 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Guided Human Parsing with Deep Learned Features
Paper and Code
Nov 25, 2015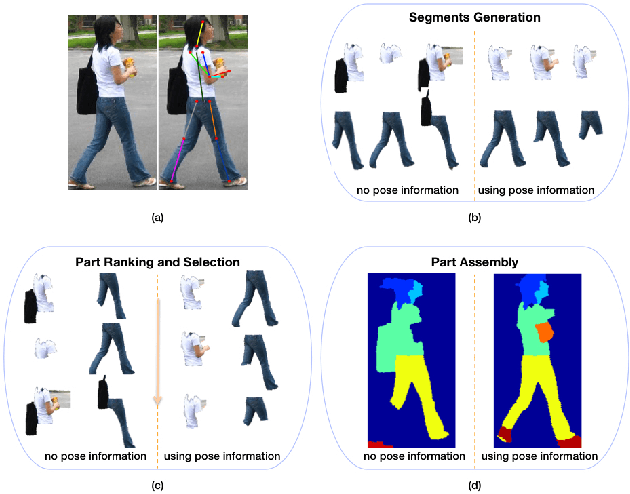

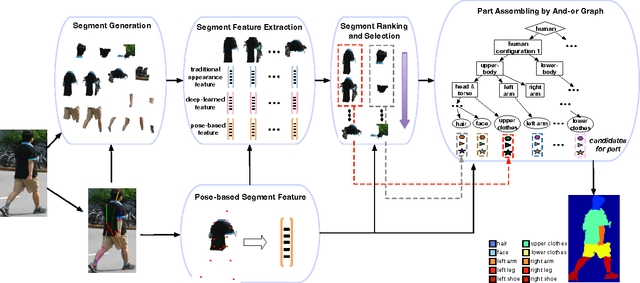

Parsing human body into semantic regions is crucial to human-centric analysis. In this paper, we propose a segment-based parsing pipeline that explores human pose information, i.e. the joint location of a human model, which improves the part proposal, accelerates the inference and regularizes the parsing process at the same time. Specifically, we first generate part segment proposals with respect to human joints predicted by a deep model, then part- specific ranking models are trained for segment selection using both pose-based features and deep-learned part potential features. Finally, the best ensemble of the proposed part segments are inferred though an And-Or Graph. We evaluate our approach on the popular Penn-Fudan pedestrian parsing dataset, and demonstrate the effectiveness of using the pose information for each stage of the parsing pipeline. Finally, we show that our approach yields superior part segmentation accuracy comparing to the state-of-the-art methods.