 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images. Building upon the success of the first edition, this challenge attracted a wide range of impressive solutions, all developed and evaluated on our real-world Raindrop Clarity dataset~\cite{jin2024raindrop}. For this edition, we adjust the dataset with 14,139 images for training, 407 images for validation, and 593 images for testing. The primary goal of this challenge is to establish a strong and practical benchmark for the removal of raindrops under various illumination and focus conditions. In total, 168 teams have registered for the competition, and 17 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the Raindrop Clarity dataset, demonstrating the growing progress in this challenging task.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Causal Intervention for Subject-Deconfounded Facial Action Unit Recognition
Apr 17, 2022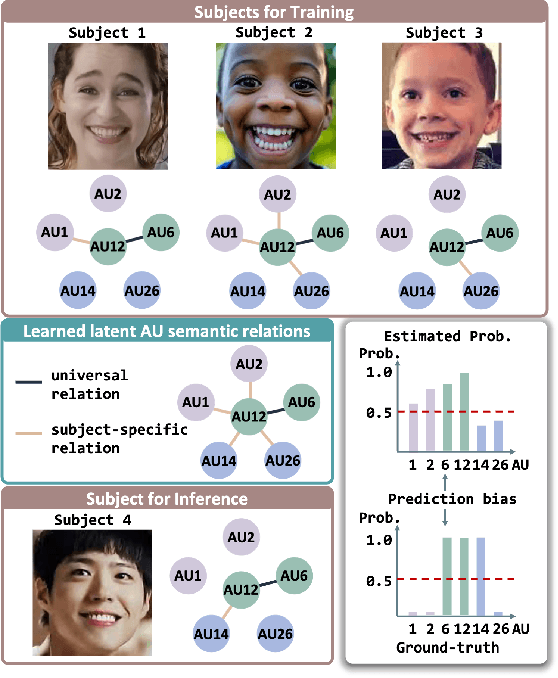
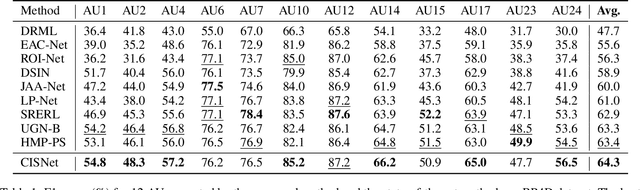
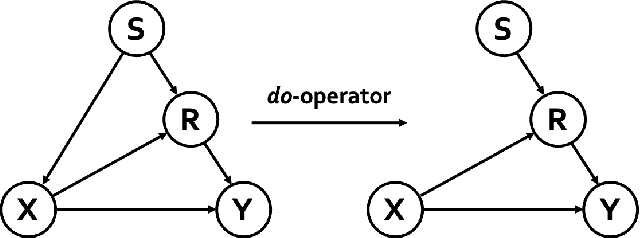
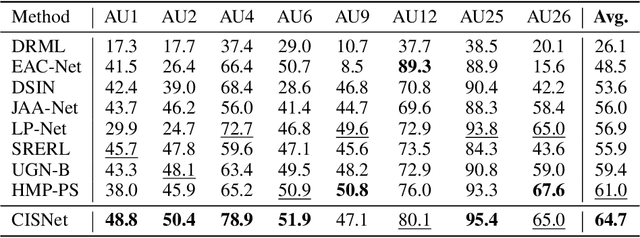
Subject-invariant facial action unit (AU) recognition remains challenging for the reason that the data distribution varies among subjects. In this paper, we propose a causal inference framework for subject-invariant facial action unit recognition. To illustrate the causal effect existing in AU recognition task, we formulate the causalities among facial images, subjects, latent AU semantic relations, and estimated AU occurrence probabilities via a structural causal model. By constructing such a causal diagram, we clarify the causal effect among variables and propose a plug-in causal intervention module, CIS, to deconfound the confounder \emph{Subject} in the causal diagram. Extensive experiments conducted on two commonly used AU benchmark datasets, BP4D and DISFA, show the effectiveness of our CIS, and the model with CIS inserted, CISNet, has achieved state-of-the-art performance.
