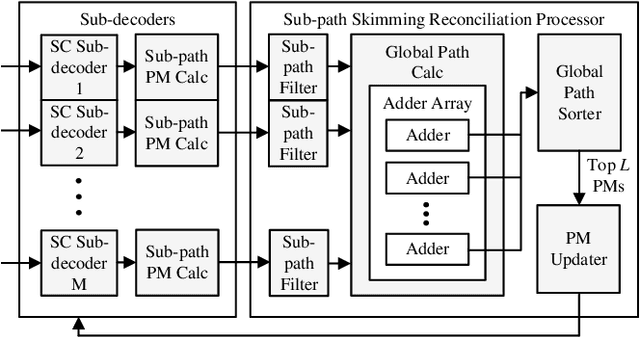
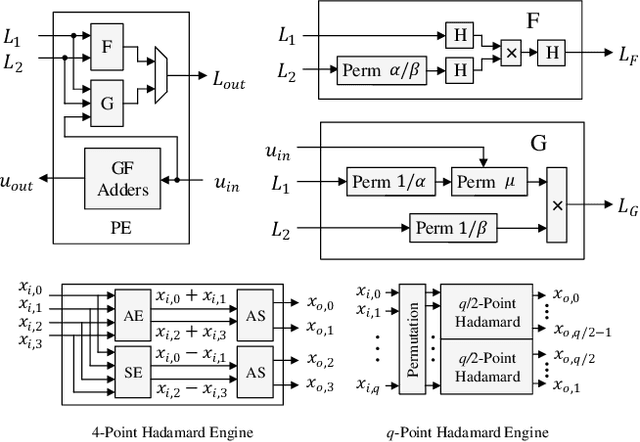
Nonbinary polar codes defined over Galois field GF(q) have shown improved error-correction performance than binary polar codes using successive-cancellation list (SCL) decoding. However, nonbinary operations are complex and a direct-mapped decoder results in a low throughput, representing difficulties for practical adoptions. In this work, we develop, to the best of our knowledge, the first hardware implementation for nonbinary SCL polar decoding. We present a high-throughput decoder architecture using a split-tree algorithm. The sub-trees are decoded in parallel by smaller sub-decoders with a reconciliation stage to maintain constraints between sub-trees. A skimming algorithm is proposed to reduce the reconciliation complexity for further improved throughput. The split-tree nonbinary SCL (S-NBSCL) polar decoder is prototyped using a 28nm CMOS technology for a (128,64) polar code over GF(256). The decoder delivers 26.1 Mb/s throughput, 11.65 Mb/s/mm$^2$ area efficiency and 28.8 nJ/b energy efficiency, outperforming the direct-mapped decoder by 10.3x, 4.4x and 2.7x, respectively, while achieving excellent error-correction performance.
Fast and Scalable Memristive In-Memory Sorting with Column-Skipping Algorithm
Feb 15, 2022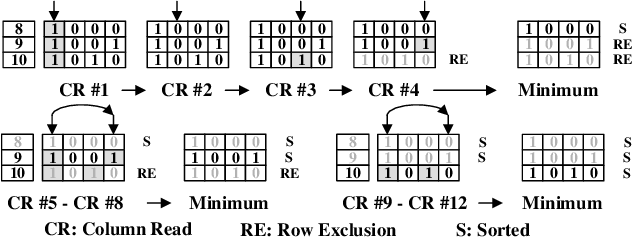
