 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFireBench: Evaluating Instruction Following in Enterprise and API-Driven LLM Applications
Mar 05, 2026Instruction following is critical for LLMs deployed in enterprise and API-driven settings, where strict adherence to output formats, content constraints, and procedural requirements is essential for enabling reliable LLM-assisted workflows. However, existing instruction following benchmarks predominantly evaluate natural language generation constraints that reflect the needs of chat assistants rather than enterprise users. To bridge this gap, we introduce FireBench, an LLM instruction following benchmark grounded in real-world enterprise and API usage patterns. FireBench evaluates six core capability dimensions across diverse applications including information extraction, customer support, and coding agents, comprising over 2,400 samples. We evaluate 11 LLMs and present key findings on their instruction following behavior in enterprise scenarios. We open-source FireBench at fire-bench.com to help users assess model suitability, support model developers in diagnosing performance, and invite community contributions.
Concept Whitening for Interpretable Image Recognition
Feb 05, 2020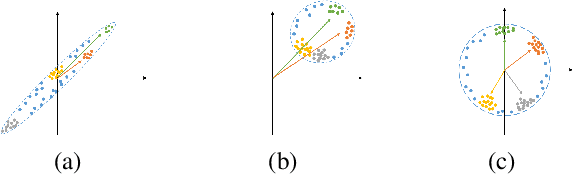
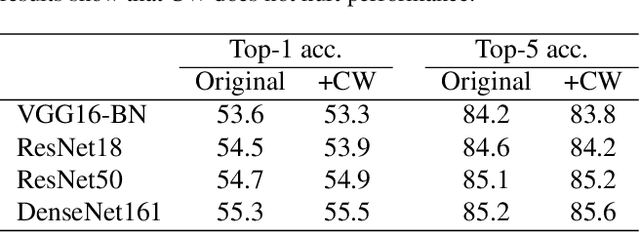

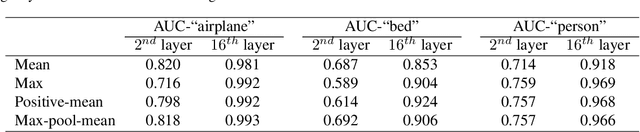
What does a neural network encode about a concept as we traverse through the layers? Interpretability in machine learning is undoubtedly important, but the calculations of neural networks are very challenging to understand. Attempts to see inside their hidden layers can either be misleading, unusable, or rely on the latent space to possess properties that it may not have. In this work, rather than attempting to analyze a neural network posthoc, we introduce a mechanism, called concept whitening (CW), to alter a given layer of the network to allow us to better understand the computation leading up to that layer. When a concept whitening module is added to a CNN, the axes of the latent space can be aligned with concepts of interest. By experiment, we show that CW can provide us a much clearer understanding for how the network gradually learns concepts over layers without hurting predictive performance.
New Techniques for Preserving Global Structure and Denoising with Low Information Loss in Single-Image Super-Resolution
Jun 16, 2018
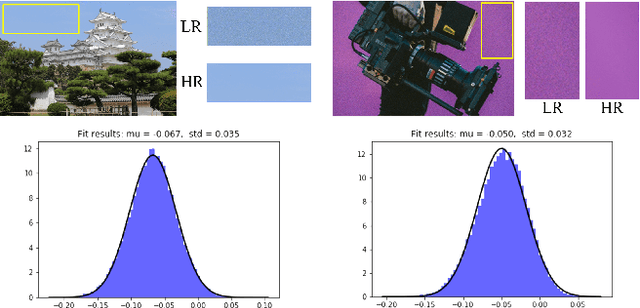
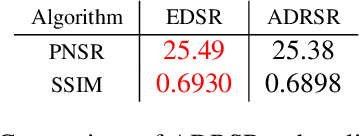
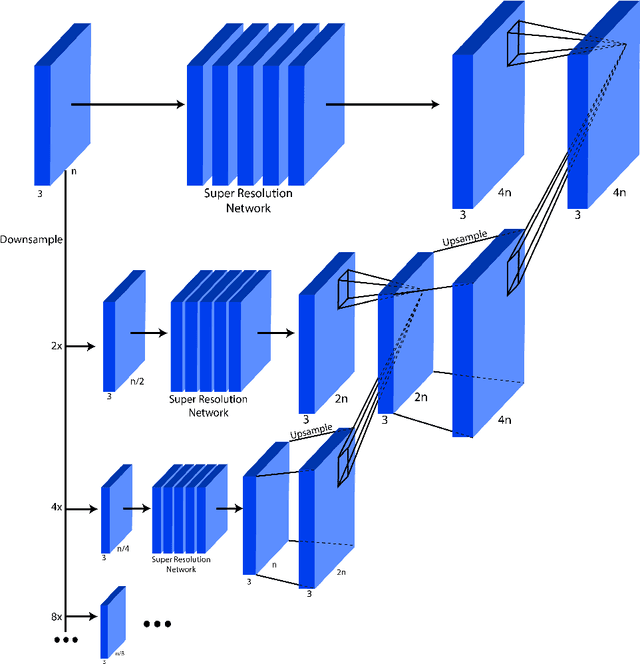
This work identifies and addresses two important technical challenges in single-image super-resolution: (1) how to upsample an image without magnifying noise and (2) how to preserve large scale structure when upsampling. We summarize the techniques we developed for our second place entry in Track 1 (Bicubic Downsampling), seventh place entry in Track 2 (Realistic Adverse Conditions), and seventh place entry in Track 3 (Realistic difficult) in the 2018 NTIRE Super-Resolution Challenge. Furthermore, we present new neural network architectures that specifically address the two challenges listed above: denoising and preservation of large-scale structure.