 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Inference of States, Robot Knowledge, and Human Beliefs
Paper and Code
Apr 25, 2020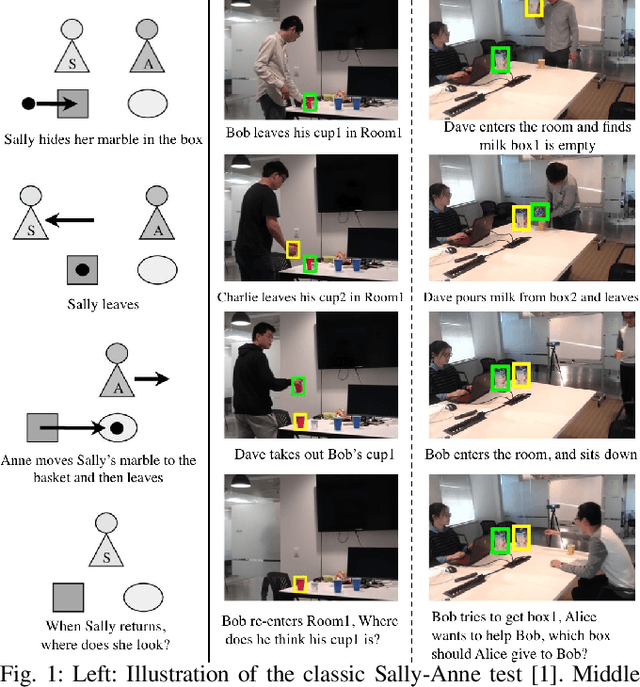
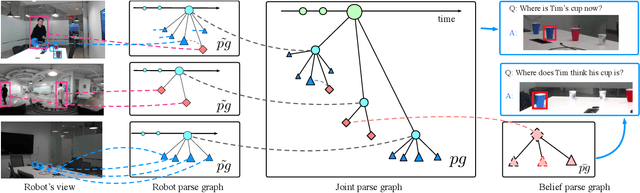


Aiming to understand how human (false-)belief--a core socio-cognitive ability--would affect human interactions with robots, this paper proposes to adopt a graphical model to unify the representation of object states, robot knowledge, and human (false-)beliefs. Specifically, a parse graph (pg) is learned from a single-view spatiotemporal parsing by aggregating various object states along the time; such a learned representation is accumulated as the robot's knowledge. An inference algorithm is derived to fuse individual pg from all robots across multi-views into a joint pg, which affords more effective reasoning and inference capability to overcome the errors originated from a single view. In the experiments, through the joint inference over pg-s, the system correctly recognizes human (false-)belief in various settings and achieves better cross-view accuracy on a challenging small object tracking dataset.