EventFormer: AU Event Transformer for Facial Action Unit Event Detection
Mar 12, 2022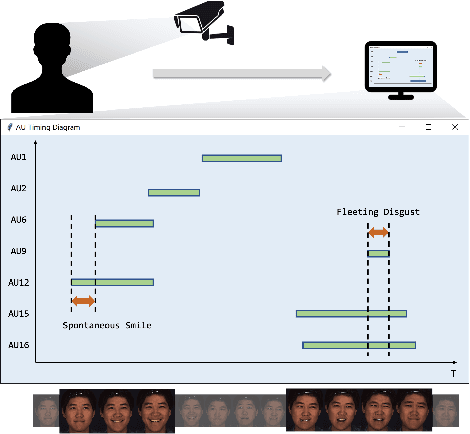
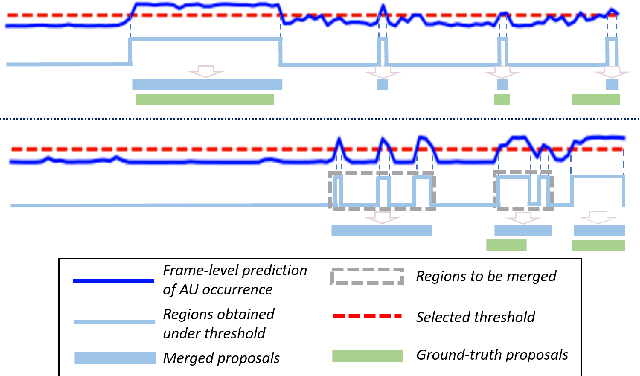
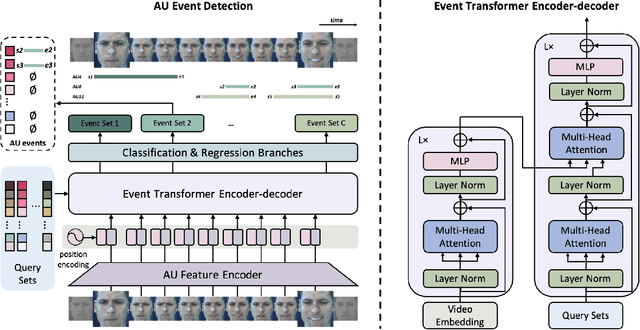
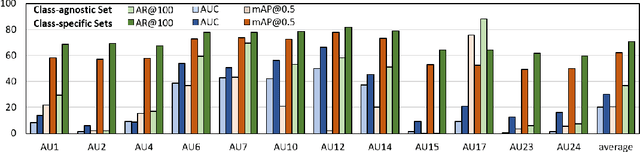
Facial action units (AUs) play an indispensable role in human emotion analysis. We observe that although AU-based high-level emotion analysis is urgently needed by real-world applications, frame-level AU results provided by previous works cannot be directly used for such analysis. Moreover, as AUs are dynamic processes, the utilization of global temporal information is important but has been gravely ignored in the literature. To this end, we propose EventFormer for AU event detection, which is the first work directly detecting AU events from a video sequence by viewing AU event detection as a multiple class-specific sets prediction problem. Extensive experiments conducted on a commonly used AU benchmark dataset, BP4D, show the superiority of EventFormer under suitable metrics.
RAN4IQA: Restorative Adversarial Nets for No-Reference Image Quality Assessment
Dec 14, 2017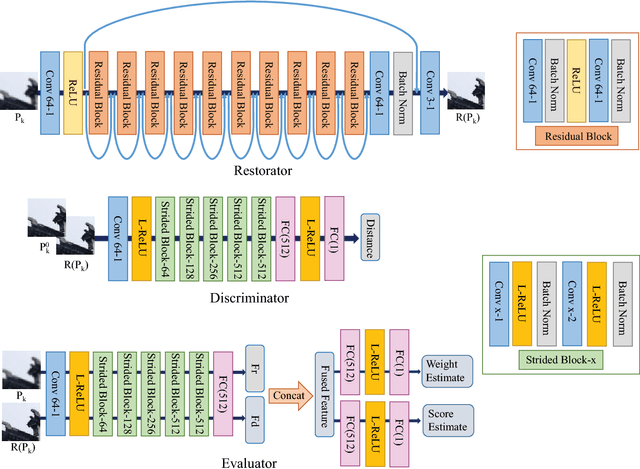
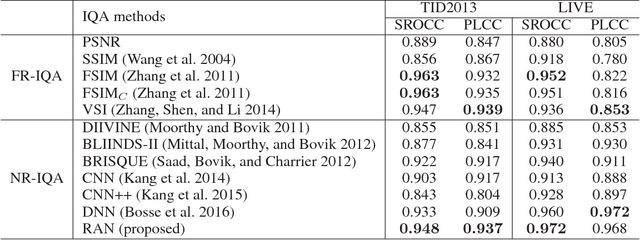
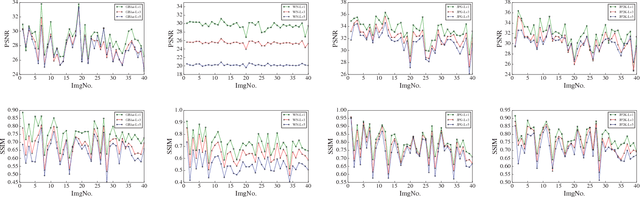
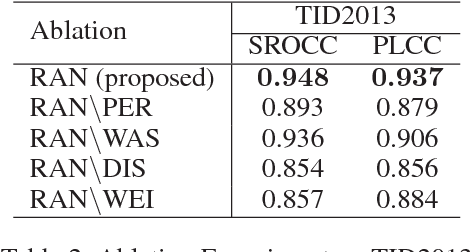
Inspired by the free-energy brain theory, which implies that human visual system (HVS) tends to reduce uncertainty and restore perceptual details upon seeing a distorted image, we propose restorative adversarial net (RAN), a GAN-based model for no-reference image quality assessment (NR-IQA). RAN, which mimics the process of HVS, consists of three components: a restorator, a discriminator and an evaluator. The restorator restores and reconstructs input distorted image patches, while the discriminator distinguishes the reconstructed patches from the pristine distortion-free patches. After restoration, we observe that the perceptual distance between the restored and the distorted patches is monotonic with respect to the distortion level. We further define Gain of Restoration (GoR) based on this phenomenon. The evaluator predicts perceptual score by extracting feature representations from the distorted and restored patches to measure GoR. Eventually, the quality score of an input image is estimated by weighted sum of the patch scores. Experimental results on Waterloo Exploration, LIVE and TID2013 show the effectiveness and generalization ability of RAN compared to the state-of-the-art NR-IQA models.
