 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX2HDR: HDR Image Generation in a Perceptually Uniform Space
Feb 04, 2026High-dynamic-range (HDR) formats and displays are becoming increasingly prevalent, yet state-of-the-art image generators (e.g., Stable Diffusion and FLUX) typically remain limited to low-dynamic-range (LDR) output due to the lack of large-scale HDR training data. In this work, we show that existing pretrained diffusion models can be easily adapted to HDR generation without retraining from scratch. A key challenge is that HDR images are natively represented in linear RGB, whose intensity and color statistics differ substantially from those of sRGB-encoded LDR images. This gap, however, can be effectively bridged by converting HDR inputs into perceptually uniform encodings (e.g., using PU21 or PQ). Empirically, we find that LDR-pretrained variational autoencoders (VAEs) reconstruct PU21-encoded HDR inputs with fidelity comparable to LDR data, whereas linear RGB inputs cause severe degradations. Motivated by this finding, we describe an efficient adaptation strategy that freezes the VAE and finetunes only the denoiser via low-rank adaptation in a perceptually uniform space. This results in a unified computational method that supports both text-to-HDR synthesis and single-image RAW-to-HDR reconstruction. Experiments demonstrate that our perceptually encoded adaptation consistently improves perceptual fidelity, text-image alignment, and effective dynamic range, relative to previous techniques.
LayerPeeler: Autoregressive Peeling for Layer-wise Image Vectorization
May 29, 2025Image vectorization is a powerful technique that converts raster images into vector graphics, enabling enhanced flexibility and interactivity. However, popular image vectorization tools struggle with occluded regions, producing incomplete or fragmented shapes that hinder editability. While recent advancements have explored rule-based and data-driven layer-wise image vectorization, these methods face limitations in vectorization quality and flexibility. In this paper, we introduce LayerPeeler, a novel layer-wise image vectorization approach that addresses these challenges through a progressive simplification paradigm. The key to LayerPeeler's success lies in its autoregressive peeling strategy: by identifying and removing the topmost non-occluded layers while recovering underlying content, we generate vector graphics with complete paths and coherent layer structures. Our method leverages vision-language models to construct a layer graph that captures occlusion relationships among elements, enabling precise detection and description for non-occluded layers. These descriptive captions are used as editing instructions for a finetuned image diffusion model to remove the identified layers. To ensure accurate removal, we employ localized attention control that precisely guides the model to target regions while faithfully preserving the surrounding content. To support this, we contribute a large-scale dataset specifically designed for layer peeling tasks. Extensive quantitative and qualitative experiments demonstrate that LayerPeeler significantly outperforms existing techniques, producing vectorization results with superior path semantics, geometric regularity, and visual fidelity.
Chat2SVG: Vector Graphics Generation with Large Language Models and Image Diffusion Models
Nov 25, 2024



Scalable Vector Graphics (SVG) has become the de facto standard for vector graphics in digital design, offering resolution independence and precise control over individual elements. Despite their advantages, creating high-quality SVG content remains challenging, as it demands technical expertise with professional editing software and a considerable time investment to craft complex shapes. Recent text-to-SVG generation methods aim to make vector graphics creation more accessible, but they still encounter limitations in shape regularity, generalization ability, and expressiveness. To address these challenges, we introduce Chat2SVG, a hybrid framework that combines the strengths of Large Language Models (LLMs) and image diffusion models for text-to-SVG generation. Our approach first uses an LLM to generate semantically meaningful SVG templates from basic geometric primitives. Guided by image diffusion models, a dual-stage optimization pipeline refines paths in latent space and adjusts point coordinates to enhance geometric complexity. Extensive experiments show that Chat2SVG outperforms existing methods in visual fidelity, path regularity, and semantic alignment. Additionally, our system enables intuitive editing through natural language instructions, making professional vector graphics creation accessible to all users.
