 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Physics-Grounded 4D Dynamics with Neural Gaussian Force Fields
Jan 29, 2026Predicting physical dynamics from raw visual data remains a major challenge in AI. While recent video generation models have achieved impressive visual quality, they still cannot consistently generate physically plausible videos due to a lack of modeling of physical laws. Recent approaches combining 3D Gaussian splatting and physics engines can produce physically plausible videos, but are hindered by high computational costs in both reconstruction and simulation, and often lack robustness in complex real-world scenarios. To address these issues, we introduce Neural Gaussian Force Field (NGFF), an end-to-end neural framework that integrates 3D Gaussian perception with physics-based dynamic modeling to generate interactive, physically realistic 4D videos from multi-view RGB inputs, achieving two orders of magnitude faster than prior Gaussian simulators. To support training, we also present GSCollision, a 4D Gaussian dataset featuring diverse materials, multi-object interactions, and complex scenes, totaling over 640k rendered physical videos (~4 TB). Evaluations on synthetic and real 3D scenarios show NGFF's strong generalization and robustness in physical reasoning, advancing video prediction towards physics-grounded world models.
A simulation-heuristics dual-process model for intuitive physics
Apr 13, 2025The role of mental simulation in human physical reasoning is widely acknowledged, but whether it is employed across scenarios with varying simulation costs and where its boundary lies remains unclear. Using a pouring-marble task, our human study revealed two distinct error patterns when predicting pouring angles, differentiated by simulation time. While mental simulation accurately captured human judgments in simpler scenarios, a linear heuristic model better matched human predictions when simulation time exceeded a certain boundary. Motivated by these observations, we propose a dual-process framework, Simulation-Heuristics Model (SHM), where intuitive physics employs simulation for short-time simulation but switches to heuristics when simulation becomes costly. By integrating computational methods previously viewed as separate into a unified model, SHM quantitatively captures their switching mechanism. The SHM aligns more precisely with human behavior and demonstrates consistent predictive performance across diverse scenarios, advancing our understanding of the adaptive nature of intuitive physical reasoning.
Neural Force Field: Learning Generalized Physical Representation from a Few Examples
Feb 13, 2025



Physical reasoning is a remarkable human ability that enables rapid learning and generalization from limited experience. Current AI models, despite extensive training, still struggle to achieve similar generalization, especially in Out-of-distribution (OOD) settings. This limitation stems from their inability to abstract core physical principles from observations. A key challenge is developing representations that can efficiently learn and generalize physical dynamics from minimal data. Here we present Neural Force Field (NFF) a modeling framework built on Neural Ordinary Differential Equation (NODE) that learns interpretable force field representations which can be efficiently integrated through an Ordinary Differential Equation ( ODE) solver to predict object trajectories. Unlike existing approaches that rely on high-dimensional latent spaces, NFF captures fundamental physical concepts such as gravity, support, and collision in an interpretable manner. Experiments on two challenging physical reasoning tasks demonstrate that NFF, trained with only a few examples, achieves strong generalization to unseen scenarios. This physics-grounded representation enables efficient forward-backward planning and rapid adaptation through interactive refinement. Our work suggests that incorporating physics-inspired representations into learning systems can help bridge the gap between artificial and human physical reasoning capabilities.
I-PHYRE: Interactive Physical Reasoning
Dec 04, 2023



