 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Large Scale Inlier Voting for Geometric Vision Problems
Jul 27, 2021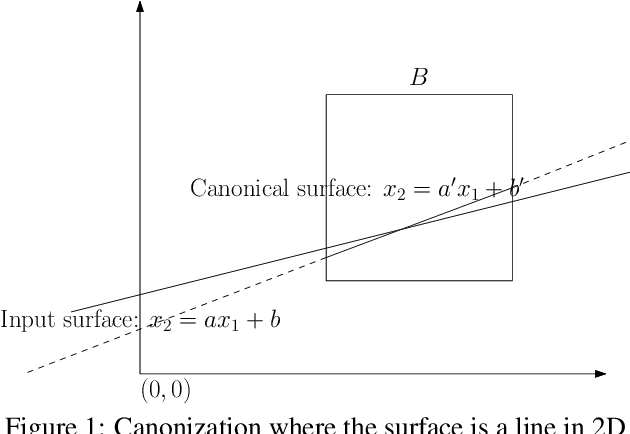



Outlier rejection and equivalently inlier set optimization is a key ingredient in numerous applications in computer vision such as filtering point-matches in camera pose estimation or plane and normal estimation in point clouds. Several approaches exist, yet at large scale we face a combinatorial explosion of possible solutions and state-of-the-art methods like RANSAC, Hough transform or Branch&Bound require a minimum inlier ratio or prior knowledge to remain practical. In fact, for problems such as camera posing in very large scenes these approaches become useless as they have exponential runtime growth if these conditions aren't met. To approach the problem we present a efficient and general algorithm for outlier rejection based on "intersecting" $k$-dimensional surfaces in $R^d$. We provide a recipe for casting a variety of geometric problems as finding a point in $R^d$ which maximizes the number of nearby surfaces (and thus inliers). The resulting algorithm has linear worst-case complexity with a better runtime dependency in the approximation factor than competing algorithms while not requiring domain specific bounds. This is achieved by introducing a space decomposition scheme that bounds the number of computations by successively rounding and grouping samples. Our recipe (and open-source code) enables anybody to derive such fast approaches to new problems across a wide range of domains. We demonstrate the versatility of the approach on several camera posing problems with a high number of matches at low inlier ratio achieving state-of-the-art results at significantly lower processing times.
Large-scale, real-time visual-inertial localization revisited
Jun 30, 2019



The overarching goals in image-based localization are scale, robustness and speed. In recent years, approaches based on local features and sparse 3D point-cloud models have both dominated the benchmarks and seen successful realworld deployment. They enable applications ranging from robot navigation, autonomous driving, virtual and augmented reality to device geo-localization. Recently end-to-end learned localization approaches have been proposed which show promising results on small scale datasets. However the positioning accuracy, scalability, latency and compute & storage requirements of these approaches remain open challenges. We aim to deploy localization at global-scale where one thus relies on methods using local features and sparse 3D models. Our approach spans from offline model building to real-time client-side pose fusion. The system compresses appearance and geometry of the scene for efficient model storage and lookup leading to scalability beyond what what has been previously demonstrated. It allows for low-latency localization queries and efficient fusion run in real-time on mobile platforms by combining server-side localization with real-time visual-inertial-based camera pose tracking. In order to further improve efficiency we leverage a combination of priors, nearest neighbor search, geometric match culling and a cascaded pose candidate refinement step. This combination outperforms previous approaches when working with large scale models and allows deployment at unprecedented scale. We demonstrate the effectiveness of our approach on a proof-of-concept system localizing 2.5 million images against models from four cities in different regions on the world achieving query latencies in the 200ms range.
LandmarkBoost: Efficient Visual Context Classifiers for Robust Localization
Jul 13, 2018



The growing popularity of autonomous systems creates a need for reliable and efficient metric pose retrieval algorithms. Currently used approaches tend to rely on nearest neighbor search of binary descriptors to perform the 2D-3D matching and guarantee realtime capabilities on mobile platforms. These methods struggle, however, with the growing size of the map, changes in viewpoint or appearance, and visual aliasing present in the environment. The rigidly defined descriptor patterns only capture a limited neighborhood of the keypoint and completely ignore the overall visual context. We propose LandmarkBoost - an approach that, in contrast to the conventional 2D-3D matching methods, casts the search problem as a landmark classification task. We use a boosted classifier to classify landmark observations and directly obtain correspondences as classifier scores. We also introduce a formulation of visual context that is flexible, efficient to compute, and can capture relationships in the entire image plane. The original binary descriptors are augmented with contextual information and informative features are selected by the boosting framework. Through detailed experiments, we evaluate the retrieval quality and performance of LandmarkBoost, demonstrating that it outperforms common state-of-the-art descriptor matching methods.