Memory Matching is not Enough: Jointly Improving Memory Matching and Decoding for Video Object Segmentation
Sep 22, 2024Memory-based video object segmentation methods model multiple objects over long temporal-spatial spans by establishing memory bank, which achieve the remarkable performance. However, they struggle to overcome the false matching and are prone to lose critical information, resulting in confusion among different objects. In this paper, we propose an effective approach which jointly improving the matching and decoding stages to alleviate the false matching issue.For the memory matching stage, we present a cost aware mechanism that suppresses the slight errors for short-term memory and a shunted cross-scale matching for long-term memory which establish a wide filed matching spaces for various object scales. For the readout decoding stage, we implement a compensatory mechanism aims at recovering the essential information where missing at the matching stage. Our approach achieves the outstanding performance in several popular benchmarks (i.e., DAVIS 2016&2017 Val (92.4%&88.1%), and DAVIS 2017 Test (83.9%)), and achieves 84.8%&84.6% on YouTubeVOS 2018&2019 Val.
AniClipart: Clipart Animation with Text-to-Video Priors
Apr 18, 2024



Clipart, a pre-made graphic art form, offers a convenient and efficient way of illustrating visual content. Traditional workflows to convert static clipart images into motion sequences are laborious and time-consuming, involving numerous intricate steps like rigging, key animation and in-betweening. Recent advancements in text-to-video generation hold great potential in resolving this problem. Nevertheless, direct application of text-to-video generation models often struggles to retain the visual identity of clipart images or generate cartoon-style motions, resulting in unsatisfactory animation outcomes. In this paper, we introduce AniClipart, a system that transforms static clipart images into high-quality motion sequences guided by text-to-video priors. To generate cartoon-style and smooth motion, we first define B\'{e}zier curves over keypoints of the clipart image as a form of motion regularization. We then align the motion trajectories of the keypoints with the provided text prompt by optimizing the Video Score Distillation Sampling (VSDS) loss, which encodes adequate knowledge of natural motion within a pretrained text-to-video diffusion model. With a differentiable As-Rigid-As-Possible shape deformation algorithm, our method can be end-to-end optimized while maintaining deformation rigidity. Experimental results show that the proposed AniClipart consistently outperforms existing image-to-video generation models, in terms of text-video alignment, visual identity preservation, and motion consistency. Furthermore, we showcase the versatility of AniClipart by adapting it to generate a broader array of animation formats, such as layered animation, which allows topological changes.
StyleRetoucher: Generalized Portrait Image Retouching with GAN Priors
Dec 22, 2023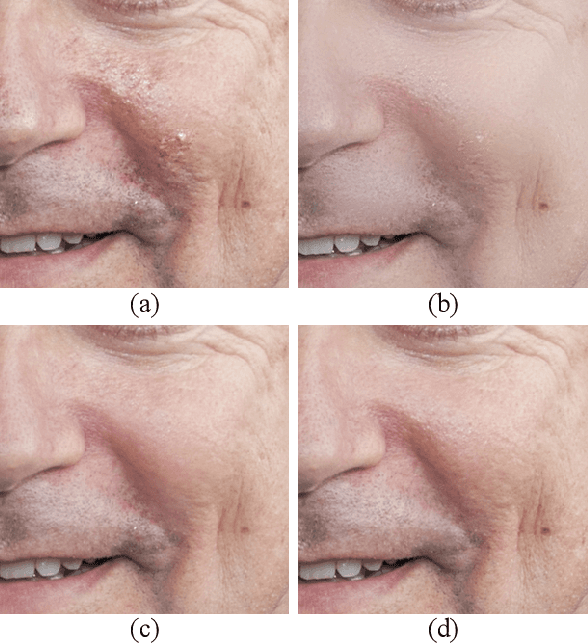
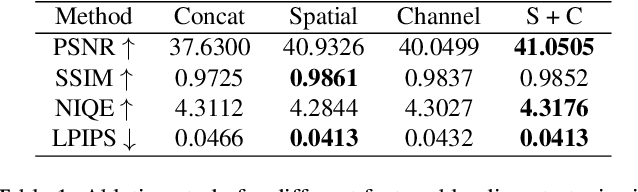
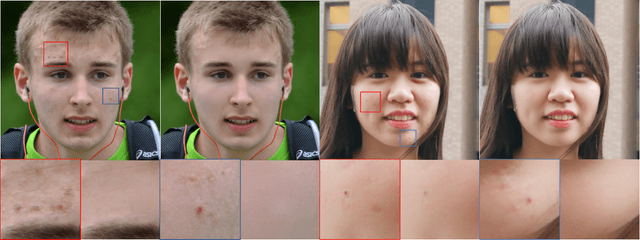
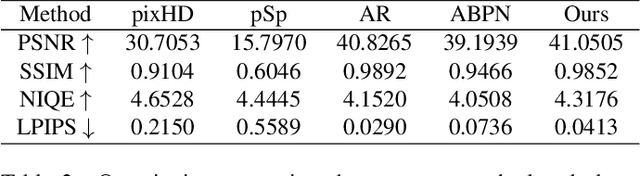