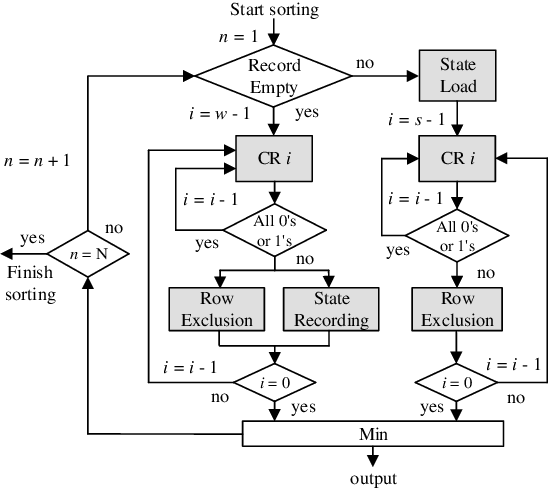
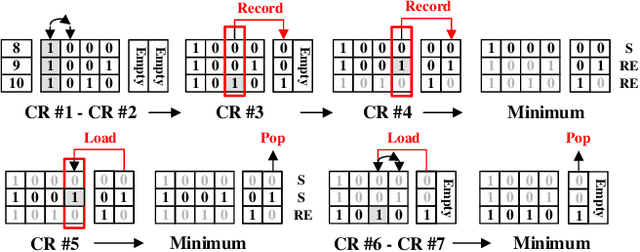
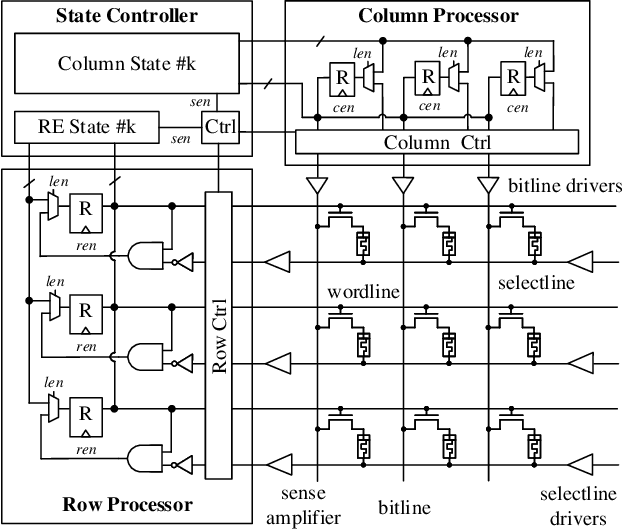
Memristive in-memory sorting has been proposed recently to improve hardware sorting efficiency. Using iterative in-memory min computations, data movements between memory and external processing units can be eliminated for improved latency and energy efficiency. However, the bit-traversal algorithm to search the min requires a large number of column reads on memristive memory. In this work, we propose a column-skipping algorithm with help of a near-memory circuit. Redundant column reads can be skipped based on recorded states for improved latency and hardware efficiency. To enhance the scalability, we develop a multi-bank management that enables column-skipping for dataset stored in different memristive memory banks. Prototype column-skipping sorters are implemented with a 1T1R memristive memory in 40nm CMOS technology. Experimented on a variety of sorting datasets, the length-1024 32-bit column-skipping sorter with state recording of 2 demonstrates up to 4.08x speedup, 3.14x area efficiency and 3.39x energy efficiency, respectively, over the latest memristive in-memory sorting.
DNC-Aided SCL-Flip Decoding of Polar Codes
Jan 26, 2021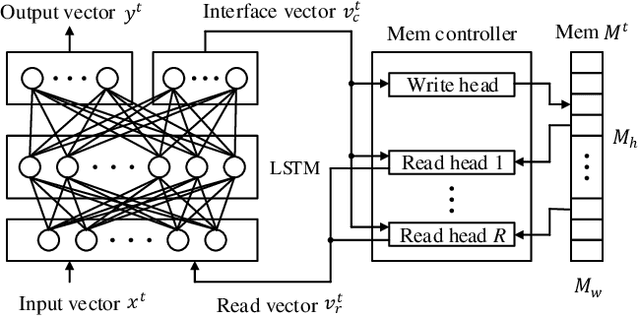