An Attention-Driven Approach of No-Reference Image Quality Assessment
May 29, 2017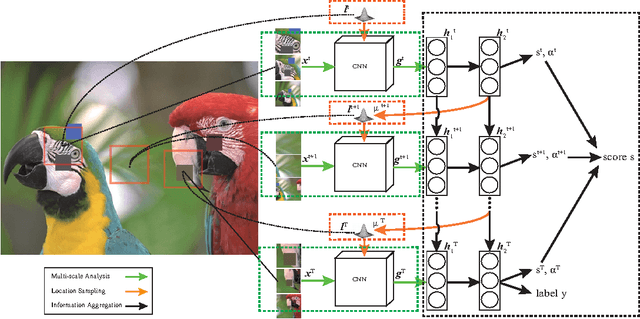
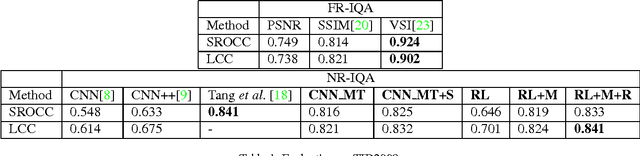
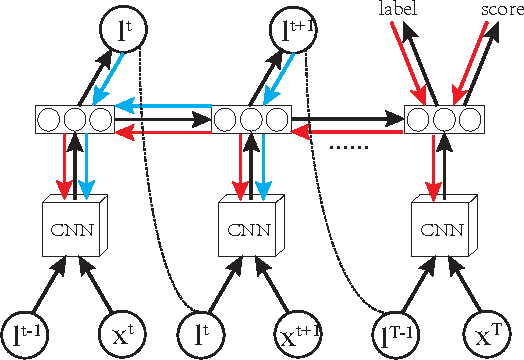
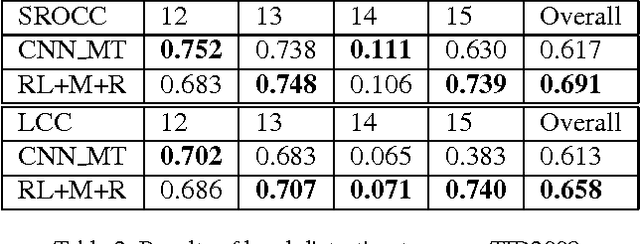
In this paper, we present a novel method of no-reference image quality assessment (NR-IQA), which is to predict the perceptual quality score of a given image without using any reference image. The proposed method harnesses three functions (i) the visual attention mechanism, which affects many aspects of visual perception including image quality assessment, however, is overlooked in the NR-IQA literature. The method assumes that the fixation areas on an image contain key information to the process of IQA. (ii) the robust averaging strategy, which is a means \--- supported by psychology studies \--- to integrating multiple/step-wise evidence to make a final perceptual judgment. (iii) the multi-task learning, which is believed to be an effectual means to shape representation learning and could result in a more generalized model. To exploit the synergy of the three, we consider the NR-IQA as a dynamic perception process, in which the model samples a sequence of "informative" areas and aggregates the information to learn a representation for the tasks of jointly predicting the image quality score and the distortion type. The model learning is implemented by a reinforcement strategy, in which the rewards of both tasks guide the learning of the optimal sampling policy to acquire the "task-informative" image regions so that the predictions can be made accurately and efficiently (in terms of the sampling steps). The reinforcement learning is realized by a deep network with the policy gradient method and trained through back-propagation. In experiments, the model is tested on the TID2008 dataset and it outperforms several state-of-the-art methods. Furthermore, the model is very efficient in the sense that a small number of fixations are used in NR-IQA.