Current evaluation protocols predominantly assess physical reasoning in stationary scenes, creating a gap in evaluating agents' abilities to interact with dynamic events. While contemporary methods allow agents to modify initial scene configurations and observe consequences, they lack the capability to interact with events in real time. To address this, we introduce I-PHYRE, a framework that challenges agents to simultaneously exhibit intuitive physical reasoning, multi-step planning, and in-situ intervention. Here, intuitive physical reasoning refers to a quick, approximate understanding of physics to address complex problems; multi-step denotes the need for extensive sequence planning in I-PHYRE, considering each intervention can significantly alter subsequent choices; and in-situ implies the necessity for timely object manipulation within a scene, where minor timing deviations can result in task failure. We formulate four game splits to scrutinize agents' learning and generalization of essential principles of interactive physical reasoning, fostering learning through interaction with representative scenarios. Our exploration involves three planning strategies and examines several supervised and reinforcement agents' zero-shot generalization proficiency on I-PHYRE. The outcomes highlight a notable gap between existing learning algorithms and human performance, emphasizing the imperative for more research in enhancing agents with interactive physical reasoning capabilities. The environment and baselines will be made publicly available.
On the Learning Mechanisms in Physical Reasoning
Oct 05, 2022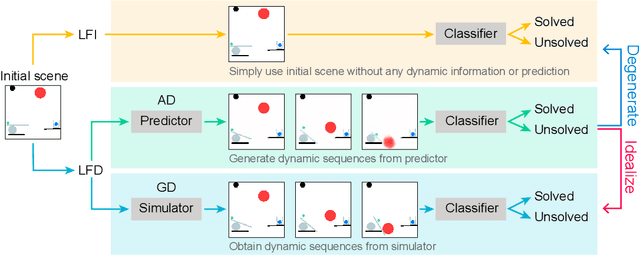

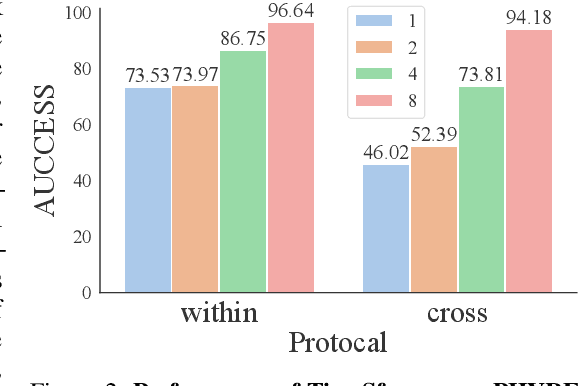
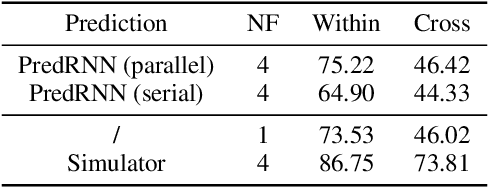
Is dynamics prediction indispensable for physical reasoning? If so, what kind of roles do the dynamics prediction modules play during the physical reasoning process? Most studies focus on designing dynamics prediction networks and treating physical reasoning as a downstream task without investigating the questions above, taking for granted that the designed dynamics prediction would undoubtedly help the reasoning process. In this work, we take a closer look at this assumption, exploring this fundamental hypothesis by comparing two learning mechanisms: Learning from Dynamics (LfD) and Learning from Intuition (LfI). In the first experiment, we directly examine and compare these two mechanisms. Results show a surprising finding: Simple LfI is better than or on par with state-of-the-art LfD. This observation leads to the second experiment with Ground-truth Dynamics, the ideal case of LfD wherein dynamics are obtained directly from a simulator. Results show that dynamics, if directly given instead of approximated, would achieve much higher performance than LfI alone on physical reasoning; this essentially serves as the performance upper bound. Yet practically, LfD mechanism can only predict Approximate Dynamics using dynamics learning modules that mimic the physical laws, making the following downstream physical reasoning modules degenerate into the LfI paradigm; see the third experiment. We note that this issue is hard to mitigate, as dynamics prediction errors inevitably accumulate in the long horizon. Finally, in the fourth experiment, we note that LfI, the extremely simpler strategy when done right, is more effective in learning to solve physical reasoning problems. Taken together, the results on the challenging benchmark of PHYRE show that LfI is, if not better, as good as LfD for dynamics prediction. However, the potential improvement from LfD, though challenging, remains lucrative.