 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention-Driven Approach of No-Reference Image Quality Assessment
Paper and Code
May 29, 2017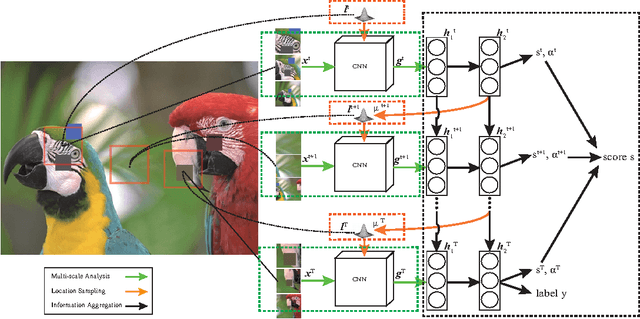
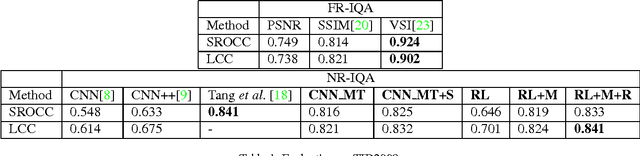
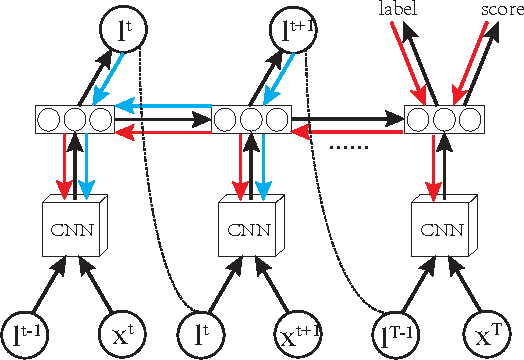
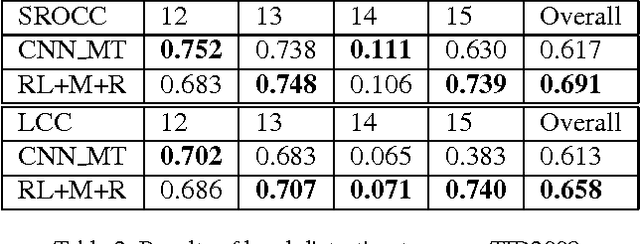
In this paper, we present a novel method of no-reference image quality assessment (NR-IQA), which is to predict the perceptual quality score of a given image without using any reference image. The proposed method harnesses three functions (i) the visual attention mechanism, which affects many aspects of visual perception including image quality assessment, however, is overlooked in the NR-IQA literature. The method assumes that the fixation areas on an image contain key information to the process of IQA. (ii) the robust averaging strategy, which is a means \--- supported by psychology studies \--- to integrating multiple/step-wise evidence to make a final perceptual judgment. (iii) the multi-task learning, which is believed to be an effectual means to shape representation learning and could result in a more generalized model. To exploit the synergy of the three, we consider the NR-IQA as a dynamic perception process, in which the model samples a sequence of "informative" areas and aggregates the information to learn a representation for the tasks of jointly predicting the image quality score and the distortion type. The model learning is implemented by a reinforcement strategy, in which the rewards of both tasks guide the learning of the optimal sampling policy to acquire the "task-informative" image regions so that the predictions can be made accurately and efficiently (in terms of the sampling steps). The reinforcement learning is realized by a deep network with the policy gradient method and trained through back-propagation. In experiments, the model is tested on the TID2008 dataset and it outperforms several state-of-the-art methods. Furthermore, the model is very efficient in the sense that a small number of fixations are used in NR-IQA.