 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAViAR: Critic-Augmented Video Agentic Reasoning
Sep 09, 2025Video understanding has seen significant progress in recent years, with models' performance on perception from short clips continuing to rise. Yet, multiple recent benchmarks, such as LVBench, Neptune, and ActivityNet-RTL, show performance wanes for tasks requiring complex reasoning on videos as queries grow more complex and videos grow longer. In this work, we ask: can existing perception capabilities be leveraged to successfully perform more complex video reasoning? In particular, we develop a large language model agent given access to video modules as subagents or tools. Rather than following a fixed procedure to solve queries as in previous work such as Visual Programming, ViperGPT, and MoReVQA, the agent uses the results of each call to a module to determine subsequent steps. Inspired by work in the textual reasoning domain, we introduce a critic to distinguish between instances of successful and unsuccessful sequences from the agent. We show that the combination of our agent and critic achieve strong performance on the previously-mentioned datasets.
MINERVA: Evaluating Complex Video Reasoning
May 01, 2025Multimodal LLMs are turning their focus to video benchmarks, however most video benchmarks only provide outcome supervision, with no intermediate or interpretable reasoning steps. This makes it challenging to assess if models are truly able to combine perceptual and temporal information to reason about videos, or simply get the correct answer by chance or by exploiting linguistic biases. To remedy this, we provide a new video reasoning dataset called MINERVA for modern multimodal models. Each question in the dataset comes with 5 answer choices, as well as detailed, hand-crafted reasoning traces. Our dataset is multimodal, diverse in terms of video domain and length, and consists of complex multi-step questions. Extensive benchmarking shows that our dataset provides a challenge for frontier open-source and proprietary models. We perform fine-grained error analysis to identify common failure modes across various models, and create a taxonomy of reasoning errors. We use this to explore both human and LLM-as-a-judge methods for scoring video reasoning traces, and find that failure modes are primarily related to temporal localization, followed by visual perception errors, as opposed to logical or completeness errors. The dataset, along with questions, answer candidates and reasoning traces will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva.
Whiteboard-of-Thought: Thinking Step-by-Step Across Modalities
Jun 20, 2024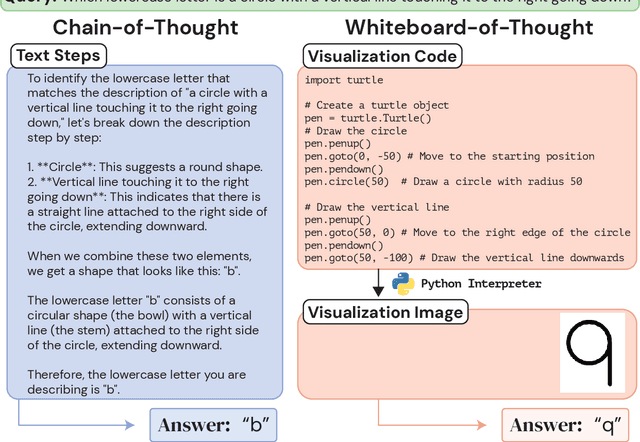
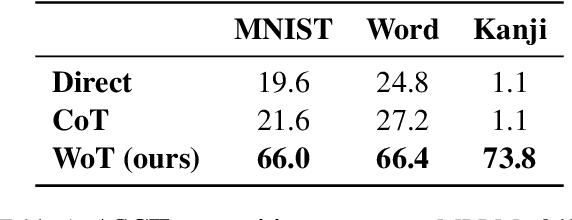

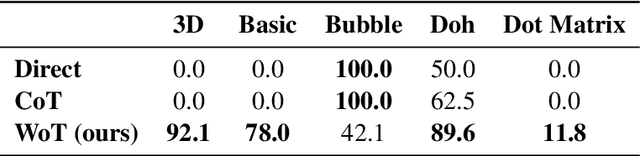
When presented with questions involving visual thinking, humans naturally switch reasoning modalities, often forming mental images or drawing visual aids. Large language models have shown promising results in arithmetic and symbolic reasoning by expressing intermediate reasoning in text as a chain of thought, yet struggle to extend this capability to answer text queries that are easily solved by visual reasoning, even with extensive multimodal pretraining. We introduce a simple method, whiteboard-of-thought prompting, to unlock the visual reasoning capabilities of multimodal large language models across modalities. Whiteboard-of-thought prompting provides multimodal large language models with a metaphorical `whiteboard' to draw out reasoning steps as images, then returns these images back to the model for further processing. We find this can be accomplished with no demonstrations or specialized modules, instead leveraging models' existing ability to write code with libraries such as Matplotlib and Turtle. This simple approach shows state-of-the-art results on four difficult natural language tasks that involve visual and spatial reasoning. We identify multiple settings where GPT-4o using chain-of-thought fails dramatically, including more than one where it achieves $0\%$ accuracy, while whiteboard-of-thought enables up to $92\%$ accuracy in these same settings. We present a detailed exploration of where the technique succeeds as well as its sources of error.
Generating Illustrated Instructions
Dec 07, 2023



