 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatFormer: Nested Transformer for Elastic Inference
Oct 11, 2023



Transformer models are deployed in a wide range of settings, from multi-accelerator clusters to standalone mobile phones. The diverse inference constraints in these scenarios necessitate practitioners to train foundation models such as PaLM 2, Llama, & ViTs as a series of models of varying sizes. Due to significant training costs, only a select few model sizes are trained and supported, limiting more fine-grained control over relevant tradeoffs, including latency, cost, and accuracy. This work introduces MatFormer, a nested Transformer architecture designed to offer elasticity in a variety of deployment constraints. Each Feed Forward Network (FFN) block of a MatFormer model is jointly optimized with a few nested smaller FFN blocks. This training procedure allows for the Mix'n'Match of model granularities across layers -- i.e., a trained universal MatFormer model enables extraction of hundreds of accurate smaller models, which were never explicitly optimized. We empirically demonstrate MatFormer's effectiveness across different model classes (decoders & encoders), modalities (language & vision), and scales (up to 2.6B parameters). We find that a 2.6B decoder-only MatFormer language model (MatLM) allows us to extract smaller models spanning from 1.5B to 2.6B, each exhibiting comparable validation loss and one-shot downstream evaluations to their independently trained counterparts. Furthermore, we observe that smaller encoders extracted from a universal MatFormer-based ViT (MatViT) encoder preserve the metric-space structure for adaptive large-scale retrieval. Finally, we showcase that speculative decoding with the accurate and consistent submodels extracted from MatFormer can further reduce inference latency.
Greedy Pruning with Group Lasso Provably Generalizes for Matrix Sensing and Neural Networks with Quadratic Activations
Mar 20, 2023Pruning schemes have been widely used in practice to reduce the complexity of trained models with a massive number of parameters. Several practical studies have shown that pruning an overparameterized model and fine-tuning generalizes well to new samples. Although the above pipeline, which we refer to as pruning + fine-tuning, has been extremely successful in lowering the complexity of trained models, there is very little known about the theory behind this success. In this paper we address this issue by investigating the pruning + fine-tuning framework on the overparameterized matrix sensing problem, with the ground truth denoted $U_\star \in \mathbb{R}^{d \times r}$ and the overparameterized model $U \in \mathbb{R}^{d \times k}$ with $k \gg r$. We study the approximate local minima of the empirical mean square error, augmented with a smooth version of a group Lasso regularizer, $\sum_{i=1}^k \| U e_i \|_2$ and show that pruning the low $\ell_2$-norm columns results in a solution $U_{\text{prune}}$ which has the minimum number of columns $r$, yet is close to the ground truth in training loss. Initializing the subsequent fine-tuning phase from $U_{\text{prune}}$, the resulting solution converges linearly to a generalization error of $O(\sqrt{rd/n})$ ignoring lower order terms, which is statistically optimal. While our analysis provides insights into the role of regularization in pruning, we also show that running gradient descent in the absence of regularization results in models which {are not suitable for greedy pruning}, i.e., many columns could have their $\ell_2$ norm comparable to that of the maximum. Lastly, we extend our results for the training and pruning of two-layer neural networks with quadratic activation functions. Our results provide the first rigorous insights on why greedy pruning + fine-tuning leads to smaller models which also generalize well.
Voting based ensemble improves robustness of defensive models
Nov 28, 2020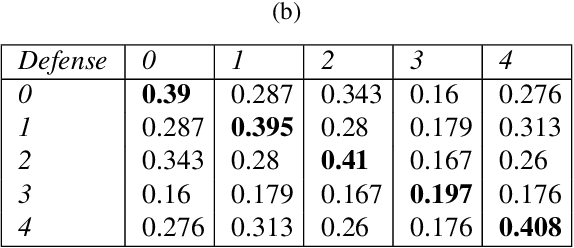

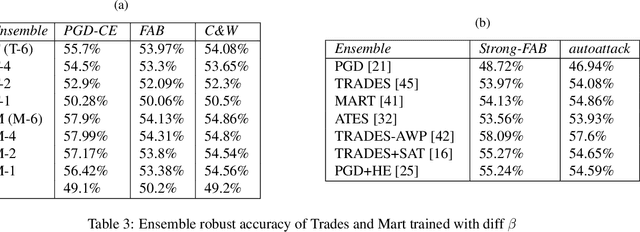
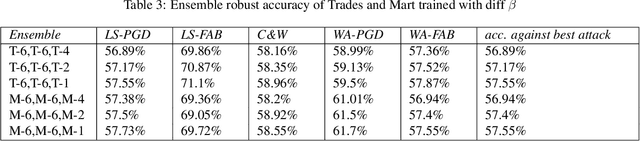
Developing robust models against adversarial perturbations has been an active area of research and many algorithms have been proposed to train individual robust models. Taking these pretrained robust models, we aim to study whether it is possible to create an ensemble to further improve robustness. Several previous attempts tackled this problem by ensembling the soft-label prediction and have been proved vulnerable based on the latest attack methods. In this paper, we show that if the robust training loss is diverse enough, a simple hard-label based voting ensemble can boost the robust error over each individual model. Furthermore, given a pool of robust models, we develop a principled way to select which models to ensemble. Finally, to verify the improved robustness, we conduct extensive experiments to study how to attack a voting-based ensemble and develop several new white-box attacks. On CIFAR-10 dataset, by ensembling several state-of-the-art pre-trained defense models, our method can achieve a 59.8% robust accuracy, outperforming all the existing defensive models without using additional data.