 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-Stage Federated Learning Approach for Industrial Prognostics Using Large-Scale High-Dimensional Signals
Oct 14, 2024
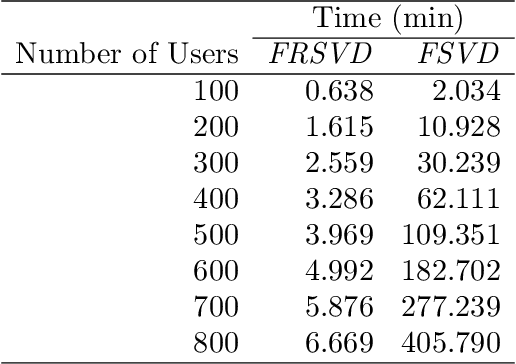
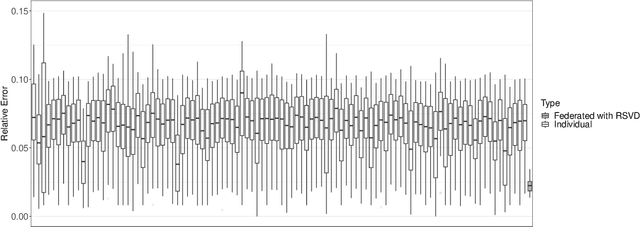
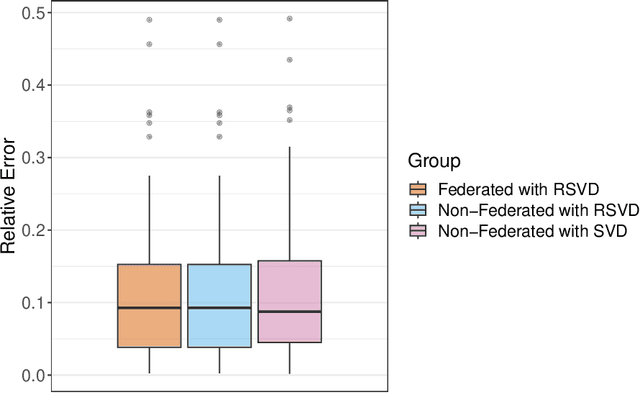
Industrial prognostics aims to develop data-driven methods that leverage high-dimensional degradation signals from assets to predict their failure times. The success of these models largely depends on the availability of substantial historical data for training. However, in practice, individual organizations often lack sufficient data to independently train reliable prognostic models, and privacy concerns prevent data sharing between organizations for collaborative model training. To overcome these challenges, this article proposes a statistical learning-based federated model that enables multiple organizations to jointly train a prognostic model while keeping their data local and secure. The proposed approach involves two key stages: federated dimension reduction and federated (log)-location-scale regression. In the first stage, we develop a federated randomized singular value decomposition algorithm for multivariate functional principal component analysis, which efficiently reduces the dimensionality of degradation signals while maintaining data privacy. The second stage proposes a federated parameter estimation algorithm for (log)-location-scale regression, allowing organizations to collaboratively estimate failure time distributions without sharing raw data. The proposed approach addresses the limitations of existing federated prognostic methods by using statistical learning techniques that perform well with smaller datasets and provide comprehensive failure time distributions. The effectiveness and practicality of the proposed model are validated using simulated data and a dataset from the NASA repository.