Creating fine-retouched portrait images is tedious and time-consuming even for professional artists. There exist automatic retouching methods, but they either suffer from over-smoothing artifacts or lack generalization ability. To address such issues, we present StyleRetoucher, a novel automatic portrait image retouching framework, leveraging StyleGAN's generation and generalization ability to improve an input portrait image's skin condition while preserving its facial details. Harnessing the priors of pretrained StyleGAN, our method shows superior robustness: a). performing stably with fewer training samples and b). generalizing well on the out-domain data. Moreover, by blending the spatial features of the input image and intermediate features of the StyleGAN layers, our method preserves the input characteristics to the largest extent. We further propose a novel blemish-aware feature selection mechanism to effectively identify and remove the skin blemishes, improving the image skin condition. Qualitative and quantitative evaluations validate the great generalization capability of our method. Further experiments show StyleRetoucher's superior performance to the alternative solutions in the image retouching task. We also conduct a user perceptive study to confirm the superior retouching performance of our method over the existing state-of-the-art alternatives.
IconShop: Text-Based Vector Icon Synthesis with Autoregressive Transformers
Apr 27, 2023
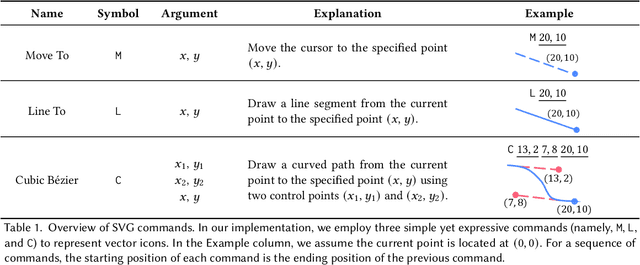
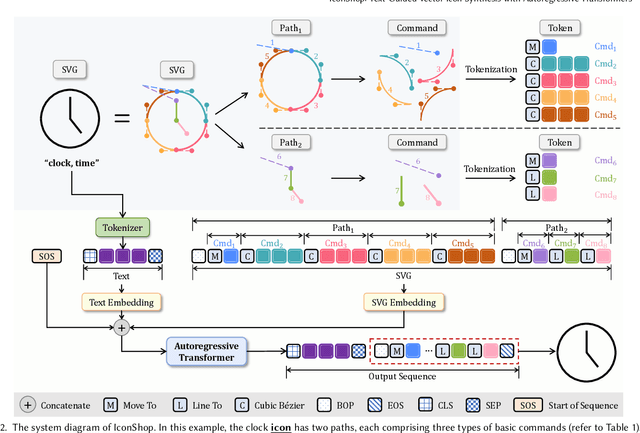
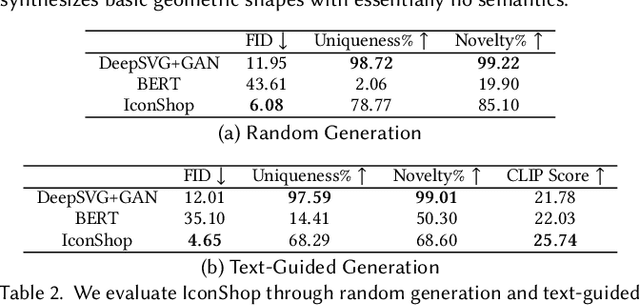
Scalable Vector Graphics (SVG) is a prevalent vector image format with good support for interactivity and animation. Despite such appealing characteristics, it is generally challenging for users to create their own SVG content because of the long learning curve to comprehend SVG grammars or acquaint themselves with professional editing software. Recent progress in text-to-image generation has inspired researchers to explore image-based icon synthesis (i.e., text -> raster image -> vector image) via differential rendering and language-based icon synthesis (i.e., text -> vector image script) via the "zero-shot" capabilities of large language models. However, these methods may suffer from several limitations regarding generation quality, diversity, flexibility, and speed. In this paper, we introduce IconShop, a text-guided vector icon synthesis method using an autoregressive transformer. The key to success of our approach is to sequentialize and tokenize the SVG paths (and textual descriptions) into a uniquely decodable command sequence. With such a single sequence as input, we are able to fully exploit the sequence learning power of autoregressive transformers, while enabling various icon synthesis and manipulation tasks. Through standard training to predict the next token on a large-scale icon dataset accompanied by textural descriptions, the proposed IconShop consistently exhibits better icon synthesis performance than existing image-based and language-based methods both quantitatively (using the FID and CLIP score) and qualitatively (through visual inspection). Meanwhile, we observe a dramatic improvement in generation diversity, which is supported by objective measures (Uniqueness and Novelty). More importantly, we demonstrate the flexibility of IconShop with two novel icon manipulation tasks - text-guided icon infilling, and text-combined icon synthesis.
