 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapMoE: Adaptive Sensitivity-based Expert Gating and Management for Efficient MoE Inference
Paper and Code

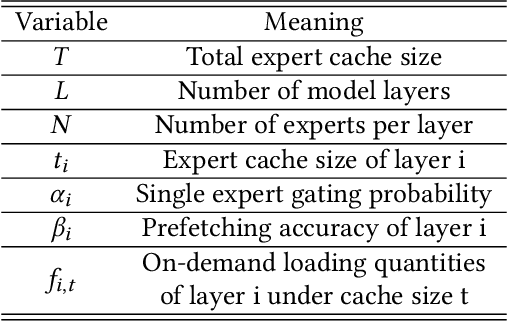
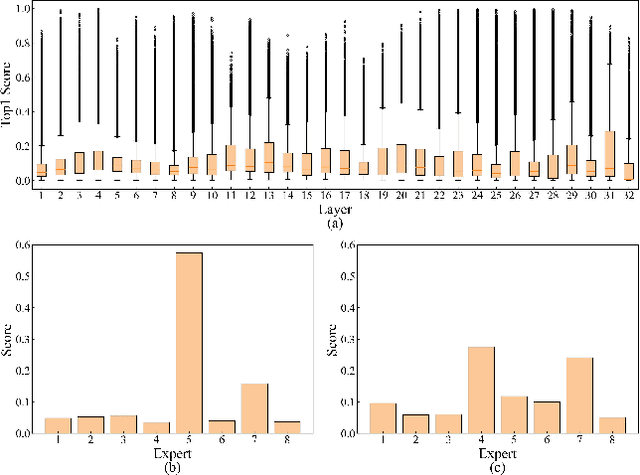
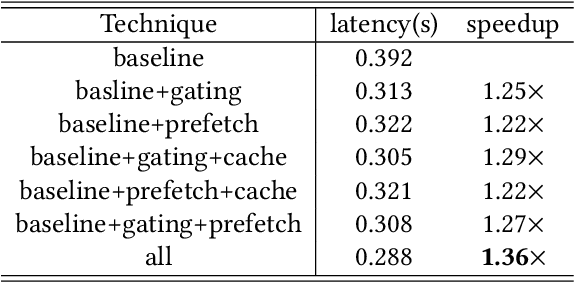
Mixture-of-Experts (MoE) models are designed to enhance the efficiency of large language models (LLMs) without proportionally increasing the computational demands. However, their deployment on edge devices still faces significant challenges due to high on-demand loading overheads from managing sparsely activated experts. This paper introduces AdapMoE, an algorithm-system co-design framework for efficient MoE inference. AdapMoE features adaptive expert gating and management to reduce the on-demand loading overheads. We observe the heterogeneity of experts loading across layers and tokens, based on which we propose a sensitivity-based strategy to adjust the number of activated experts dynamically. Meanwhile, we also integrate advanced prefetching and cache management techniques to further reduce the loading latency. Through comprehensive evaluations on various platforms, we demonstrate AdapMoE consistently outperforms existing techniques, reducing the average number of activated experts by 25% and achieving a 1.35x speedup without accuracy degradation. Code is available at: https://github.com/PKU-SEC-Lab/AdapMoE.