Improving EEG Classification Through Randomly Reassembling Original and Generated Data with Transformer-based Diffusion Models
Jul 20, 2024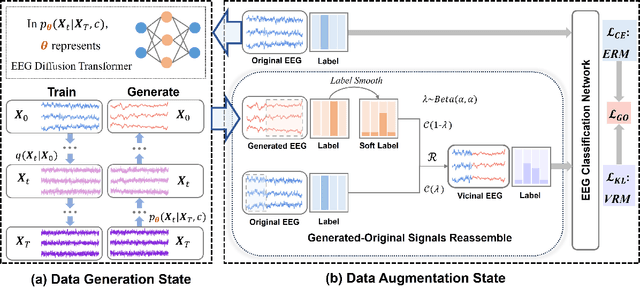
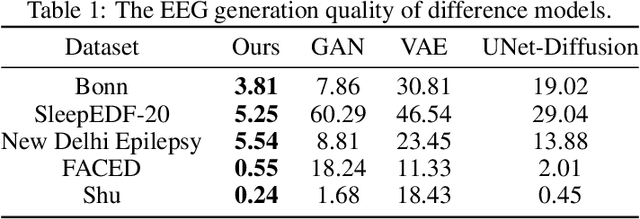
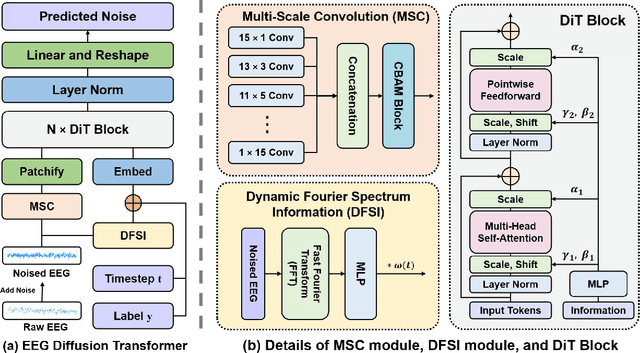
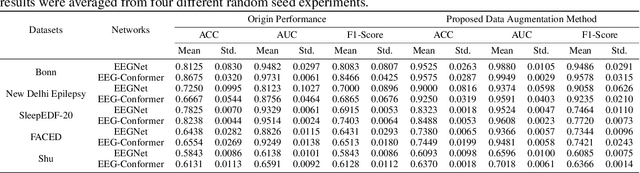
Electroencephalogram (EEG) classification has been widely used in various medical and engineering applications, where it is important for understanding brain function, diagnosing diseases, and assessing mental health conditions. However, the scarcity of EEG data severely restricts the performance of EEG classification networks, and generative model-based data augmentation methods emerging as potential solutions to overcome this challenge. There are two problems with existing such methods: (1) The quality of the generated EEG signals is not high. (2) The enhancement of EEG classification networks is not effective. In this paper, we propose a Transformer-based denoising diffusion probabilistic model and a generated data-based data augmentation method to address the above two problems. For the characteristics of EEG signals, we propose a constant-factor scaling method to preprocess the signals, which reduces the loss of information. We incorporated Multi-Scale Convolution and Dynamic Fourier Spectrum Information modules into the model, improving the stability of the training process and the quality of the generated data. The proposed augmentation method randomly reassemble the generated data with original data in the time-domain to obtain vicinal data, which improves the model performance by minimizing the empirical risk and the vicinal risk. We experiment the proposed augmentation method on five EEG datasets for four tasks and observe significant accuracy performance improvements: 14.00% on the Bonn dataset; 25.83% on the New Delhi epilepsy dataset; 4.98% on the SleepEDF-20 dataset; 9.42% on the FACED dataset; 2.5% on the Shu dataset. We intend to make the code of our method publicly accessible shortly
EEGMamba: Bidirectional State Space Models with Mixture of Experts for EEG Classification
Jul 20, 2024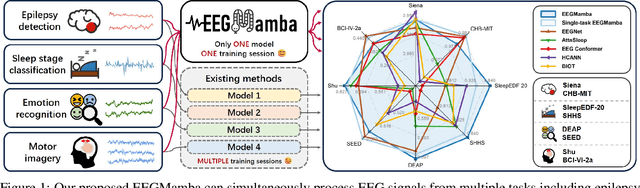
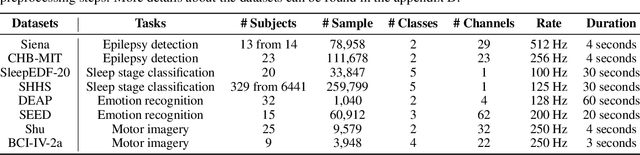
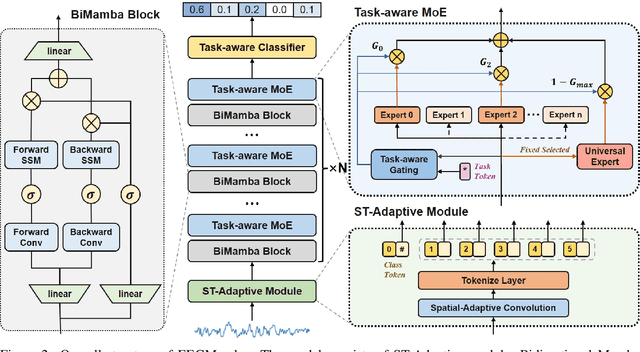
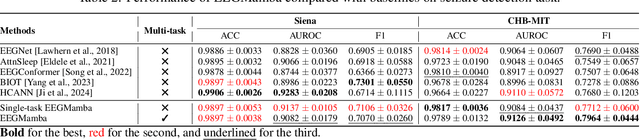
In recent years, with the development of deep learning, electroencephalogram (EEG) classification networks have achieved certain progress. Transformer-based models can perform well in capturing long-term dependencies in EEG signals. However, their quadratic computational complexity leads to significant computational overhead. Moreover, most EEG classification models are only suitable for single tasks, showing poor generalization capabilities across different tasks and further unable to handle EEG data from various tasks simultaneously due to variations in signal length and the number of channels. In this paper, we introduce a universal EEG classification network named EEGMamba, which seamlessly