 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindDial: Belief Dynamics Tracking with Theory-of-Mind Modeling for Situated Neural Dialogue Generation
Jul 03, 2023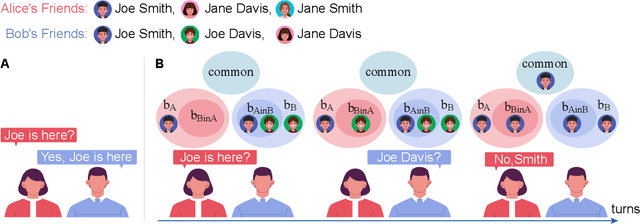
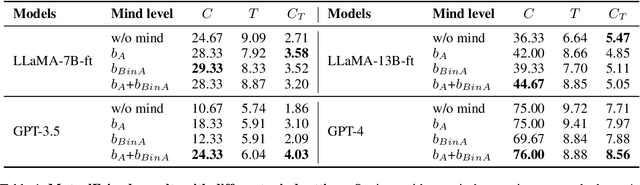

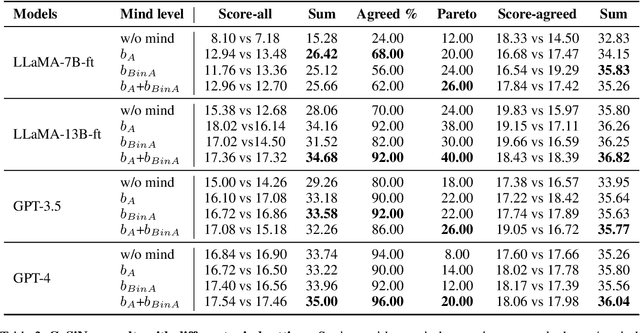
Humans talk in free-form while negotiating the expressed meanings or common ground. Despite the impressive conversational abilities of the large generative language models, they do not consider the individual differences in contextual understanding in a shared situated environment. In this work, we propose MindDial, a novel conversational framework that can generate situated free-form responses to negotiate common ground. We design an explicit mind module that can track three-level beliefs -- the speaker's belief, the speaker's prediction of the listener's belief, and the common belief based on the gap between the first two. Then the speaking act classification head will decide to continue to talk, end this turn, or take task-related action. We augment a common ground alignment dataset MutualFriend with belief dynamics annotation, of which the goal is to find a single mutual friend based on the free chat between two agents. Experiments show that our model with mental state modeling can resemble human responses when aligning common ground meanwhile mimic the natural human conversation flow. The ablation study further validates the third-level common belief can aggregate information of the first and second-order beliefs and align common ground more efficiently.
Emergent Graphical Conventions in a Visual Communication Game
Dec 03, 2021
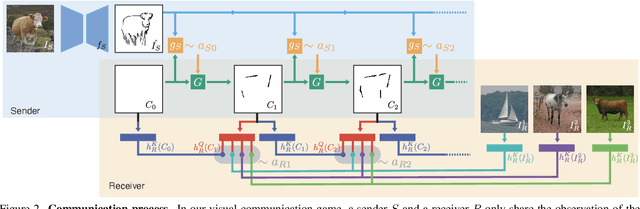
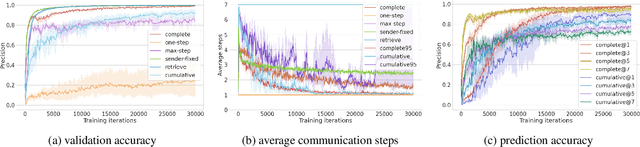
Humans communicate with graphical sketches apart from symbolic languages. While recent studies of emergent communication primarily focus on symbolic languages, their settings overlook the graphical sketches existing in human communication; they do not account for the evolution process through which symbolic sign systems emerge in the trade-off between iconicity and symbolicity. In this work, we take the very first step to model and simulate such an evolution process via two neural agents playing a visual communication game; the sender communicates with the receiver by sketching on a canvas. We devise a novel reinforcement learning method such that agents are evolved jointly towards successful communication and abstract graphical conventions. To inspect the emerged conventions, we carefully define three key properties -- iconicity, symbolicity, and semanticity -- and design evaluation methods accordingly. Our experimental results under different controls are consistent with the observation in studies of human graphical conventions. Of note, we find that evolved sketches can preserve the continuum of semantics under proper environmental pressures. More interestingly, co-evolved agents can switch between conventionalized and iconic communication based on their familiarity with referents. We hope the present research can pave the path for studying emergent communication with the unexplored modality of sketches.
Learning Triadic Belief Dynamics in Nonverbal Communication from Videos
Apr 07, 2021

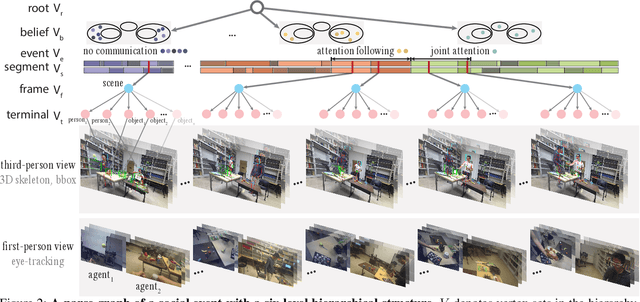

Humans possess a unique social cognition capability; nonverbal communication can convey rich social information among agents. In contrast, such crucial social characteristics are mostly missing in the existing scene understanding literature. In this paper, we incorporate different nonverbal communication cues (e.g., gaze, human poses, and gestures) to represent, model, learn, and infer agents' mental states from pure visual inputs. Crucially, such a mental representation takes the agent's belief into account so that it represents what the true world state is and infers the beliefs in each agent's mental state, which may differ from the true world states. By aggregating different beliefs and true world states, our model essentially forms "five minds" during the interactions between two agents. This "five minds" model differs from prior works that infer beliefs in an infinite recursion; instead, agents' beliefs are converged into a "common mind". Based on this representation, we further devise a hierarchical energy-based model that jointly tracks and predicts all five minds. From this new perspective, a social event is interpreted by a series of nonverbal communication and belief dynamics, which transcends the classic keyframe video summary. In the experiments, we demonstrate that using such a social account provides a better video summary on videos with rich social interactions compared with state-of-the-art keyframe video summary methods.
Human-Robot Interaction in a Shared Augmented Reality Workspace
Jul 24, 2020



We design and develop a new shared Augmented Reality (AR) workspace for Human-Robot Interaction (HRI), which establishes a bi-directional communication between human agents and robots. In a prototype system, the shared AR workspace enables a shared perception, so that a physical robot not only perceives the virtual elements in its own view but also infers the utility of the human agent--the cost needed to perceive and interact in AR--by sensing the human agent's gaze and pose. Such a new HRI design also affords a shared manipulation, wherein the physical robot can control and alter virtual objects in AR as an active agent; crucially, a robot can proactively interact with human agents, instead of purely passively executing received commands. In experiments, we design a resource collection game that qualitatively demonstrates how a robot perceives, processes, and manipulates in AR and quantitatively evaluates the efficacy of HRI using the shared AR workspace. We further discuss how the system can potentially benefit future HRI studies that are otherwise challenging.