DifferSketching: How Differently Do People Sketch 3D Objects?
Sep 19, 2022
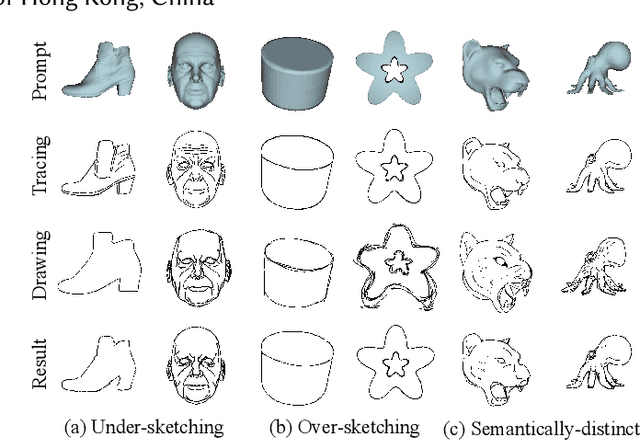

Multiple sketch datasets have been proposed to understand how people draw 3D objects. However, such datasets are often of small scale and cover a small set of objects or categories. In addition, these datasets contain freehand sketches mostly from expert users, making it difficult to compare the drawings by expert and novice users, while such comparisons are critical in informing more effective sketch-based interfaces for either user groups. These observations motivate us to analyze how differently people with and without adequate drawing skills sketch 3D objects. We invited 70 novice users and 38 expert users to sketch 136 3D objects, which were presented as 362 images rendered from multiple views. This leads to a new dataset of 3,620 freehand multi-view sketches, which are registered with their corresponding 3D objects under certain views. Our dataset is an order of magnitude larger than the existing datasets. We analyze the collected data at three levels, i.e., sketch-level, stroke-level, and pixel-level, under both spatial and temporal characteristics, and within and across groups of creators. We found that the drawings by professionals and novices show significant differences at stroke-level, both intrinsically and extrinsically. We demonstrate the usefulness of our dataset in two applications: (i) freehand-style sketch synthesis, and (ii) posing it as a potential benchmark for sketch-based 3D reconstruction. Our dataset and code are available at https://chufengxiao.github.io/DifferSketching/.
