 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Cognitive Task Generation for In-Situ Evaluation of Embodied Agents
Feb 05, 2026As general intelligent agents are poised for widespread deployment in diverse households, evaluation tailored to each unique unseen 3D environment has become a critical prerequisite. However, existing benchmarks suffer from severe data contamination and a lack of scene specificity, inadequate for assessing agent capabilities in unseen settings. To address this, we propose a dynamic in-situ task generation method for unseen environments inspired by human cognition. We define tasks through a structured graph representation and construct a two-stage interaction-evolution task generation system for embodied agents (TEA). In the interaction stage, the agent actively interacts with the environment, creating a loop between task execution and generation that allows for continuous task generation. In the evolution stage, task graph modeling allows us to recombine and reuse existing tasks to generate new ones without external data. Experiments across 10 unseen scenes demonstrate that TEA automatically generated 87,876 tasks in two cycles, which human verification confirmed to be physically reasonable and encompassing essential daily cognitive capabilities. Benchmarking SOTA models against humans on our in-situ tasks reveals that models, despite excelling on public benchmarks, perform surprisingly poorly on basic perception tasks, severely lack 3D interaction awareness and show high sensitivity to task types in reasoning. These sobering findings highlight the necessity of in-situ evaluation before deploying agents into real-world human environments.
R^3-VQA: "Read the Room" by Video Social Reasoning
May 07, 2025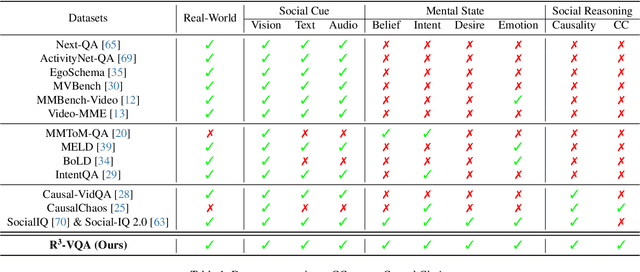
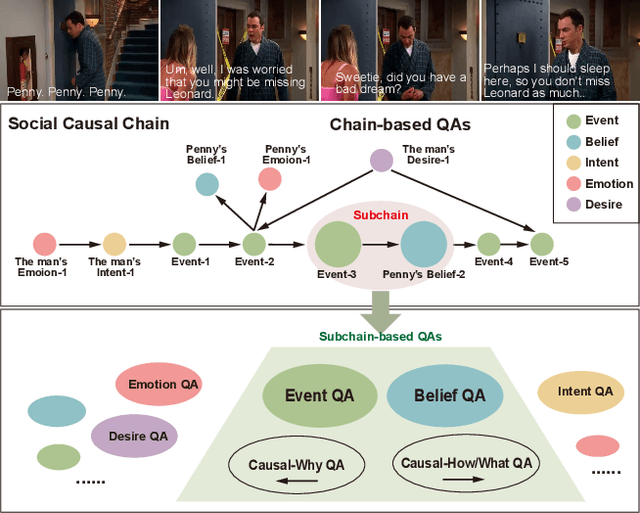
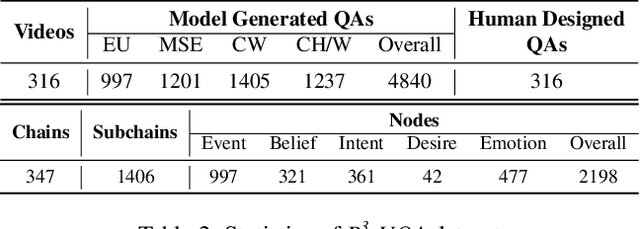

"Read the room" is a significant social reasoning capability in human daily life. Humans can infer others' mental states from subtle social cues. Previous social reasoning tasks and datasets lack complexity (e.g., simple scenes, basic interactions, incomplete mental state variables, single-step reasoning, etc.) and fall far short of the challenges present in real-life social interactions. In this paper, we contribute a valuable, high-quality, and comprehensive video dataset named R^3-VQA with precise and fine-grained annotations of social events and mental states (i.e., belief, intent, desire, and emotion) as well as corresponding social causal chains in complex social scenarios. Moreover, we include human-annotated and model-generated QAs. Our task R^3-VQA includes three aspects: Social Event Understanding, Mental State Estimation, and Social Causal Reasoning. As a benchmark, we comprehensively evaluate the social reasoning capabilities and consistencies of current state-of-the-art large vision-language models (LVLMs). Comprehensive experiments show that (i) LVLMs are still far from human-level consistent social reasoning in complex social scenarios; (ii) Theory of Mind (ToM) prompting can help LVLMs perform better on social reasoning tasks. We provide some of our dataset and codes in supplementary material and will release our full dataset and codes upon acceptance.
Multi-Grained Compositional Visual Clue Learning for Image Intent Recognition
Apr 25, 2025



