 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIDME: Self-supervised Image Demoiréing via Masked Encoder-Decoder Reconstruction
Apr 16, 2025Moir\'e patterns, resulting from aliasing between object light signals and camera sampling frequencies, often degrade image quality during capture. Traditional demoir\'eing methods have generally treated images as a whole for processing and training, neglecting the unique signal characteristics of different color channels. Moreover, the randomness and variability of moir\'e pattern generation pose challenges to the robustness of existing methods when applied to real-world data. To address these issues, this paper presents SIDME (Self-supervised Image Demoir\'eing via Masked Encoder-Decoder Reconstruction), a novel model designed to generate high-quality visual images by effectively processing moir\'e patterns. SIDME combines a masked encoder-decoder architecture with self-supervised learning, allowing the model to reconstruct images using the inherent properties of camera sampling frequencies. A key innovation is the random masked image reconstructor, which utilizes an encoder-decoder structure to handle the reconstruction task. Furthermore, since the green channel in camera sampling has a higher sampling frequency compared to red and blue channels, a specialized self-supervised loss function is designed to improve the training efficiency and effectiveness. To ensure the generalization ability of the model, a self-supervised moir\'e image generation method has been developed to produce a dataset that closely mimics real-world conditions. Extensive experiments demonstrate that SIDME outperforms existing methods in processing real moir\'e pattern data, showing its superior generalization performance and robustness.
Consistent Diffusion: Denoising Diffusion Model with Data-Consistent Training for Image Restoration
Dec 17, 2024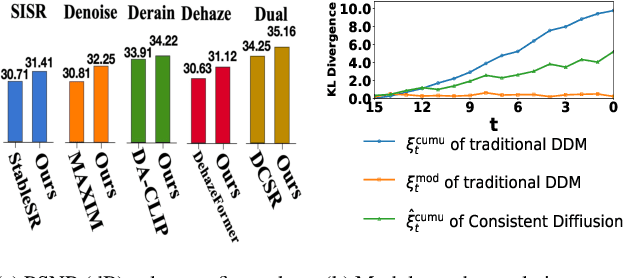
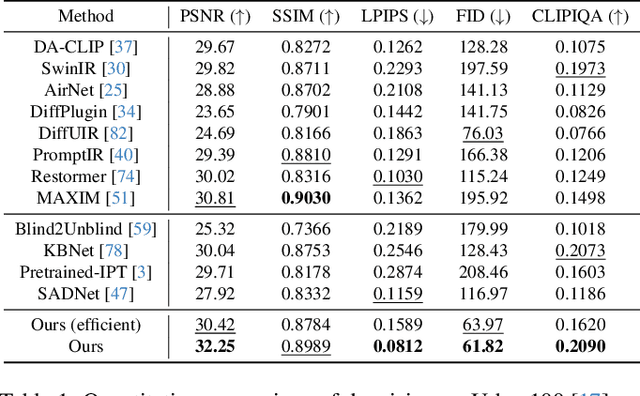


In this work, we address the limitations of denoising diffusion models (DDMs) in image restoration tasks, particularly the shape and color distortions that can compromise image quality. While DDMs have demonstrated a promising performance in many applications such as text-to-image synthesis, their effectiveness in image restoration is often hindered by shape and color distortions. We observe that these issues arise from inconsistencies between the training and testing data used by DDMs. Based on our observation, we propose a novel training method, named data-consistent training, which allows the DDMs to access images with accumulated errors during training, thereby ensuring the model to learn to correct these errors. Experimental results show that, across five image restoration tasks, our method has significant improvements over state-of-the-art methods while effectively minimizing distortions and preserving image fidelity.