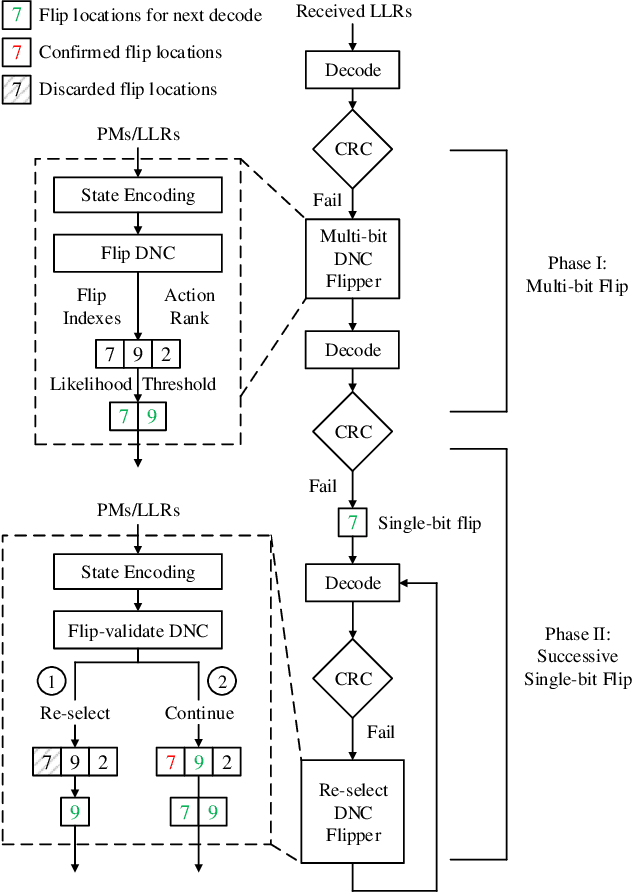
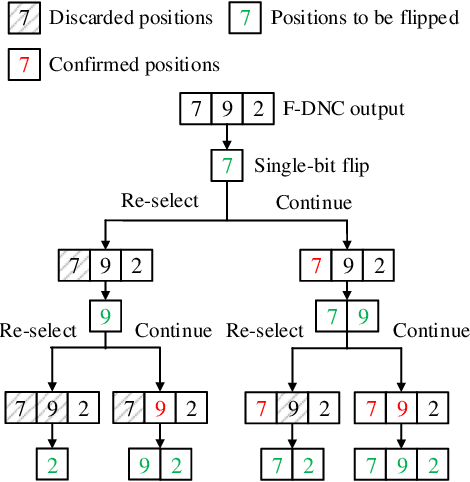
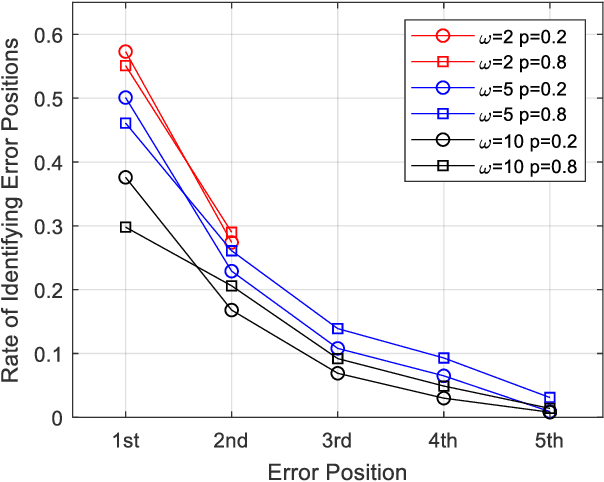
Successive-cancellation list (SCL) decoding of polar codes is promising towards practical adoptions. However, the performance is not satisfactory with moderate code length. Variety of flip algorithms are developed to solve this problem. The key for successful flip is to accurately identify error bit positions. However, state-of-the-art flip strategies, including heuristic and deep-learning-aided (DL-aided) approaches, are not effective in handling long-distance dependencies in sequential SCL decoding. In this work, we propose a new DNC-aided flip decoding with differentiable neural computer (DNC). New action and state encoding are developed for better training and inference efficiency. The proposed method consists of two phases: i) a flip DNC (F-DNC) is exploited to rank most likely flip positions for multi-bit flipping; ii) if multi-bit flipping fails, a flip-validate DNC (FV-DNC) is used to re-select error position and assist single-bit flipping successively. Training methods are designed accordingly for the two DNCs. Simulation results show that proposed DNC-aided SCL-Flip (DNC-SCLF) decoding can effectively improve the error-correction performance and reduce number of decoding attempts compared to prior works.