 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Knowledge State of Online Students -- New Data, New Approaches, Improved Accuracy
Sep 04, 2021
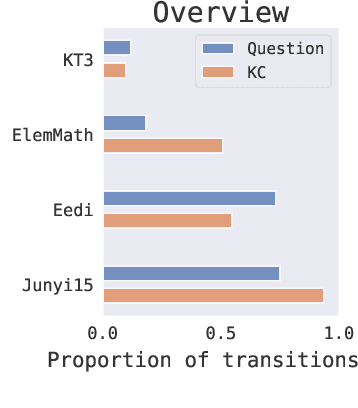
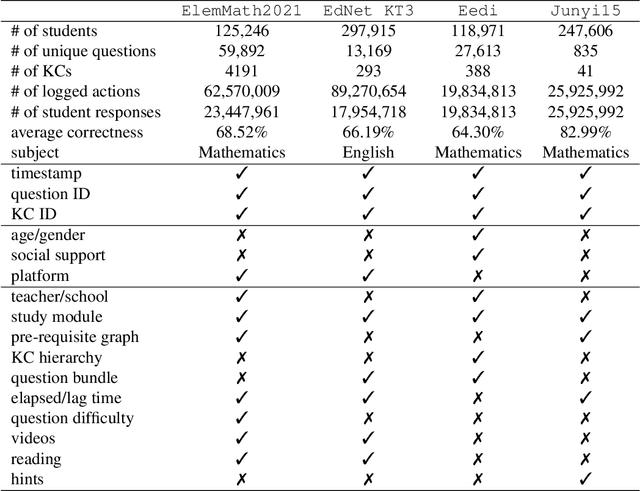
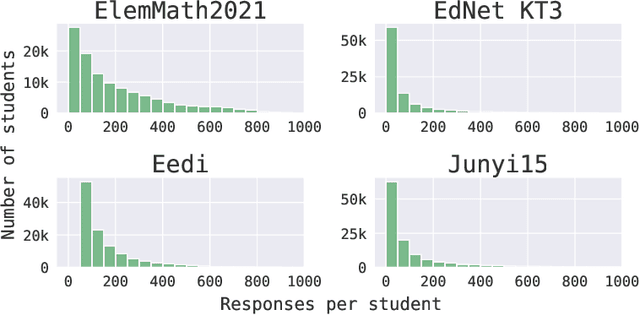
We consider the problem of assessing the changing knowledge state of individual students as they go through online courses. This student performance (SP) modeling problem, also known as knowledge tracing, is a critical step for building adaptive online teaching systems. Specifically, we conduct a study of how to utilize various types and large amounts of students log data to train accurate machine learning models that predict the knowledge state of future students. This study is the first to use four very large datasets made available recently from four distinct intelligent tutoring systems. Our results include a new machine learning approach that defines a new state of the art for SP modeling, improving over earlier methods in several ways: First, we achieve improved accuracy by introducing new features that can be easily computed from conventional question-response logs (e.g., the pattern in the student's most recent answers). Second, we take advantage of features of the student history that go beyond question-response pairs (e.g., which video segments the student watched, or skipped) as well as information about prerequisite structure in the curriculum. Third, we train multiple specialized modeling models for different aspects of the curriculum (e.g., specializing in early versus later segments of the student history), then combine these specialized models to create a group prediction of student knowledge. Taken together, these innovations yield an average AUC score across these four datasets of 0.807 compared to the previous best logistic regression approach score of 0.766, and also outperforming state-of-the-art deep neural net approaches. Importantly, we observe consistent improvements from each of our three methodological innovations, in each dataset, suggesting that our methods are of general utility and likely to produce improvements for other online tutoring systems as well.
PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models
Mar 08, 2020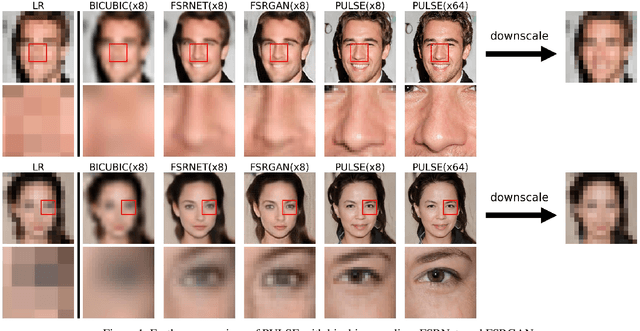
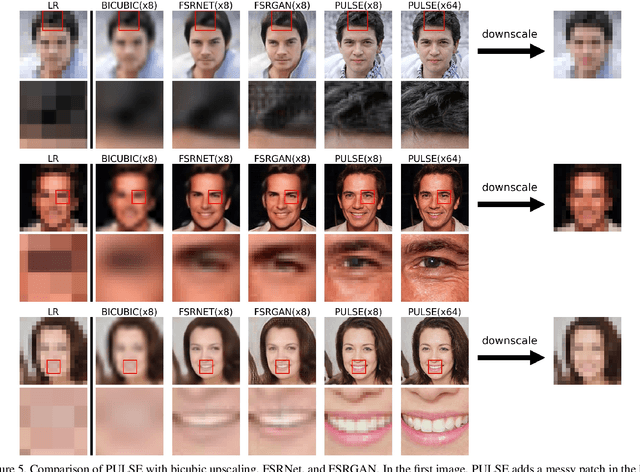


The primary aim of single-image super-resolution is to construct a high-resolution (HR) image from a corresponding low-resolution (LR) input. In previous approaches, which have generally been supervised, the training objective typically measures a pixel-wise average distance between the super-resolved (SR) and HR images. Optimizing such metrics often leads to blurring, especially in high variance (detailed) regions. We propose an alternative formulation of the super-resolution problem based on creating realistic SR images that downscale correctly. We present a novel super-resolution algorithm addressing this problem, PULSE (Photo Upsampling via Latent Space Exploration), which generates high-resolution, realistic images at resolutions previously unseen in the literature. It accomplishes this in an entirely self-supervised fashion and is not confined to a specific degradation operator used during training, unlike previous methods (which require training on databases of LR-HR image pairs for supervised learning). Instead of starting with the LR image and slowly adding detail, PULSE traverses the high-resolution natural image manifold, searching for images that downscale to the original LR image. This is formalized through the "downscaling loss," which guides exploration through the latent space of a generative model. By leveraging properties of high-dimensional Gaussians, we restrict the search space to guarantee that our outputs are realistic. PULSE thereby generates super-resolved images that both are realistic and downscale correctly. We show extensive experimental results demonstrating the efficacy of our approach in the domain of face super-resolution (also known as face hallucination). Our method outperforms state-of-the-art methods in perceptual quality at higher resolutions and scale factors than previously possible.
New Techniques for Preserving Global Structure and Denoising with Low Information Loss in Single-Image Super-Resolution
Jun 16, 2018
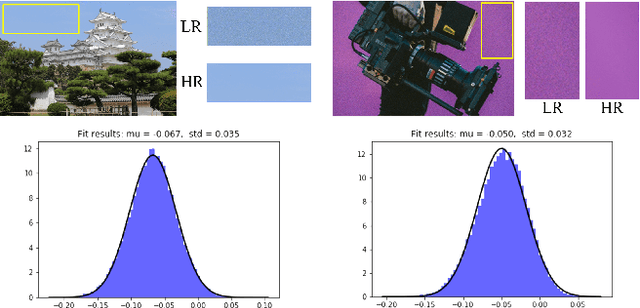
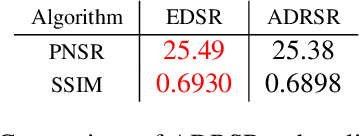
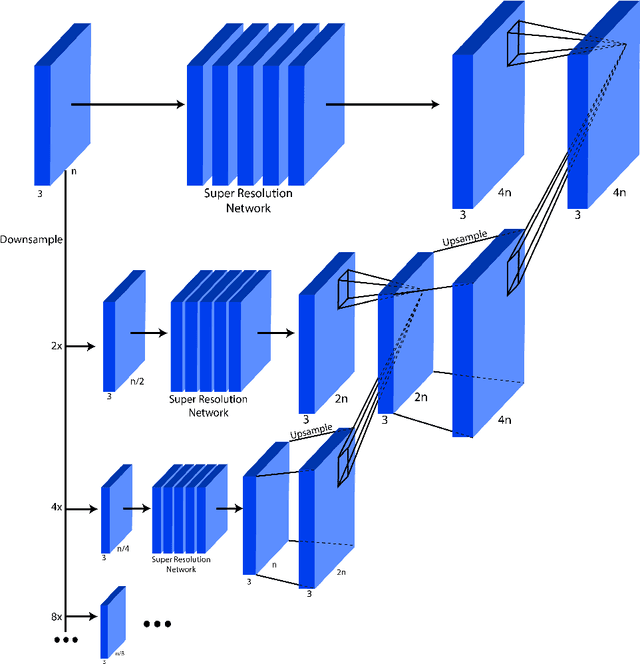
This work identifies and addresses two important technical challenges in single-image super-resolution: (1) how to upsample an image without magnifying noise and (2) how to preserve large scale structure when upsampling. We summarize the techniques we developed for our second place entry in Track 1 (Bicubic Downsampling), seventh place entry in Track 2 (Realistic Adverse Conditions), and seventh place entry in Track 3 (Realistic difficult) in the 2018 NTIRE Super-Resolution Challenge. Furthermore, we present new neural network architectures that specifically address the two challenges listed above: denoising and preservation of large-scale structure.