ReWiTe: Realistic Wide-angle and Telephoto Dual Camera Fusion Dataset via Beam Splitter Camera Rig
Apr 16, 2024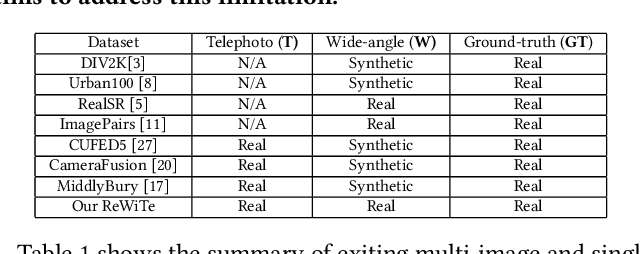
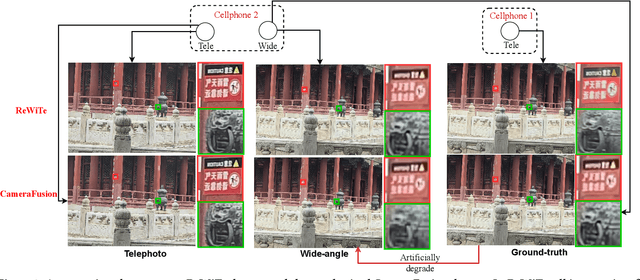
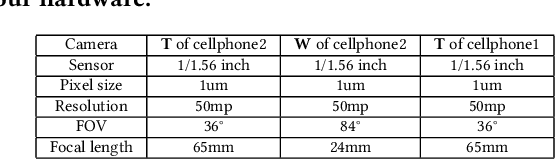

The fusion of images from dual camera systems featuring a wide-angle and a telephoto camera has become a hotspot problem recently. By integrating simultaneously captured wide-angle and telephoto images from these systems, the resulting fused image achieves a wide field of view (FOV) coupled with high-definition quality. Existing approaches are mostly deep learning methods, and predominantly rely on supervised learning, where the training dataset plays a pivotal role. However, current datasets typically adopt a data synthesis approach generate input pairs of wide-angle and telephoto images alongside ground-truth images. Notably, the wide-angle inputs are synthesized rather than captured using real wide-angle cameras, and the ground-truth image is captured by wide-angle camera whose quality is substantially lower than that of input telephoto images captured by telephoto cameras. To address these limitations, we introduce a novel hardware setup utilizing a beam splitter to simultaneously capture three images, i.e. input pairs and ground-truth images, from two authentic cellphones equipped with wide-angle and telephoto dual cameras. Specifically, the wide-angle and telephoto images captured by cellphone 2 serve as the input pair, while the telephoto image captured by cellphone 1, which is calibrated to match the optical path of the wide-angle image from cellphone 2, serves as the ground-truth image, maintaining quality on par with the input telephoto image. Experiments validate the efficacy of our newly introduced dataset, named ReWiTe, significantly enhances the performance of various existing methods for real-world wide-angle and telephoto dual image fusion tasks.
View Transition based Dual Camera Image Fusion
Dec 18, 2023The dual camera system of wide-angle ($\bf{W}$) and telephoto ($\bf{T}$) cameras has been widely adopted by popular phones. In the overlap region, fusing the $\bf{W}$ and $\bf{T}$ images can generate a higher quality image. Related works perform pixel-level motion alignment or high-dimensional feature alignment of the $\bf{T}$ image to the view of the $\bf{W}$ image and then perform image/feature fusion, but the enhancement in occlusion area is ill-posed and can hardly utilize data from $\bf{T}$ images. Our insight is to minimize the occlusion area and thus maximize the use of pixels from $\bf{T}$ images. Instead of insisting on placing the output in the $\bf{W}$ view, we propose a view transition method to transform both $\bf{W}$ and $\bf{T}$ images into a mixed view and then blend them into the output. The transformation ratio is kept small and not apparent to users, and the center area of the output, which has accumulated a sufficient amount of transformation, can directly use the contents from the T view to minimize occlusions. Experimental results show that, in comparison with the SOTA methods, occlusion area is largely reduced by our method and thus more pixels of the $\bf{T}$ image can be used for improving the quality of the output image.