integrates the Spatio-Temporal-Adaptive (ST-Adaptive) module, Bidirectional Mamba, and Mixture of Experts (MoE) into a unified framework for multiple tasks. The proposed ST-Adaptive module performs unified feature extraction on EEG signals of different lengths and channel counts through spatio-adaptive convolution and incorporates a class token to achieve temporal-adaptability. Moreover, we design a bidirectional Mamba particularly suitable for EEG signals for further feature extraction, balancing high accuracy and fast inference speed in processing long EEG signals. In order to better process EEG data for different tasks, we introduce Task-aware MoE with a universal expert, achieving the capture of both differences and commonalities between EEG data from different tasks. We test our model on eight publicly available EEG datasets, and experimental results demonstrate its superior performance in four types of tasks: seizure detection, emotion recognition, sleep stage classification, and motor imagery. The code is set to be released soon.
Deep Learning-Based Residual Useful Lifetime Prediction for Assets with Uncertain Failure Modes
May 09, 2024Industrial prognostics focuses on utilizing degradation signals to forecast and continually update the residual useful life of complex engineering systems. However, existing prognostic models for systems with multiple failure modes face several challenges in real-world applications, including overlapping degradation signals from multiple components, the presence of unlabeled historical data, and the similarity of signals across different failure modes. To tackle these issues, this research introduces two prognostic models that integrate the mixture (log)-location-scale distribution with deep learning. This integration facilitates the modeling of overlapping degradation signals, eliminates the need for explicit failure mode identification, and utilizes deep learning to capture complex nonlinear relationships between degradation signals and residual useful lifetimes. Numerical studies validate the superior performance of these proposed models compared to existing methods.
Federated Multilinear Principal Component Analysis with Applications in Prognostics
Dec 11, 2023



Multilinear Principal Component Analysis (MPCA) is a widely utilized method for the dimension reduction of tensor data. However, the integration of MPCA into federated learning remains unexplored in existing research. To tackle this gap, this article proposes a Federated Multilinear Principal Component Analysis (FMPCA) method, which enables multiple users to collaboratively reduce the dimension of their tensor data while keeping each user's data local and confidential. The proposed FMPCA method is guaranteed to have the same performance as traditional MPCA. An application of the proposed FMPCA in industrial prognostics is also demonstrated. Simulated data and a real-world data set are used to validate the performance of the proposed method.