 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3-Net: A Fast and Lightweight Video Scene Understanding Network by Single-shot Segmentation
Paper and Code
Nov 04, 2020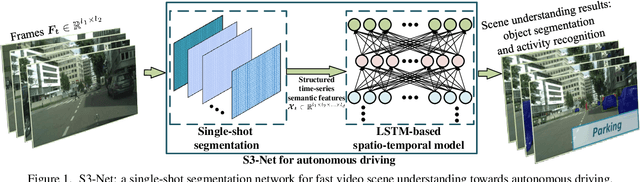
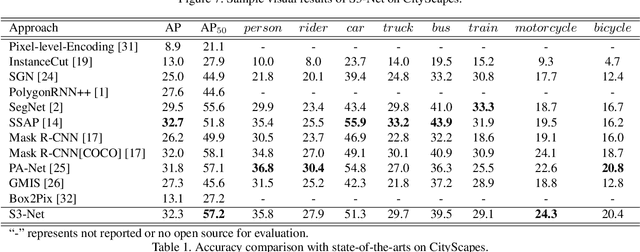
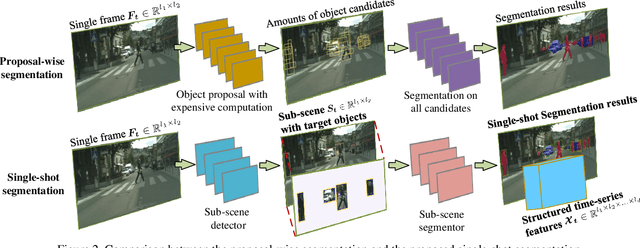
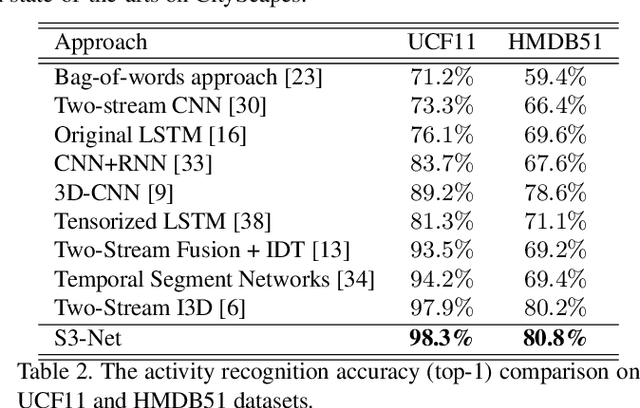
Real-time understanding in video is crucial in various AI applications such as autonomous driving. This work presents a fast single-shot segmentation strategy for video scene understanding. The proposed net, called S3-Net, quickly locates and segments target sub-scenes, meanwhile extracts structured time-series semantic features as inputs to an LSTM-based spatio-temporal model. Utilizing tensorization and quantization techniques, S3-Net is intended to be lightweight for edge computing. Experiments using CityScapes, UCF11, HMDB51 and MOMENTS datasets demonstrate that the proposed S3-Net achieves an accuracy improvement of 8.1% versus the 3D-CNN based approach on UCF11, a storage reduction of 6.9x and an inference speed of 22.8 FPS on CityScapes with a GTX1080Ti GPU.