In an era where social media platforms abound, individuals frequently share images that offer insights into their intents and interests, impacting individual life quality and societal stability. Traditional computer vision tasks, such as object detection and semantic segmentation, focus on concrete visual representations, while intent recognition relies more on implicit visual clues. This poses challenges due to the wide variation and subjectivity of such clues, compounded by the problem of intra-class variety in conveying abstract concepts, e.g. "enjoy life". Existing methods seek to solve the problem by manually designing representative features or building prototypes for each class from global features. However, these methods still struggle to deal with the large visual diversity of each intent category. In this paper, we introduce a novel approach named Multi-grained Compositional visual Clue Learning (MCCL) to address these challenges for image intent recognition. Our method leverages the systematic compositionality of human cognition by breaking down intent recognition into visual clue composition and integrating multi-grained features. We adopt class-specific prototypes to alleviate data imbalance. We treat intent recognition as a multi-label classification problem, using a graph convolutional network to infuse prior knowledge through label embedding correlations. Demonstrated by a state-of-the-art performance on the Intentonomy and MDID datasets, our approach advances the accuracy of existing methods while also possessing good interpretability. Our work provides an attempt for future explorations in understanding complex and miscellaneous forms of human expression.
ToM-RL: Reinforcement Learning Unlocks Theory of Mind in Small LLMs
Apr 02, 2025Recent advancements in rule-based reinforcement learning (RL), applied during the post-training phase of large language models (LLMs), have significantly enhanced their capabilities in structured reasoning tasks such as mathematics and logical inference. However, the effectiveness of RL in social reasoning, particularly in Theory of Mind (ToM), the ability to infer others' mental states, remains largely unexplored. In this study, we demonstrate that RL methods effectively unlock ToM reasoning capabilities even in small-scale LLMs (0.5B to 7B parameters). Using a modest dataset comprising 3200 questions across diverse scenarios, our RL-trained 7B model achieves 84.50\% accuracy on the Hi-ToM benchmark, surpassing models like GPT-4o and DeepSeek-v3 despite significantly fewer parameters. While smaller models ($\leq$3B parameters) suffer from reasoning collapse, larger models (7B parameters) maintain stable performance through consistent belief tracking. Additionally, our RL-based models demonstrate robust generalization to higher-order, out-of-distribution ToM problems, novel textual presentations, and previously unseen datasets. These findings highlight RL's potential to enhance social cognitive reasoning, bridging the gap between structured problem-solving and nuanced social inference in LLMs.
Evaluating and Modeling Social Intelligence: A Comparative Study of Human and AI Capabilities
May 20, 2024



Facing the current debate on whether Large Language Models (LLMs) attain near-human intelligence levels (Mitchell & Krakauer, 2023; Bubeck et al., 2023; Kosinski, 2023; Shiffrin & Mitchell, 2023; Ullman, 2023), the current study introduces a benchmark for evaluating social intelligence, one of the most distinctive aspects of human cognition. We developed a comprehensive theoretical framework for social dynamics and introduced two evaluation tasks: Inverse Reasoning (IR) and Inverse Inverse Planning (IIP). Our approach also encompassed a computational model based on recursive Bayesian inference, adept at elucidating diverse human behavioral patterns. Extensive experiments and detailed analyses revealed that humans surpassed the latest GPT models in overall performance, zero-shot learning, one-shot generalization, and adaptability to multi-modalities. Notably, GPT models demonstrated social intelligence only at the most basic order (order = 0), in stark contrast to human social intelligence (order >= 2). Further examination indicated a propensity of LLMs to rely on pattern recognition for shortcuts, casting doubt on their possession of authentic human-level social intelligence. Our codes, dataset, appendix and human data are released at https://github.com/bigai-ai/Evaluate-n-Model-Social-Intelligence.
Smart Help: Strategic Opponent Modeling for Proactive and Adaptive Robot Assistance in Households
Apr 13, 2024