We introduce the new task of generating Illustrated Instructions, i.e., visual instructions customized to a user's needs. We identify desiderata unique to this task, and formalize it through a suite of automatic and human evaluation metrics, designed to measure the validity, consistency, and efficacy of the generations. We combine the power of large language models (LLMs) together with strong text-to-image generation diffusion models to propose a simple approach called StackedDiffusion, which generates such illustrated instructions given text as input. The resulting model strongly outperforms baseline approaches and state-of-the-art multimodal LLMs; and in 30% of cases, users even prefer it to human-generated articles. Most notably, it enables various new and exciting applications far beyond what static articles on the web can provide, such as personalized instructions complete with intermediate steps and pictures in response to a user's individual situation.
ViperGPT: Visual Inference via Python Execution for Reasoning
Mar 14, 2023
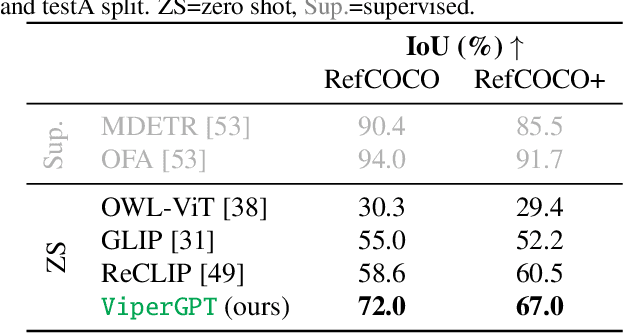
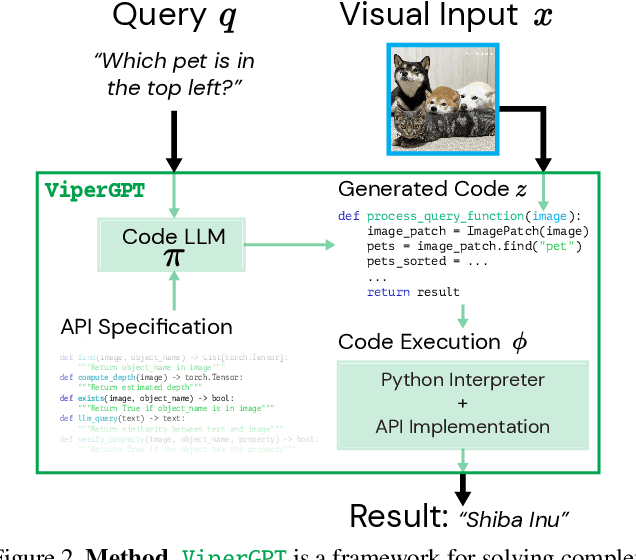

Answering visual queries is a complex task that requires both visual processing and reasoning. End-to-end models, the dominant approach for this task, do not explicitly differentiate between the two, limiting interpretability and generalization. Learning modular programs presents a promising alternative, but has proven challenging due to the difficulty of learning both the programs and modules simultaneously. We introduce ViperGPT, a framework that leverages code-generation models to compose vision-and-language models into subroutines to produce a result for any query. ViperGPT utilizes a provided API to access the available modules, and composes them by generating Python code that is later executed. This simple approach requires no further training, and achieves state-of-the-art results across various complex visual tasks.
Affective Faces for Goal-Driven Dyadic Communication
Jan 26, 2023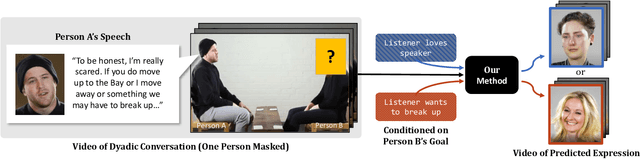
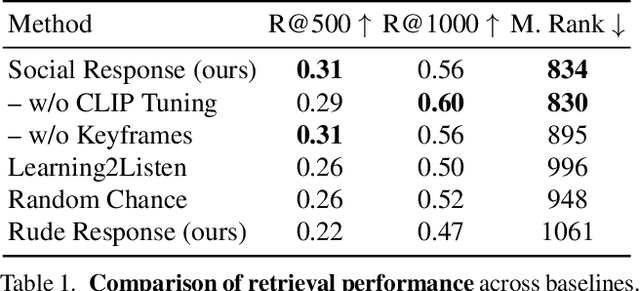
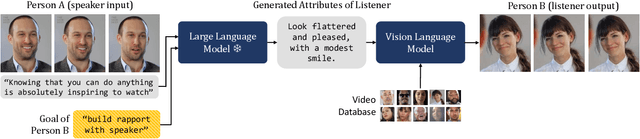

