 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Cognitive Task Generation for In-Situ Evaluation of Embodied Agents
Feb 05, 2026As general intelligent agents are poised for widespread deployment in diverse households, evaluation tailored to each unique unseen 3D environment has become a critical prerequisite. However, existing benchmarks suffer from severe data contamination and a lack of scene specificity, inadequate for assessing agent capabilities in unseen settings. To address this, we propose a dynamic in-situ task generation method for unseen environments inspired by human cognition. We define tasks through a structured graph representation and construct a two-stage interaction-evolution task generation system for embodied agents (TEA). In the interaction stage, the agent actively interacts with the environment, creating a loop between task execution and generation that allows for continuous task generation. In the evolution stage, task graph modeling allows us to recombine and reuse existing tasks to generate new ones without external data. Experiments across 10 unseen scenes demonstrate that TEA automatically generated 87,876 tasks in two cycles, which human verification confirmed to be physically reasonable and encompassing essential daily cognitive capabilities. Benchmarking SOTA models against humans on our in-situ tasks reveals that models, despite excelling on public benchmarks, perform surprisingly poorly on basic perception tasks, severely lack 3D interaction awareness and show high sensitivity to task types in reasoning. These sobering findings highlight the necessity of in-situ evaluation before deploying agents into real-world human environments.
TongSIM: A General Platform for Simulating Intelligent Machines
Dec 23, 2025As artificial intelligence (AI) rapidly advances, especially in multimodal large language models (MLLMs), research focus is shifting from single-modality text processing to the more complex domains of multimodal and embodied AI. Embodied intelligence focuses on training agents within realistic simulated environments, leveraging physical interaction and action feedback rather than conventionally labeled datasets. Yet, most existing simulation platforms remain narrowly designed, each tailored to specific tasks. A versatile, general-purpose training environment that can support everything from low-level embodied navigation to high-level composite activities, such as multi-agent social simulation and human-AI collaboration, remains largely unavailable. To bridge this gap, we introduce TongSIM, a high-fidelity, general-purpose platform for training and evaluating embodied agents. TongSIM offers practical advantages by providing over 100 diverse, multi-room indoor scenarios as well as an open-ended, interaction-rich outdoor town simulation, ensuring broad applicability across research needs. Its comprehensive evaluation framework and benchmarks enable precise assessment of agent capabilities, such as perception, cognition, decision-making, human-robot cooperation, and spatial and social reasoning. With features like customized scenes, task-adaptive fidelity, diverse agent types, and dynamic environmental simulation, TongSIM delivers flexibility and scalability for researchers, serving as a unified platform that accelerates training, evaluation, and advancement toward general embodied intelligence.
A simulation-heuristics dual-process model for intuitive physics
Apr 13, 2025The role of mental simulation in human physical reasoning is widely acknowledged, but whether it is employed across scenarios with varying simulation costs and where its boundary lies remains unclear. Using a pouring-marble task, our human study revealed two distinct error patterns when predicting pouring angles, differentiated by simulation time. While mental simulation accurately captured human judgments in simpler scenarios, a linear heuristic model better matched human predictions when simulation time exceeded a certain boundary. Motivated by these observations, we propose a dual-process framework, Simulation-Heuristics Model (SHM), where intuitive physics employs simulation for short-time simulation but switches to heuristics when simulation becomes costly. By integrating computational methods previously viewed as separate into a unified model, SHM quantitatively captures their switching mechanism. The SHM aligns more precisely with human behavior and demonstrates consistent predictive performance across diverse scenarios, advancing our understanding of the adaptive nature of intuitive physical reasoning.
Evaluating and Modeling Social Intelligence: A Comparative Study of Human and AI Capabilities
May 20, 2024Facing the current debate on whether Large Language Models (LLMs) attain near-human intelligence levels (Mitchell & Krakauer, 2023; Bubeck et al., 2023; Kosinski, 2023; Shiffrin & Mitchell, 2023; Ullman, 2023), the current study introduces a benchmark for evaluating social intelligence, one of the most distinctive aspects of human cognition. We developed a comprehensive theoretical framework for social dynamics and introduced two evaluation tasks: Inverse Reasoning (IR) and Inverse Inverse Planning (IIP). Our approach also encompassed a computational model based on recursive Bayesian inference, adept at elucidating diverse human behavioral patterns. Extensive experiments and detailed analyses revealed that humans surpassed the latest GPT models in overall performance, zero-shot learning, one-shot generalization, and adaptability to multi-modalities. Notably, GPT models demonstrated social intelligence only at the most basic order (order = 0), in stark contrast to human social intelligence (order >= 2). Further examination indicated a propensity of LLMs to rely on pattern recognition for shortcuts, casting doubt on their possession of authentic human-level social intelligence. Our codes, dataset, appendix and human data are released at https://github.com/bigai-ai/Evaluate-n-Model-Social-Intelligence.
MEWL: Few-shot multimodal word learning with referential uncertainty
Jun 01, 2023

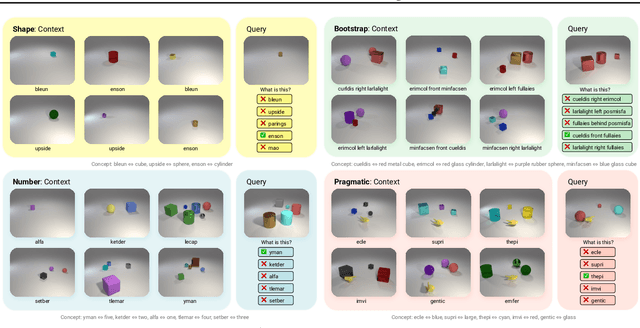
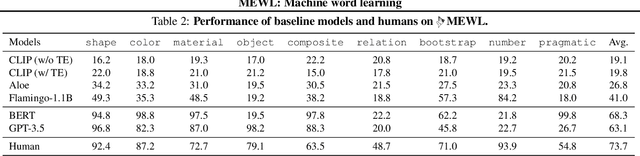
Without explicit feedback, humans can rapidly learn the meaning of words. Children can acquire a new word after just a few passive exposures, a process known as fast mapping. This word learning capability is believed to be the most fundamental building block of multimodal understanding and reasoning. Despite recent advancements in multimodal learning, a systematic and rigorous evaluation is still missing for human-like word learning in machines. To fill in this gap, we introduce the MachinE Word Learning (MEWL) benchmark to assess how machines learn word meaning in grounded visual scenes. MEWL covers human's core cognitive toolkits in word learning: cross-situational reasoning, bootstrapping, and pragmatic learning. Specifically, MEWL is a few-shot benchmark suite consisting of nine tasks for probing various word learning capabilities. These tasks are carefully designed to be aligned with the children's core abilities in word learning and echo the theories in the developmental literature. By evaluating multimodal and unimodal agents' performance with a comparative analysis of human performance, we notice a sharp divergence in human and machine word learning. We further discuss these differences between humans and machines and call for human-like few-shot word learning in machines.