Despite the significant demand for assistive technology among vulnerable groups (e.g., the elderly, children, and the disabled) in daily tasks, research into advanced AI-driven assistive solutions that genuinely accommodate their diverse needs remains sparse. Traditional human-machine interaction tasks often require machines to simply help without nuanced consideration of human abilities and feelings, such as their opportunity for practice and learning, sense of self-improvement, and self-esteem. Addressing this gap, we define a pivotal and novel challenge Smart Help, which aims to provide proactive yet adaptive support to human agents with diverse disabilities and dynamic goals in various tasks and environments. To establish this challenge, we leverage AI2-THOR to build a new interactive 3D realistic household environment for the Smart Help task. We introduce an innovative opponent modeling module that provides a nuanced understanding of the main agent's capabilities and goals, in order to optimize the assisting agent's helping policy. Rigorous experiments validate the efficacy of our model components and show the superiority of our holistic approach against established baselines. Our findings illustrate the potential of AI-imbued assistive robots in improving the well-being of vulnerable groups.
Learning Concept-Based Visual Causal Transition and Symbolic Reasoning for Visual Planning
Oct 05, 2023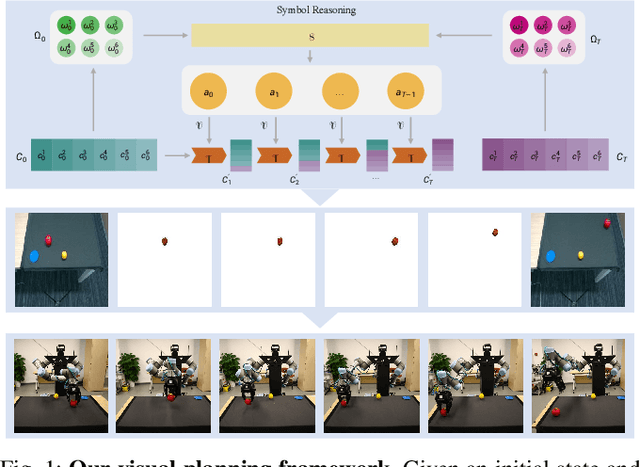
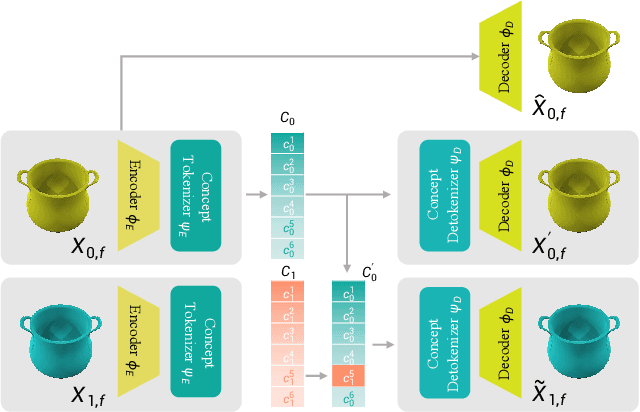


Visual planning simulates how humans make decisions to achieve desired goals in the form of searching for visual causal transitions between an initial visual state and a final visual goal state. It has become increasingly important in egocentric vision with its advantages in guiding agents to perform daily tasks in complex environments. In this paper, we propose an interpretable and generalizable visual planning framework consisting of i) a novel Substitution-based Concept Learner (SCL) that abstracts visual inputs into disentangled concept representations, ii) symbol abstraction and reasoning that performs task planning via the self-learned symbols, and iii) a Visual Causal Transition model (ViCT) that grounds visual causal transitions to semantically similar real-world actions. Given an initial state, we perform goal-conditioned visual planning with a symbolic reasoning method fueled by the learned representations and causal transitions to reach the goal state. To verify the effectiveness of the proposed model, we collect a large-scale visual planning dataset based on AI2-THOR, dubbed as CCTP. Extensive experiments on this challenging dataset demonstrate the superior performance of our method in visual task planning. Empirically, we show that our framework can generalize to unseen task trajectories and unseen object categories.
Emergent Graphical Conventions in a Visual Communication Game
Dec 03, 2021
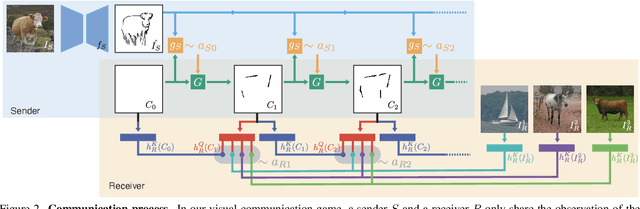
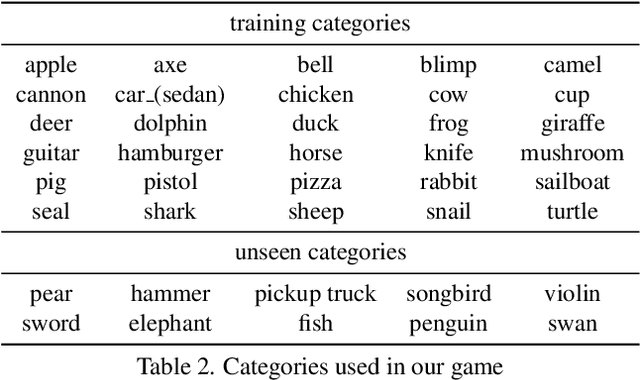
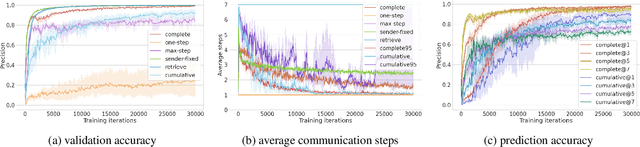
Humans communicate with graphical sketches apart from symbolic languages. While recent studies of emergent communication primarily focus on symbolic languages, their settings overlook the graphical sketches existing in human communication; they do not account for the evolution process through which symbolic sign systems emerge in the trade-off between iconicity and symbolicity. In this work, we take the very first step to model and simulate such an evolution process via two neural agents playing a visual communication game; the sender communicates with the receiver by sketching on a canvas. We devise a novel reinforcement learning method such that agents are evolved jointly towards successful communication and abstract graphical conventions. To inspect the emerged conventions, we carefully define three key properties -- iconicity, symbolicity, and semanticity -- and design evaluation methods accordingly. Our experimental results under different controls are consistent with the observation in studies of human graphical conventions. Of note, we find that evolved sketches can preserve the continuum of semantics under proper environmental pressures. More interestingly, co-evolved agents can switch between conventionalized and iconic communication based on their familiarity with referents. We hope the present research can pave the path for studying emergent communication with the unexplored modality of sketches.
Learning Triadic Belief Dynamics in Nonverbal Communication from Videos
Apr 07, 2021