We introduce a video framework for modeling the association between verbal and non-verbal communication during dyadic conversation. Given the input speech of a speaker, our approach retrieves a video of a listener, who has facial expressions that would be socially appropriate given the context. Our approach further allows the listener to be conditioned on their own goals, personalities, or backgrounds. Our approach models conversations through a composition of large language models and vision-language models, creating internal representations that are interpretable and controllable. To study multimodal communication, we propose a new video dataset of unscripted conversations covering diverse topics and demographics. Experiments and visualizations show our approach is able to output listeners that are significantly more socially appropriate than baselines. However, many challenges remain, and we release our dataset publicly to spur further progress. See our website for video results, data, and code: https://realtalk.cs.columbia.edu.
Doubly Right Object Recognition: A Why Prompt for Visual Rationales
Dec 12, 2022Many visual recognition models are evaluated only on their classification accuracy, a metric for which they obtain strong performance. In this paper, we investigate whether computer vision models can also provide correct rationales for their predictions. We propose a ``doubly right'' object recognition benchmark, where the metric requires the model to simultaneously produce both the right labels as well as the right rationales. We find that state-of-the-art visual models, such as CLIP, often provide incorrect rationales for their categorical predictions. However, by transferring the rationales from language models into visual representations through a tailored dataset, we show that we can learn a ``why prompt,'' which adapts large visual representations to produce correct rationales. Visualizations and empirical experiments show that our prompts significantly improve performance on doubly right object recognition, in addition to zero-shot transfer to unseen tasks and datasets.
Task Bias in Vision-Language Models
Dec 08, 2022



Incidental supervision from language has become a popular approach for learning generic visual representations that can be prompted to perform many recognition tasks in computer vision. We conduct an in-depth exploration of the CLIP model and show that its visual representation is often strongly biased towards solving some tasks more than others. Moreover, which task the representation will be biased towards is unpredictable, with little consistency across images. To resolve this task bias, we show how to learn a visual prompt that guides the representation towards features relevant to their task of interest. Our results show that these visual prompts can be independent of the input image and still effectively provide a conditioning mechanism to steer visual representations towards the desired task.
Visual Classification via Description from Large Language Models
Oct 13, 2022



Vision-language models (VLMs) such as CLIP have shown promising performance on a variety of recognition tasks using the standard zero-shot classification procedure -- computing similarity between the query image and the embedded words for each category. By only using the category name, they neglect to make use of the rich context of additional information that language affords. The procedure gives no intermediate understanding of why a category is chosen, and furthermore provides no mechanism for adjusting the criteria used towards this decision. We present an alternative framework for classification with VLMs, which we call classification by description. We ask VLMs to check for descriptive features rather than broad categories: to find a tiger, look for its stripes; its claws; and more. By basing decisions on these descriptors, we can provide additional cues that encourage using the features we want to be used. In the process, we can get a clear idea of what features the model uses to construct its decision; it gains some level of inherent explainability. We query large language models (e.g., GPT-3) for these descriptors to obtain them in a scalable way. Extensive experiments show our framework has numerous advantages past interpretability. We show improvements in accuracy on ImageNet across distribution shifts; demonstrate the ability to adapt VLMs to recognize concepts unseen during training; and illustrate how descriptors can be edited to effectively mitigate bias compared to the baseline.
Forget-me-not! Contrastive Critics for Mitigating Posterior Collapse
Jul 19, 2022
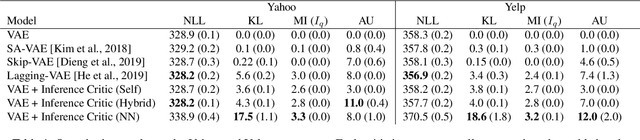


Variational autoencoders (VAEs) suffer from posterior collapse, where the powerful neural networks used for modeling and inference optimize the objective without meaningfully using the latent representation. We introduce inference critics that detect and incentivize against posterior collapse by requiring correspondence between latent variables and the observations. By connecting the critic's objective to the literature in self-supervised contrastive representation learning, we show both theoretically and empirically that optimizing inference critics increases the mutual information between observations and latents, mitigating posterior collapse. This approach is straightforward to implement and requires significantly less training time than prior methods, yet obtains competitive results on three established datasets. Overall, the approach lays the foundation to bridge the previously disconnected frameworks of contrastive learning and probabilistic modeling with variational autoencoders, underscoring the benefits both communities may find at their intersection.