DrawingInStyles: Portrait Image Generation and Editing with Spatially Conditioned StyleGAN
Mar 05, 2022
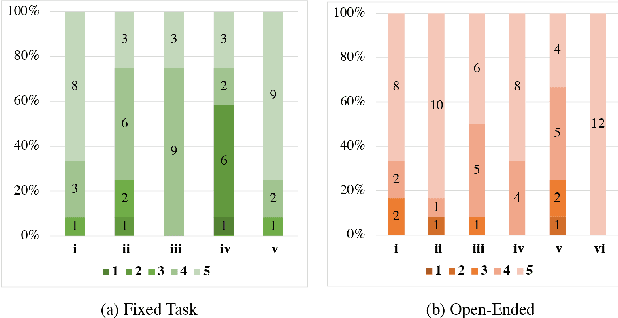

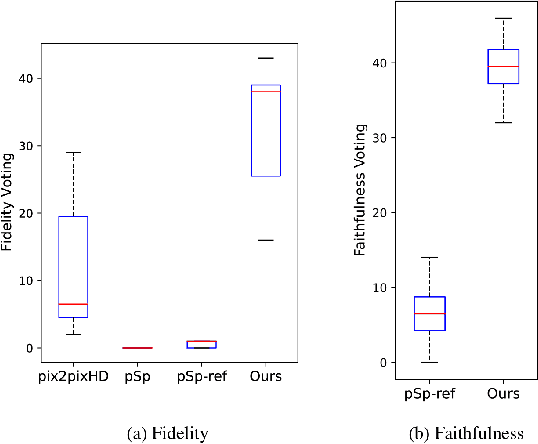
The research topic of sketch-to-portrait generation has witnessed a boost of progress with deep learning techniques. The recently proposed StyleGAN architectures achieve state-of-the-art generation ability but the original StyleGAN is not friendly for sketch-based creation due to its unconditional generation nature. To address this issue, we propose a direct conditioning strategy to better preserve the spatial information under the StyleGAN framework. Specifically, we introduce Spatially Conditioned StyleGAN (SC-StyleGAN for short), which explicitly injects spatial constraints to the original StyleGAN generation process. We explore two input modalities, sketches and semantic maps, which together allow users to express desired generation results more precisely and easily. Based on SC-StyleGAN, we present DrawingInStyles, a novel drawing interface for non-professional users to easily produce high-quality, photo-realistic face images with precise control, either from scratch or editing existing ones. Qualitative and quantitative evaluations show the superior generation ability of our method to existing and alternative solutions. The usability and expressiveness of our system are confirmed by a user study.
Deep Generation of Face Images from Sketches
Jun 05, 2020
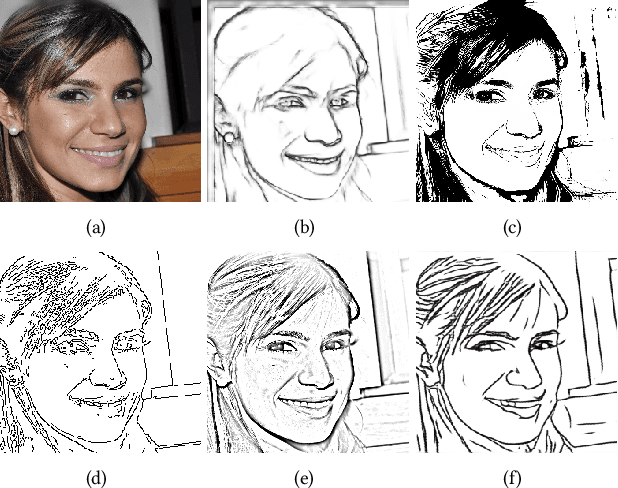
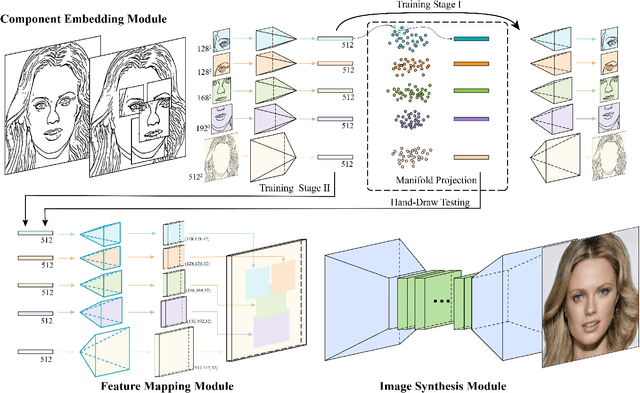

Recent deep image-to-image translation techniques allow fast generation of face images from freehand sketches. However, existing solutions tend to overfit to sketches, thus requiring professional sketches or even edge maps as input. To address this issue, our key idea is to implicitly model the shape space of plausible face images and synthesize a face image in this space to approximate an input sketch. We take a local-to-global approach. We first learn feature embeddings of key face components, and push corresponding parts of input sketches towards underlying component manifolds defined by the feature vectors of face component samples. We also propose another deep neural network to learn the mapping from the embedded component features to realistic images with multi-channel feature maps as intermediate results to improve the information flow. Our method essentially uses input sketches as soft constraints and is thus able to produce high-quality face images even from rough and/or incomplete sketches. Our tool is easy to use even for non-artists, while still supporting fine-grained control of shape details. Both qualitative and quantitative evaluations show the superior generation ability of our system to existing and alternative solutions. The usability and expressiveness of our system are confirmed by a user study.