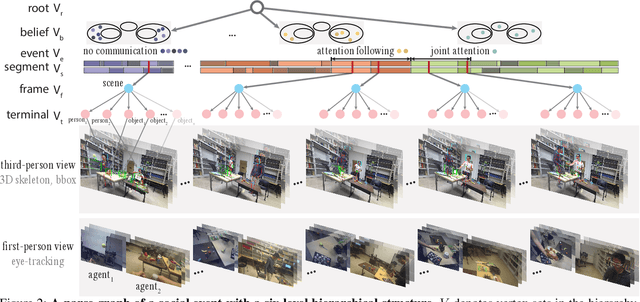

Humans possess a unique social cognition capability; nonverbal communication can convey rich social information among agents. In contrast, such crucial social characteristics are mostly missing in the existing scene understanding literature. In this paper, we incorporate different nonverbal communication cues (e.g., gaze, human poses, and gestures) to represent, model, learn, and infer agents' mental states from pure visual inputs. Crucially, such a mental representation takes the agent's belief into account so that it represents what the true world state is and infers the beliefs in each agent's mental state, which may differ from the true world states. By aggregating different beliefs and true world states, our model essentially forms "five minds" during the interactions between two agents. This "five minds" model differs from prior works that infer beliefs in an infinite recursion; instead, agents' beliefs are converged into a "common mind". Based on this representation, we further devise a hierarchical energy-based model that jointly tracks and predicts all five minds. From this new perspective, a social event is interpreted by a series of nonverbal communication and belief dynamics, which transcends the classic keyframe video summary. In the experiments, we demonstrate that using such a social account provides a better video summary on videos with rich social interactions compared with state-of-the-art keyframe video summary methods.
Joint Inference of States, Robot Knowledge, and Human Beliefs
Apr 25, 2020
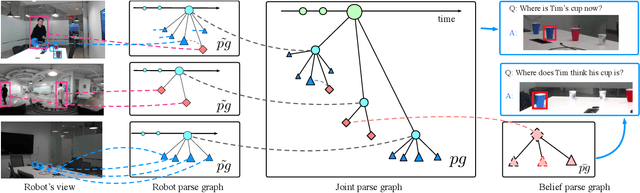


Aiming to understand how human (false-)belief--a core socio-cognitive ability--would affect human interactions with robots, this paper proposes to adopt a graphical model to unify the representation of object states, robot knowledge, and human (false-)beliefs. Specifically, a parse graph (pg) is learned from a single-view spatiotemporal parsing by aggregating various object states along the time; such a learned representation is accumulated as the robot's knowledge. An inference algorithm is derived to fuse individual pg from all robots across multi-views into a joint pg, which affords more effective reasoning and inference capability to overcome the errors originated from a single view. In the experiments, through the joint inference over pg-s, the system correctly recognizes human (false-)belief in various settings and achieves better cross-view accuracy on a challenging small object tracking dataset.